The objective of this project is to deploy, evaluate, and monitor a fine-tuned BART dialogue summarization model trained on the HighlightSum dataset, providing a practical reference for ML engineers, MLOps practitioners, and data scientists interested in production LLM systems.
The model training process is documented separately in the publication LLM Engineering and Deployment Certification: PEFT of BART for Dialogue Summarization.
This project focuses exclusively on the deployment and operational phase of the model lifecycle. It demonstrates how a fine-tuned model can be deployed as a managed cloud-based inference service using the Hugging Face Inference API, how it processes real dialogue inputs to generate summaries, and how key performance metrics are monitored post-deployment.
A controlled evaluation using 10 dialogue samples was conducted to assess operational behavior, including:
inference latency, cost projections and endpoint reliability. In addition, a monitoring setup was implemented to track usage metrics, errors, and operational performance indicators.
Overall, this project demonstrates how to:
This project deploys a fine-tuned BART-based Large Language Model (LLM) for dialogue summarization. The system takes multi-speaker conversational transcripts as input and generates concise, structured summaries.
The objective is to enable automated summarization of customer support conversations, meeting transcripts, and internal communication logs in order to:
The system is designed for:
The following examples were generated using the live Hugging Face Inference Endpoint.
All outputs shown are actual responses returned by the deployed model and are also stored in logs/demo_summaries.csv, available in the project's GiHhub repository
Input Dialogue
Olivia: Who are you voting for in this election? Oliver: Liberals as always. Olivia: Me too!! Oliver: Great
Model Output (Deployed Endpoint)
Oliver is voting for Liberals this election.
This output demonstrates the model’s ability to extract and concisely summarize the main decision expressed within a short conversational exchange.
Input Dialogue
Yannick: I heard you are going to sing the anthem at the game Nicki: Yes I am. I am nervous! Yannick: Dont be. It's a huge privilege to sing the anthem in front of thousands of people! Nicki: I hoep I won't forget the lyrics Yannick: Youre a great singer. You will be fine Nicki: I have to rehearse Yannick: Your parents coming with you? Nicki: Yes Yannick: They're probably proud of you good luck! Nicki: Thank you Yannick
Model Output (Deployed Endpoint)
Nicki is going to sing the anthem at the game. Yannick is going with Nicki to the game with her parents. Nicki is nervous.
This output demonstrates the model’s capacity to synthesize key contextual details and emotional cues from a longer multi-speaker dialogue into a coherent summary. While the model performs reliably, occasional abstraction drift may occur in longer dialogues, which is a known characteristic of abstractive summarization systems.
Input Dialogue
A: Hows the product launch going? B: Marketing is finalizing the assets. A: Great, keep me posted.
Model Output (Deployed Endpoint)
B tells A how marketing is finalizing the assets for the product launch.
This output demonstrates the model’s effectiveness in generating a structured summary of a brief status-oriented conversation.
Overall the above summaries reflect real-time responses from the deployed inference endpoint. They demonstrate the model’s ability to generate concise abstractive summaries of multi-speaker dialogue inputs in a production setting.
| Metric | Target |
|---|---|
| Average Latency | ≤ 3 seconds |
| Reliability | ≥ 99% successful responses |
| Cost per 1,000 Requests | < $1 |
| ROUGE-L Score | ≥ Fine-tuned baseline |
| Error Rate | < 1% |
Deployment is considered successful if performance, reliability, and cost remain within defined thresholds under expected load.
These assumptions guide infrastructure sizing and scaling strategy.
The deployed model is a fine-tuned version of BART-large, originally developed by Meta AI.
| Aspect | Configuration |
|---|---|
| Model | BART-large (Fine-tuned for Dialogue Summarization) |
| Model Source | Hugging Face Model Hub |
| Parameter Count | 406 Million |
| Quantization | None (FP16 Inference) |
| Context Length | 1024 Tokens |
| Max Output Tokens | 128 Tokens |
| Generation Strategy | Beam Search (4 beams) |
| Factor | Consideration |
|---|---|
| Size vs Quality | 406M parameters provide strong summarization without extreme GPU requirements |
| Cost vs Performance | Smaller than 7B+ models → lower inference cost |
| Encoder-Decoder vs Decoder-Only | Better structured summarization output |
| Quantization | Not used to preserve output quality |
Quantization (e.g., INT8 or INT4) could:
However, it may introduce minor degradation in summarization quality. Future optimization may include INT8 quantization for cost reduction.
The deployment uses:
| Platform | Reason Rejected |
|---|---|
| AWS SageMaker | Higher setup complexity |
| Modal | Less direct integration with model hub |
| Self-hosted EC2 | Requires manual scaling & DevOps |
| vLLM on Cloud VM | Optimized for large decoder-only models |
| Component | Configuration |
|---|---|
| vCPU Type | Intel Sapphire Rapids |
| Memory | 16GB VRAM |
| Endpoint Type | Real-time Inference |
| Scaling Strategy | Fixed capacity with autoscaling |
| Geographic Region | US-East |
| Deployment Artifact | Merged fine-tuned model |
The vCPU is:
More predictable scaling for lightweight summarization workloads
Suitable performance for low-to-moderate traffic scenarios
This configuration balances cost efficiency and performance reliability.
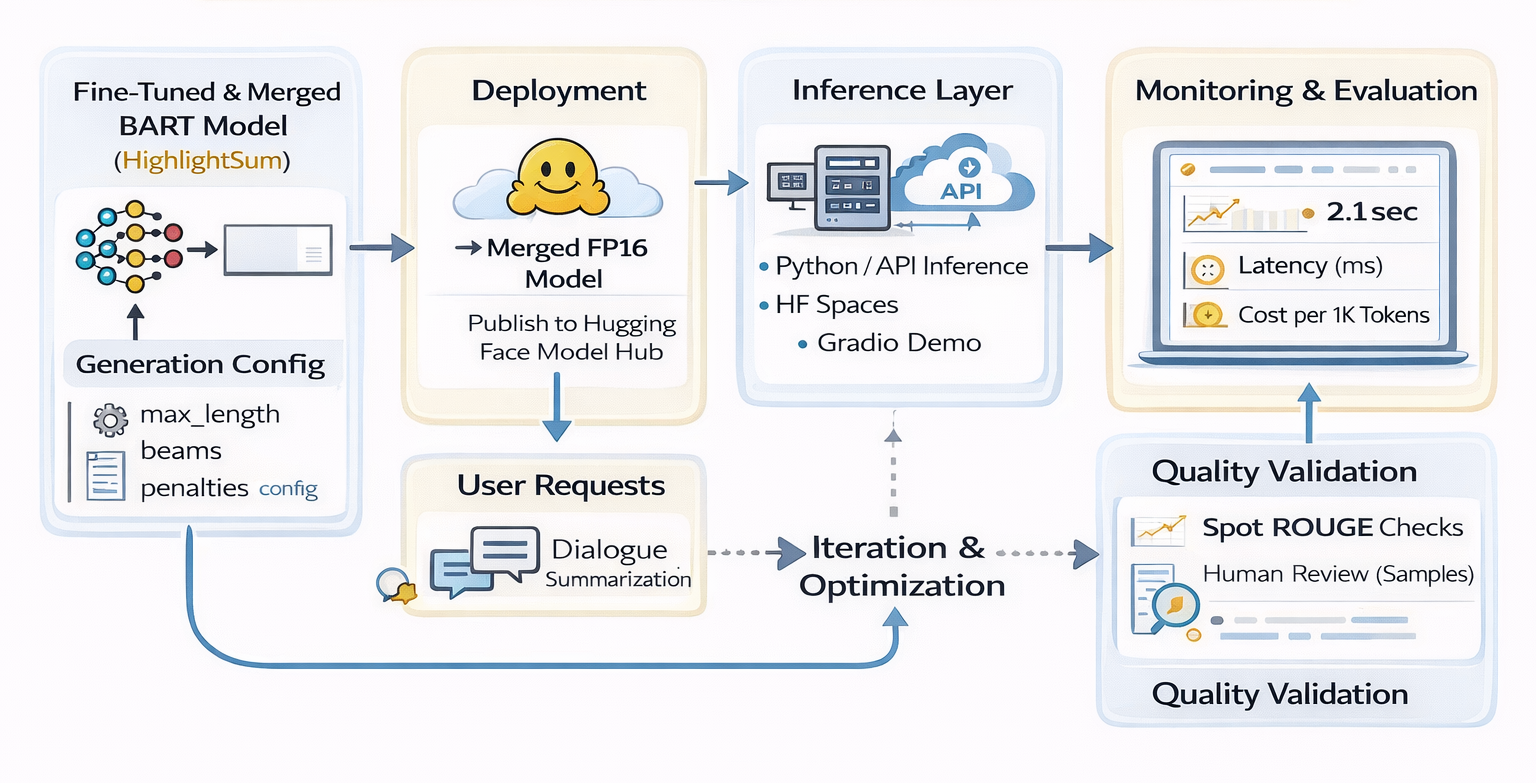
The architecture diagram below illustrates the end-to-end deployment flow.
User Application ((Web Browser) ↓ Gradio Web App (Hugging Face Spaces UI Layer) ↓ Client Script (Authenticated API Call) ↓ Hugging Face Inference Endpoint ↓ Managed vCPU Instance ↓ Fine-Tuned BART Model (PEFT) ↓ Generated Summary Response ↓ Metric Logging (Latency, Errors, Token Usage) ↓ Weights & Biases Dashboard ↓ Monitoring and Alerting
The workflow emphasizes:
Note : The earlier stages of the model lifecycle are documented in the original training publication LLM Engineering and Deployment Certification: PEFT of BART for Dialogue Summarization
A detailed cost model supporting the estimates below is provided in the accompanying spreadsheet docs/cost_estimate.xlsx of the Github of this project.
| Cost Component | Monthly Estimate |
|---|---|
| Compute (GPU) | $194 |
| Storage (Model+ Logs) | $10 |
| Network Transfer | $15 |
| Monitoring (W&B) | |
| Total Estimated | ~ |
The baseline estimate assumes a single Intel Sapphire Rapids vCPU running continuously (720 hours/month) at $0.27 per hour. Monitoring costs vary depending on Weights & Biases plan selection.
The full calculation logic (including formulas and adjustable parameters) is available in docs/cost_estimate.xlsx for transparency and reproducibility.
Assumptions:
Cost per request:
0.27 ÷ 200 = $0.00135
Cost per 1,000 requests:
0.00135×1000=1.35
Estimated Cost ≈ $1.35 per 1,000 requests
The spreadsheet includes editable cells for:
This allows dynamic adjustment of cost projections under different deployment scenarios.
Cost projections are based on assumed steady-state throughput (200 requests/hour) and measured stability from a 10-dialogue evaluation. Large-scale concurrency and stress testing were not conducted; therefore, actual production costs may vary depending on traffic distribution, batching efficiency, autoscaling configuration, and sustained CPU utilization.
| Strategy | Description | Impact on Cost | Trade-Off |
|---|---|---|---|
| Quantization | Reduce model precision to INT8 or INT4 to lower memory footprint and GPU requirements. | Lower compute cost and improved throughput. | Potential minor degradation in summary quality. |
| Batching | Process multiple inference requests simultaneously to maximize GPU utilization. | Reduced cost per request. | Slight increase in per-request latency. |
| Caching | Store summaries of frequently repeated dialogue inputs. | Reduces repeated inference calls. | Requires cache invalidation strategy. |
| Auto-Scaling | Dynamically scale replicas based on traffic volume. | Prevents overpaying during low-traffic periods. | Cold-start latency during scale-up events. |
| Spot Instances | Use discounted/preemptible GPU instances where supported. | Significant infrastructure cost reduction. | Risk of instance interruption. |
A combination of quantization, batching, and auto-scaling provides the most balanced approach to minimizing cost while maintaining acceptable latency and summary quality.
| Metric | Why It Matters | Alert Threshold |
|---|---|---|
| p50 Latency | UX consistency | > 2.5s |
| p99 Latency | Tail performance | > 4s |
| Error Rate | Reliability | > 2% |
| Throughput | Capacity | < 2 RPS |
| Token Usage | Cost control | > 800 tokens/request |
| GPU Utilization | Efficiency | < 20% or > 95% |
| Tool | Purpose |
|---|---|
| Weights & Biases | Logging & visualization |
| Hugging Face Dashboard | Endpoint monitoring |
| Custom Logging | Latency + token tracking |
The table below summarizes the key performance results obtained from the reproducible test setup (10 inference requests).
| Metric | Target/References | Actual Measured Value |
|---|---|---|
| Average Latency | ≤ 3s | ~3.6s |
| Reliability | ≥ 99% | 100% |
| Cost per 1K Tokens | < $0.50 | ~$0.0015 |
| Total Cost (10 requests) | Negligible | ~$0.0027 |
@ Cost per 1K Tokens = Derived from runtime + token usage
Performance is stable with slightly elevated latency that can be optimized (with fewer beams, smaller max length, or faster hardware).
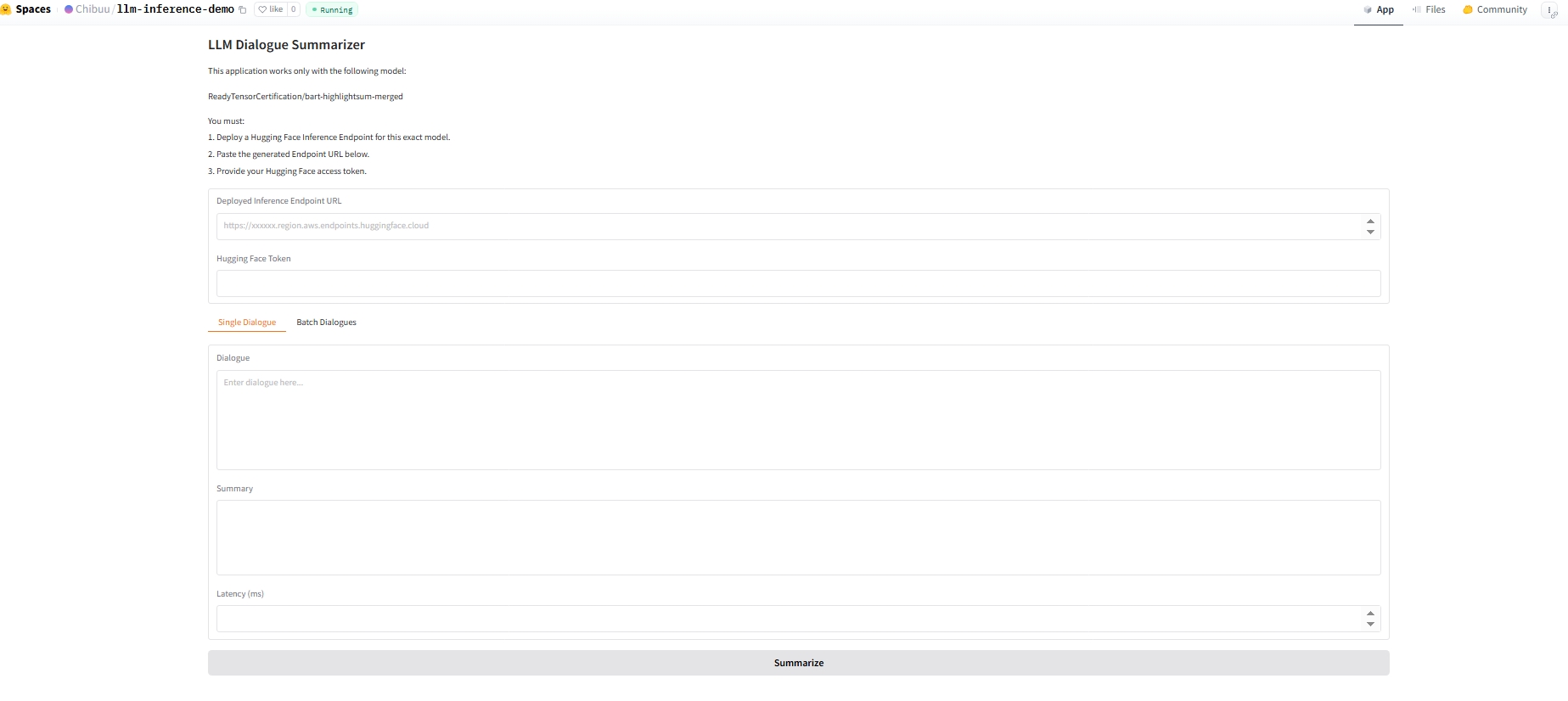
The deployment includes an interactive Gradio-based web application hosted on Hugging Face Spaces, titled “LLM Dialogue Summarizer”.
The web interface demonstrates real-time LLM inference for dialogue summarization using the model ReadyTensorCertification/bart-highlightsum-merged.
The application allows users to enter:
It also displays the latency (ms) for each request.
Important: This application does not host the model locally. It requires a deployed Hugging Face Inference Endpoint for the specified model.
Before using the app, the user must:
Deploy a Hugging Face Inference Endpoint for the ReadyTensorCertification/bart-highlightsum-merged
Obtain:
The interface includes:
The app will return:
This example demonstrates the deployed model functioning as a user-facing inference service.
This example illustrates:
.jpeg?Expires=1783459610&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=zYcuG-bEblBloT~Z8ZT61p-~4VBw9S3A-xJgJckM6MMt8GnrcLGk2MTr0gtk0~k-K~oih2KAdzdO-dmYft7zym~2kagKjNSQj7TUtbQbiX-bp2xhDK-bUGbrEnq26IbL33hs-zyXWi4N-JVm-dz4n~k9pgX2I1DzwUN19joTyMhh--wlZI5ZgXtQAOCCry3S2eMZYahYQTQbX9GnMLwkG9LKRxwI0RhoQG8WMTHUeaCvPE3TD98W767AhxF5LOMlL5xeJD5w66ce~QHgW63so~8JN0zHgURYqnZrN8anceD60c3ePlC~N-9gTyIqXPeY70k3zfjoH6SlX~200VbR5Q__)
Below are two example of screenshots (the latency plot and the error plot, respectively) from the W&B monitoring dashboard.
.png?Expires=1783459610&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=IhcHrnbLxCGR6yAhHpWBHZ4-upk4hgwYC7Q6CKOy28oFdMGY3bM7PYcAYKJ1lYGii7ktl6~ndI3nUdw0ogRr57T4V5Fo30ACRh6SW4gUySzPwfAqB~Eh-MbijitckL43ArJgwRFErpNxGy7XauFyCKaJLSdrG934ToFunJb4fjYY0Q4DuEzMWlfvdA40sbwASBObxEC-4SUHcGFt~N0VSJotsn68HOIZAFw~yJMtwYYJ9YcBM8fvpNMfGJRl6UvpX9eOCchZWiZulao3tP9V0-iohZ~ePu2SicKWi-NZI4~B3o874IuVa6vOAxfzOJbIORQjcmkJeGRgh6B55bJ7Iw__)
.png?Expires=1783459610&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=fm~DeOGG7GEx8QUzNoWFXgF-Uf3v9zqqh3lTUALWeq1bXI9p3apJOV9hKR3tCxeMBtSQ6n7Gv5DhZiWGwiOOBkAq5qLBfyYngWhP9lKh~EmaMLl90ZYqej6ID~w2KCoyPEigIyeSDPMR0O4PAoAuhvUXtabVs5IfkYuy90-GkYFJtRxh1DUV0DHAncGUcezARfA1EJs-~pz6H1P-2wiTQNs9UDdayV9MyreZkft0HGAzQm84o8yGotEbJyYzzveSt31rwVaAhfn1CS2PgKRZTNIDaYXLH8lIAPia48gdaJuHNwyw9lBIQSpY-TWHWaMIDluofMZnr-vWkzqcUw7PmQ__)
Note: To focus on user-facing performance and reliability, only latency and error rate plots are shown. These metrics directly reflect response time and system correctness, while other metrics are used for internal monitoring and remained within acceptable thresholds during evaluation.
While the deployment successfully demonstrates managed model serving, cost modeling, and monitoring integration, several limitations should be noted:
Potential future improvements include:
Feel free to suggest more ideas by opening an issue or starting a discussion! For bug reports or feature requests, open an issue. For general questions or share your thoughts, start a comment.
This project demonstrates a complete end-to-end deployment of a fine-tuned BART dialogue summarization model, including:
The deployment achieves high reliability and low cost while maintaining acceptable latency, providing a practical reference architecture for LLM production systems.
We welcome contributions to improve the project:
1 Fork the GitHub repository
2 Create a feature branch:
git checkout -b your-feature-name
3 Commit and push your changes
4 Submit a Pull Request and describe your contribution.
Please follow our code style and guidelines. For questions or suggestions, open an issue
Licensed under the MIT License
For questions or feedback, please contact the authors:
This project is part of LLM Engineering and Deployment Certification program by the Ready Tensor. We appreciate the contributions of the Ready Tensor developer community for their guidance and contributions.
