Auteur : MOKEMI TCHAKOUTE BAUTREL Duval
Date : Mars 2026
DocuChat-RAG est un assistant conversationnel intelligent basé sur la génération augmentée par la recherche (RAG), conçu pour répondre aux questions en utilisant exclusivement vos documents personnels. Contrairement aux chatbots généralistes qui peuvent produire des réponses erronées ou spéculatives, cet assistant est contraint de répondre uniquement à partir des documents indexés, ce qui le rend parfaitement adapté aux applications spécifiques à un domaine ou soumises à des exigences de conformité.
Le système renforce la fiabilité grâce à :
Les utilisateurs peuvent interagir avec le chatbot via une interface de ligne de commande (CLI) simple et intuitive.
Cette publication fournit des instructions complètes sur l'architecture, le fonctionnement et la gestion du système de chatbot basé sur RAG. Elle détaille tous les composants essentiels :
Outre la description de l'architecture, ce document inclut des instructions pour exécuter l'application, les options de configuration et un jeu de données de test pour valider le comportement du système. Il présente également les limites actuelles et les axes d'amélioration futurs.
L'ensemble de données utilisé pour cette application est une collection de 7 documents textuels soigneusement sélectionnés, couvrant des thématiques variées et actuelles :
| Fichier | Thématique | Contenu principal |
|---|---|---|
artificial_intelligence.txt | Intelligence Artificielle | Principes de l'IA, Machine Learning, Deep Learning, NLP, Éthique de l'IA |
biotechnology.txt | Biotechnologie | CRISPR, Biologie synthétique, Médecine personnalisée, Médecine régénérative, Bioéthique |
climate_science.txt | Sciences du Climat | Changement climatique, Effet de serre, Impacts écologiques, Énergies renouvelables, Adaptation |
quantum_computing.txt | Informatique Quantique | Principes quantiques (superposition, intrication), Algorithmes quantiques, Matériel quantique, Applications |
space_exploration.txt | Exploration Spatiale | Système solaire, Exploration martienne, Station spatiale internationale, Futur du voyage spatial, Exoplanètes |
sustainable_energy.txt | Énergies Durables | Énergie solaire, Énergie éolienne, Stockage d'énergie, Réseaux intelligents, Hydrogène vert |
sample_documents.txt | Science des Données | Méthodologie data science, Feature engineering, Évaluation de modèles, MLOps, Visualisation |
Ces fichiers forment ensemble une base de connaissances encyclopédique et pluridisciplinaire, permettant à l'assistant de répondre à des questions variées dans des domaines scientifiques et technologiques de pointe.
| Composant | Technologie | Rôle |
|---|---|---|
| Langage | Python 3.9+ | Langage de programmation principal |
| Vector Database | ChromaDB | Stockage et recherche sémantique |
| Embeddings | Sentence Transformers (all-MiniLM-L6-v2) | Conversion texte → vecteurs 384 dimensions |
| LLM | OpenAI / Groq / Gemini | Génération des réponses |
| Framework | LangChain | Orchestration RAG et gestion mémoire |
| Interface | CLI (Python) | Interaction en ligne de commande |
┌─────────────────────────────┐
│ USER │
│ Ask a Question │
└──────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ QUERY EMBEDDING │
│ Sentence Transformers │
│ (all-MiniLM-L6-v2) │
└──────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ VECTOR SEARCH │
│ ChromaDB │
│ Top-K Semantic Retrieval │
└──────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ RETRIEVED DOCUMENTS │
│ Relevant Chunks │
│ (chunk_size=500, overlap=50)│
└──────────────┬──────────────┘
│
┌────────────────┴────────────────┐
▼ ▼
┌───────────────────────┐ ┌─────────────────────────┐
│ CONVERSATION MEMORY │ │ PROMPT │
│ │ │ CONSTRUCTION │
│ Windowed Memory (5) │ │ Context + Question │
│ JSON Chat History │ │ Memory + Instructions │
└─────────────┬─────────┘ └──────────────┬──────────┘
│ │
└──────────────┬───────────────────┘
▼
┌─────────────────────────┐
│ LLM │
│ OpenAI / Groq / Gemini│
│ Grounded Generation │
└─────────────┬───────────┘
│
▼
┌─────────────────────┐
│ FINAL ANSWER │
│ Grounded Response │
└─────────────────────┘
| Composant | Description |
|---|---|
| RAGAssistant | Classe principale qui orchestre le flux de requêtes de bout en bout |
| VectorDB | Gère l'ingestion, le chunking et la recherche sémantique via ChromaDB |
| WindowedFileChatHistory | Mémoire personnalisée : fenêtre des 5 derniers échanges + persistance JSON |
| Multi-LLM Support | Intégration de modèles multi-fournisseurs (OpenAI, Groq, Gemini) |
| Prompt Template | Template structuré avec contraintes de prévention des hallucinations |
| CLI Interface | Interface en ligne de commande pour les tests interactifs |
Au démarrage de l'application, le système charge automatiquement tous les documents .txt présents dans le répertoire data/.
Pipeline d'ingestion :
RecursiveCharacterTextSplitter (chunk_size=500, overlap=50)all-MiniLM-L6-v2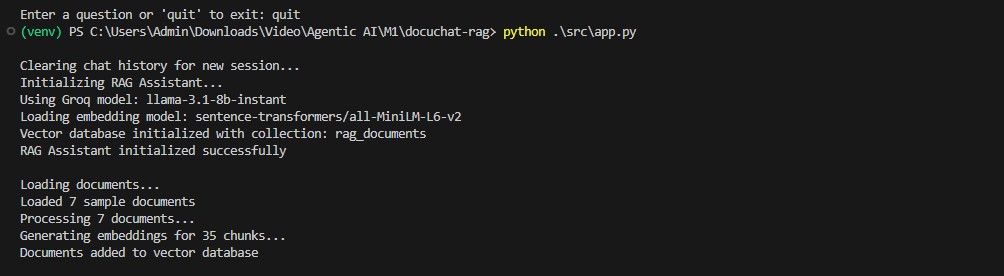
La recherche documentaire utilise la similarité cosinus avec indexation HNSW (Hierarchical Navigable Small World) pour une recherche instantanée.
| Paramètre | Valeur | Rôle |
|---|---|---|
| top_k | 3 | Nombre de chunks les plus pertinents à retourner |
| distance_threshold | 0.5 | Seuil de distance maximale pour validation |
L'application implémente une mémoire personnalisée via WindowedFileChatHistory :
class WindowedFileChatHistory(FileChatMessageHistory): """Retourne seulement les 5 derniers échanges au LLM, mais persiste tout l'historique dans un fichier JSON.""" def __init__(self, file_path: str, k: int = 5): super().__init__(file_path) self.k = k @property def messages(self): all_messages = super().messages # Garde les derniers k échanges (k*2 messages) return all_messages[-(self.k * 2):]
Bénéfices :
✅ Contexte limité = coût tokens constant
✅ Historique complet persistant (JSON)
✅ Reset automatique pour chaque session de test
L'application détecte automatiquement la clé API disponible parmi :
OpenAI : GPT-4o, GPT-3.5-Turbo
Groq : Llama-3, Mixtral
Google : Gemini Pro
Le prompt système inclut des contraintes strictes :
Constraints:
Tous les paramètres sont configurables via variables d'environnement (.env) :
Sélection du fournisseur LLM
Seuils de distance et top_k
Taille de la fenêtre mémoire (k)
Niveaux de journalisation
Flux de données
Flux d'ingestion des documents
┌───────────────────────┐
│ data/ directory │
│ Raw Text Documents │
│ (.txt files) │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Document Loading │
│ UTF-8 File Reader │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Text Chunking │
│ chunk_size = 500 │
│ overlap = 50 │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Embedding Generation │
│ SentenceTransformers │
│ 384-dim vectors │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ ChromaDB │
│ Vector Store │
│ Persistent Storage │
└───────────────────────┘
Flux de traitement des requêtes
┌───────────────────────┐
│ User Query │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Query Embedding │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Vector Search │
│ ChromaDB │
│ top_k = 3 │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Retrieved Context │
└───────────┬───────────┘
│
▼
┌───────────────────────────────┐
│ Prompt Assembly │
│ (Context + User Question) │
└───────────┬───────────────────┘
│
▼
┌──────────────────┐
│ LLM Generation │
│ (Grounded Answer)│
└──────────┬───────┘
▼
┌────────────────┐
│ Response │
└────────────────┘
Conversation Memory
(last 5 exchanges)
│
└────────────► Injected into Prompt
Exemple d'interaction
Exemple 1 : Intelligence Artificielle
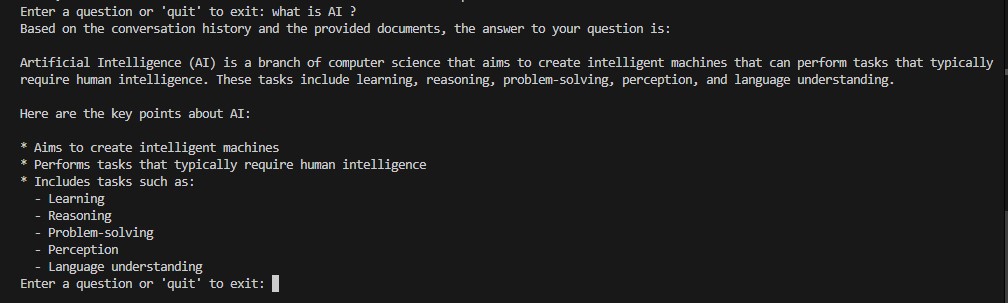
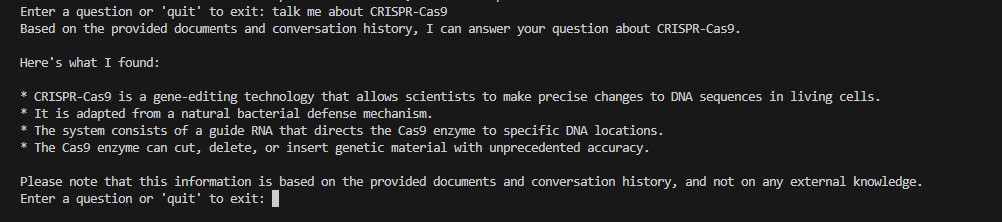
Exemple 2 : Questions de suivi (test mémoire)
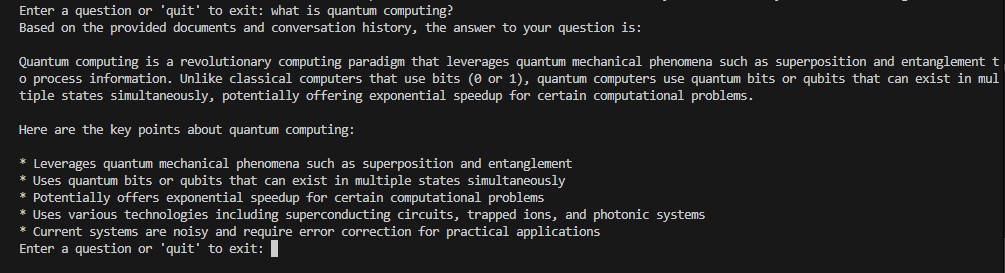
Exemple 3 : Informatique quantique
Suivez ces étapes pour installer et exécuter DocuChat-RAG sur votre machine.
git clone https://github.com/Mcduval/docuchat-rag.git cd docuchat-rag
python -m venv venv source venv/bin/activate # Linux/Mac venv\Scripts\activate # Windows
pip install -r requirements.txt
cp .env.example .env
Éditer .env avec votre clé (OpenAI, Groq ou Google)
Placez vos fichiers .txt dans le dossier data/
python src/app.py
Voici des exemples de questions à poser à l'assistant, organisées par thématique :
| Question |
|---|
| "What is Deep Learning?" |
| "Explain Natural Language Processing to me" |
| "What are the ethical challenges of AI?" |
| "What is the difference between supervised and unsupervised learning?" |
| Question |
|---|
| "How does CRISPR-Cas9 work?" |
| "What is personalized medicine?" |
| "Explain synthetic biology" |
| "What are the ethical considerations in biotechnology?" |
| Question |
|---|
| "What is the greenhouse effect?" |
| "How does climate change affect ecosystems?" |
| "What are the main renewable energy solutions?" |
| "What is the difference between climate adaptation and mitigation?" |
| Question |
|---|
| "What is quantum superposition?" |
| "What is Shor's algorithm used for?" |
| "What are the applications of quantum computing?" |
| "What are qubits and how do they differ from classical bits?" |
| Question |
|---|
| "What are the goals of Mars exploration?" |
| "What is the International Space Station?" |
| "How do scientists discover exoplanets?" |
| "What are the terrestrial planets in our solar system?" |
| Question |
|---|
| "How does solar energy work?" |
| "What is a smart grid?" |
| "Why is energy storage important for renewable energy?" |
| "What is green hydrogen and how is it produced?" |
| Question |
|---|
| "Explain the CRISP-DM methodology" |
| "What is feature engineering?" |
| "How do you evaluate a machine learning model?" |
| "What is MLOps?" |
| Scenario | Description |
|---|---|
| CRISPR Follow-up | "Tell me about CRISPR" → "Who discovered it?" → "What are its medical applications?" |
| Quantum Computing Follow-up | "Explain quantum computing" → "What makes it different from classical computing?" → "What are the current hardware limitations?" |
| Limite | Description |
|---|---|
| 📄 Support format limité | Seuls les fichiers .txt sont pris en charge |
| 🖥️ Pas d'interface web | Interface CLI uniquement (pas de Streamlit) |
| 👥 Pas de multi-sessions | Un seul historique de conversation à la fois |
| ☁️ LLM cloud uniquement | Pas de support pour modèles locaux (Ollama, LM Studio) |
| Fonctionnalité | Statut |
|---|---|
| 📄 Support PDF, Markdown, DOCX | 📋 Planifié |
| 🖥️ Interface web (Streamlit) | 📋 Planifié |
| 👥 Multi-sessions utilisateurs | 📋 Planifié |
| 💻 LLM local (Ollama, LM Studio) | 📋 Planifié |
| 🔍 Recherche hybride (BM25 + vectorielle) | 📋 Planifié |
| 📤 Export des conversations (PDF, TXT) | 📋 Planifié |
| Informations de contact |
GitHub : https://github.com/Mcduval
LinkedIn : https://www.linkedin.com/in/mokemi-tchakoute-bautrel-duval
Email : bautrelduval@gmail.com
Licence
Ce projet est distribué sous licence MIT