
This document presents a comprehensive evaluation rubric for assessing technical publications in AI and data science on Ready Tensor. The rubric evaluates publications through four fundamental questions: What is this about? (Purpose), Why does it matter? (Value/Impact), Can I trust it? (Technical Quality), and Can I use it? (Documentation).
The system uses a binary scoring method (met/not met) across different criteria tailored to four main publication categories: Research & Academic Publications, Educational Content, Real-World Applications, and Technical Assets. Each category has specific requirements based on its purpose, with clear positive and negative indicators for objective assessment.
The rubric serves multiple audiences:
While meeting the rubric's criteria establishes baseline quality, exceptional publications often demonstrate unique insights, innovative approaches, or significant practical impact beyond these basic requirements.
Technical publications in AI and data science need objective ways to assess their quality and effectiveness. Authors want to know if their publications meet quality standards. Readers want to know if a publication will serve their needs. Reviewers need consistent ways to evaluate submissions.
This document presents an evaluation rubric that addresses these needs. The rubric examines each publication through four key questions:
By answering these questions systematically, the rubric provides clear criteria for measuring technical quality across different publication types. Authors can use it to create better publications. Reviewers can apply it for consistent evaluation.
Publications on Ready Tensor serve diverse purposes - from advancing research to teaching concepts to documenting solutions. This evaluation rubric ensures each publication effectively serves its purpose by examining four key aspects: clarity of purpose, significance, technical credibility, and practical usability.
Authors can use this rubric to understand what makes their publications effective. By addressing the core questions - what is this about, why does it matter, can I trust it, can I use it - authors ensure their work provides clear value to readers.
The rubric uses a binary scoring system. Each criterion is marked as either met or not met based on specific evidence. This approach provides:
For publication competitions, this rubric helps identify quality submissions. While meeting these criteria establishes baseline quality, exceptional publications often demonstrate unique insights, innovative approaches, or significant practical impact beyond the baseline requirements.
The evaluation rubric works alongside the Ready Tensor Best Practices Guide:
Best Practices Guide - Focuses on how to present content effectively through clear writing, good organization, and visual elements
This Evaluation Rubric - Provides criteria and scoring methodology for evaluating technical quality, completeness, and effectiveness
Authors should use both documents. Follow the Best Practices Guide for effective presentation while ensuring your work meets all rubric criteria.
The evaluation rubric divides technical publications into different types, each with its own specific evaluation criteria. These publication types and their detailed criteria are covered in later sections of this document.
The rubric uses binary scoring (met/not met) for individual criteria to provide a structured framework for evaluation. While total scores help indicate technical quality and completeness, they should not be used for direct comparisons between different publication types. For example, a research paper scoring 41 out of 45 criteria should not be compared with a tutorial scoring 16 out of 18 criteria, as they serve different purposes and are evaluated against different standards.
Even within the same publication type, scores alone don't determine absolute quality rankings. A publication with a lower score might be more valuable due to unique insights or innovative approaches. The rubric should be viewed as a supportive tool for ensuring quality standards while recognizing that excellence can take many forms.
While the evaluation criteria described in this publication help identify quality publications, exceptional work often goes beyond meeting basic requirements. Innovation, insight, and practical value play important roles in final evaluations.
The evaluation rubric assesses publications by answering four fundamental questions that apply across all technical publications on Ready Tensor.
What is this about? (Purpose)
Every publication must clearly state what readers will get from it. This means defining the scope, objectives, and intended outcomes up front. Purpose clarity helps readers immediately understand if the publication meets their needs.
Why does it matter? (Value/Impact)
Publications must establish their significance and value proposition. Readers should understand the practical, technical, or theoretical importance of the work.
Can I trust it? (Technical Quality)
All content must be technically sound. While the depth and nature of validation vary by publication type, technical accuracy and proper substantiation of claims are universal requirements. This ensures readers can confidently use or build upon the work.
Can I use it? (Documentation)
Content should be properly documented for its intended purpose. The type of documentation varies with publication type, but all content must provide sufficient information for readers to achieve the stated purpose.
Evaluators apply criteria mapped to the four fundamental questions, with requirements appropriate to each publication type. A binary scoring system (met/not met) ensures clear, objective assessment:
For a criterion to be met, evaluators must see clear evidence within the publication. For example, a "clear statement of purpose" needs an explicit purpose statement in the introduction. "Proper citation of sources" means all technical claims have specific references.
When a criterion is not met, evaluators identify specific gaps or inadequacies, making it clear what authors need to improve.
The rubric recognizes that publications serve different purposes. Success means effectively delivering value within the publication's intended scope.
Evaluators assess criteria based on evidence found within the publication and its linked resources. Evidence must be verifiable - evaluators must be able to examine and validate claims directly.
Technical Documentation
Evaluators look for citations, equations, methodology descriptions, experimental results, and other technical content that substantiates claims and demonstrates rigor. Claims based on proprietary or closed-source methods require additional supporting evidence to be considered verified.
Visual Evidence
Diagrams, graphs, screenshots, and demo videos help communicate complex concepts and demonstrate real implementations. While visual evidence supports understanding, key technical claims must be backed by verifiable technical documentation.
Code Evidence
Code repositories, samples, installation instructions, and API documentation demonstrate implementation details and enable practical use. Open-source code allows direct verification of claims about functionality and performance. For closed-source tools, claims must be clearly scoped to what can be externally verified.
Data Evidence
Data repositories, files, and quality metrics provide concrete support for claims and enable result verification. Publicly accessible datasets allow direct validation. For proprietary datasets, publications must document data characteristics and quality measures that can be independently assessed.
Each criterion is assessed as met (1 point) or not met (0 points) based on the presence and quality of verifiable evidence. The types of evidence required vary by publication type and specific criteria. Claims that cannot be verified through available evidence do not meet assessment criteria.
The evaluation framework adapts its specific criteria to match the purpose of each publication type while maintaining the core questions. A research publication requires rigorous methodology and validation but may not need deployment guides. A tutorial needs clear step-by-step instructions but may not need statistical analysis. An industry case study demands business impact evidence but may not need mathematical proofs.
For each publication type, criteria are selected to evaluate what matters most for that content's purpose and audience. Research publications focus on methodology, validation, and novel contributions. Educational content emphasizes clarity, completeness, and practical application. Industry publications prioritize real-world impact and implementation guidance. Technical asset documentation must demonstrate functionality and enable proper use.
This adaptation ensures publications are evaluated fairly within their intended purpose. While all publications must answer our core questions - what is this about, why does it matter, can I trust it, can I use it - the evidence needed to answer these questions appropriately varies by type.
Publications on Ready Tensor fall into four main categories based on their primary purpose and target audience:
The following chart lists the common project types:

The following table describes each project type in detail, including the publication category, publication type, and a brief description along with examples:
| Publication Category | Publication Type | Description | Examples |
|---|---|---|---|
| Research & Academic Publications | Research Paper | Original research contributions presenting novel findings, methodologies, or analyses in AI/ML. Must include comprehensive literature review and clear novel contribution to the field. Demonstrates academic rigor through systematic methodology, experimental validation, and critical analysis of results. | • "Novel Attention Mechanism for Improved Natural Language Processing" • "A New Framework for Robust Deep Learning in Adversarial Environments" |
| Research & Academic Publications | Research Summary | Accessible explanations of specific research work(s) that maintain scientific accuracy while making the content more approachable. Focuses on explaining key elements and significance of original research rather than presenting new findings. Includes clear identification of original research and simplified but accurate descriptions of methodology. | • "Understanding GPT-4: A Clear Explanation of its Architecture" • "Breaking Down the DALL-E 3 Paper: Key Innovations and Implications" |
| Research & Academic Publications | Benchmark Study | Systematic comparison and evaluation of multiple models, algorithms, or approaches. Focuses on comprehensive evaluation methodology with clear performance metrics and fair comparative analysis. Includes detailed experimental setup and reproducible testing conditions. | • "Performance Comparison of Top 5 LLMs on Medical Domain Tasks" • "Resource Utilization Study: PyTorch vs TensorFlow Implementations" |
| Educational Content | Academic Solution Showcase | Projects completed as part of coursework, self-learning, or competitions that demonstrate application of AI/ML concepts. Focuses on learning outcomes and skill development using standard datasets or common ML tasks. Documents implementation approach and key learnings. | • "Building a CNN for Plant Disease Detection: A Course Project" • "Implementing BERT for Sentiment Analysis: Kaggle Competition Entry" |
| Educational Content | Blog | Experience-based articles sharing insights, tips, best practices, or learnings about AI/ML topics. Emphasizes practical knowledge and real-world perspectives based on personal or team experience. Includes authentic insights not found in formal documentation. | • "Lessons Learned from Deploying ML Models in Production" • "5 Common Pitfalls in Training Large Language Models" |
| Educational Content | Technical Deep Dive | In-depth, pedagogical explanations of AI/ML concepts, methodologies, or best practices with theoretical foundations. Focuses on building deep technical understanding through theory rather than implementation. Includes mathematical concepts and practical implications. | • "Understanding Transformer Architecture: From Theory to Practice" • "Deep Dive into Reinforcement Learning: Mathematical Foundations" |
| Educational Content | Technical Guide | Comprehensive, practical explanations of technical topics, tools, processes, or practices in AI/ML. Focuses on practical understanding and application without deep theoretical foundations. Includes best practices, common pitfalls, and decision-making frameworks. | • "ML Model Version Control Best Practices" • "A Complete Guide to ML Project Documentation Standards" |
| Educational Content | Tutorial | Step-by-step instructional content teaching specific AI/ML concepts, techniques, or tools. Emphasizes hands-on learning with clear examples and code snippets. Includes working examples and troubleshooting tips. | • "Building a RAG System with LangChain: Step-by-Step Guide" • "Implementing YOLO Object Detection from Scratch" |
| Real-World Applications | Applied Solution Showcase | Technical implementations of AI/ML solutions solving specific real-world problems in industry contexts. Focuses on technical architecture, implementation methodology, and engineering decisions. Documents specific problem context and technical evaluations. | • "Custom RAG Implementation for Legal Document Processing" • "Building a Real-time ML Pipeline for Manufacturing QC" |
| Real-World Applications | Case Study | Analysis of AI/ML implementations in specific organizational contexts, focusing on business problem, solution approach, and impact. Documents complete journey from problem identification to solution impact. Emphasizes business context over technical details. | • "AI Transformation at XYZ Bank: From Legacy to Innovation" • "Implementing Predictive Maintenance in Aircraft Manufacturing" |
| Real-World Applications | Technical Product Showcase | Presents specific AI/ML products, platforms, or services developed for user adoption. Focuses on features, capabilities, and practical benefits rather than implementation details. Includes use cases and integration scenarios. | • "IntellAI Platform: Enterprise-grade ML Operations Suite" • "AutoML Pro: Automated Model Training and Deployment Platform" |
| Real-World Applications | Solution Implementation Guide | Step-by-step guides for implementing specific AI/ML solutions in production environments. Focuses on practical deployment steps and operational requirements. Includes infrastructure setup, security considerations, and maintenance guidance. | • "Production Deployment Guide for Enterprise RAG Systems" • "Setting Up MLOps Pipeline with Azure and GitHub Actions" |
| Real-World Applications | Industry Report | Analytical reports examining current state, trends, and impact of AI/ML adoption in specific industries. Provides data-driven insights about adoption patterns, challenges, and success factors. Includes market analysis and future outlook. | • "State of AI in Financial Services 2024" • "ML Adoption Trends in Healthcare: A Comprehensive Analysis" |
| Real-World Applications | White Paper | Strategic documents proposing approaches to industry challenges using AI/ML solutions. Focuses on problem analysis, solution possibilities, and strategic recommendations. Provides thought leadership and actionable recommendations. | • "AI-Driven Digital Transformation in Banking" • "Future of Healthcare: AI Integration Framework" |
| Technical Assets | Dataset Contribution | Creation and publication of datasets for AI/ML applications. Focuses on data quality, comprehensive documentation, and usefulness for specific ML tasks. Includes collection methodology, preprocessing steps, and usage guidelines. | • "MultiLingual Customer Service Dataset: 1M Labeled Conversations" • "Medical Image Dataset for Anomaly Detection" |
| Technical Assets | Open Source Contribution | Contributions to existing open-source AI/ML projects. Focuses on collaborative development and community value. Includes clear description of changes, motivation, and impact on the main project. | • "Optimizing Inference Speed in Hugging Face Transformers" • "Adding TPU Support to Popular Deep Learning Framework" |
| Technical Assets | Tool/App/Software | Introduction and documentation of specific software implementations utilizing AI/ML. Focuses on tool's utility, functionality, and practical usage rather than theoretical foundations. Includes comprehensive usage information and technical specifications. | • "FastEmbed: Efficient Text Embedding Library" • "MLMonitor: Real-time Model Performance Tracking Tool" |
Understanding these publication types helps authors:
The evaluation criteria and scoring process vary by publication type to reflect their different purposes and requirements. Later sections detail how specific quality criteria apply to each type.
This classification system ensures publications effectively serve their intended purpose while maintaining consistent quality standards across different types of content.
Choose your publication type based on your primary goal. For example:
The evaluation rubric uses standardized criteria components to ensure consistent assessment. Each component serves a specific purpose in helping evaluators make objective decisions.
1. Criterion Name
A clear, descriptive title that identifies what aspect of the publication is being evaluated.
2. Criterion Description
The description defines what the criterion measures and provides complete context for evaluation. It specifies where in the publication to look for evidence, clarifies what qualifies as meeting the criterion, and identifies any special cases or exceptions. A good criterion description removes ambiguity about what constitutes meeting the standard.
3. Scoring Logic
The rubric uses binary scoring (0 or 1) with explicit rules stating what merits each score. This ensures evaluators have clear guidelines for assessment decisions. The scoring logic aims to remove subjectivity from the evaluation process by providing specific, measurable requirements.
4. Positive Indicators
Positive indicators are observable evidence in the publication that signal a criterion has been met. They provide concrete, verifiable signs that evaluators can look for during assessment. For example, if evaluating code quality, a positive indicator might be "Code includes descriptive comments explaining each major function." These are specific elements that can be visually identified or objectively verified in the publication.
5. Negative Indicators
Negative indicators are observable evidence that a criterion has not been met. They represent specific, verifiable red flags that evaluators can spot during review. Following the code quality example, a negative indicator might be "Functions lack parameter descriptions" or "No comments explaining complex logic." These indicators point to concrete, observable issues rather than subjective judgments.
This structured approach promotes objective evaluation through clear rules and consistent assessment standards. When all evaluators use the same detailed criteria, they can arrive at similar scoring decisions independently. The components also provide actionable feedback - authors know exactly what they need to improve based on which criteria they did not meet.
The detailed criteria structure means publication creators can understand requirements before they begin writing. This helps them include necessary elements and avoid common problems that would reduce their evaluation scores.
Let's examine how these components work together through an example...
This fundamental criterion serves as a good example because it demonstrates how seemingly subjective requirements ("clarity of purpose") can be evaluated objectively through specific indicators.
Criterion Definition
Evaluates whether the publication explicitly states its core purpose within the first
paragraph or two. The purpose statement must clearly indicate what specific problem
is being solved, what will be learned, or what will be demonstrated. This must appear
in the abstract, tl;dr, introduction, or overview section and be immediately clear
without requiring further reading.
The key differentiator is an explicit, specific purpose statement near the top that
lets readers immediately understand what the publication will deliver.
Scoring Logic
- Score 0: Purpose is unclear, appears too late, requires inference, or is too vague
- Score 1: Explicit purpose statement appears in first paragraph/10 sentences and clearly states specific deliverables
Positive Indicators
Evaluators look for these observable elements:
- States specific purpose in first paragraph
- Uses explicit purpose statement phrases ("This paper demonstrates...", "In this guide, you will learn...")
- Lists specific skills or knowledge to be gained
- States exact problem being solved
- Defines precise scope of work
- Indicates specific contributions or solutions
- Provides clear list of deliverables
Negative Indicators
Evaluators watch for these red flags:
- No purpose or objective stated
- Purpose appears after several paragraphs
- Requires reading multiple paragraphs to understand goal
- Lists multiple potential purposes
- Purpose scattered across document
- Ambiguous or general statements
- Purpose must be pieced together from multiple sections
Why This Definition Works
Notice how this criterion converts the abstract concept of "clear purpose" into specific, verifiable elements:
The indicators remove subjectivity by specifying exactly what evaluators should look for. Authors know precisely where to put their purpose statement and what it should contain.
The following table lists all technical criteria used in the evaluation rubric:

For detailed definitions of each criterion, including complete descriptions, scoring logic, and positive/negative indicators, refer to the supplementary document Publication Evaluation Criteria Reference Guide.pdf uploaded with this publication. Authors and evaluators should consult this reference when preparing or assessing publications.
The evaluation rubric defines specific criteria for each publication type on Ready Tensor. These criteria ensure publications effectively serve their intended purpose and audience. By systematically answering core questions about purpose, significance, trustworthiness, and usability, authors can create high-quality publications that meet audience needs.
The complete mapping of criteria to publication types is provided in zipped package titled Scoring Criteria Per Publication Type.zip in the Resources section. While specific requirements vary, all criteria support answering the core questions in ways that match each publication type's purpose and audience expectations.
The rubric provides a scoring mechanism where publications earn points by meeting different criteria. A higher score indicates stronger technical quality and completeness. Publications do not need to meet all criteria - the score reflects how many criteria are satisfied. For competitions, while scoring helps identify quality submissions, exceptional publications often provide unique insights, innovative approaches, or significant practical value beyond standard requirements.
The evaluation rubric uses a straightforward scoring system based on objective criteria per publication type. The evaluation follows these steps:
Publication Type: Determine the specific type based on content and purpose (e.g., Research Paper, Tutorial, Dataset)
Applicable Criteria: Apply the criteria set defined for that publication type
Binary Assessment: Score each criterion:
Equal Weighting: Each criterion carries equal weight of one point
Total Score: Sum the points across all applicable criteria
Final Assessment: Compare total points to maximum possible score for that publication type. The score can be converted to a percentage for easier interpretation and simplistic comparison across different publications.
This rubric adopts a simple approach where all criteria carry equal weight. Future versions may introduce weighted scoring to emphasize specific aspects like innovation or practical impact. While the rubric helps identify quality publications through objective criteria, competition winners are selected based on additional factors. A publication scoring 22/25 might win over one scoring 25/25 if it demonstrates exceptional innovation or practical value. The rubric serves as a baseline quality check rather than the sole determinant of competition outcomes.
To demonstrate how the evaluation rubric works in practice, let us examine a real publication: Decade of AI and ML Conferences: A Comprehensive Dataset for Advanced Research and Analysis.
This publication falls under the "Dataset Contribution" type under the "Technical Assets" category. The evaluation rubric defines 29 specific criteria for this publication type, ensuring it meets the intended purpose and audience expectations. These are listed in the following figure.
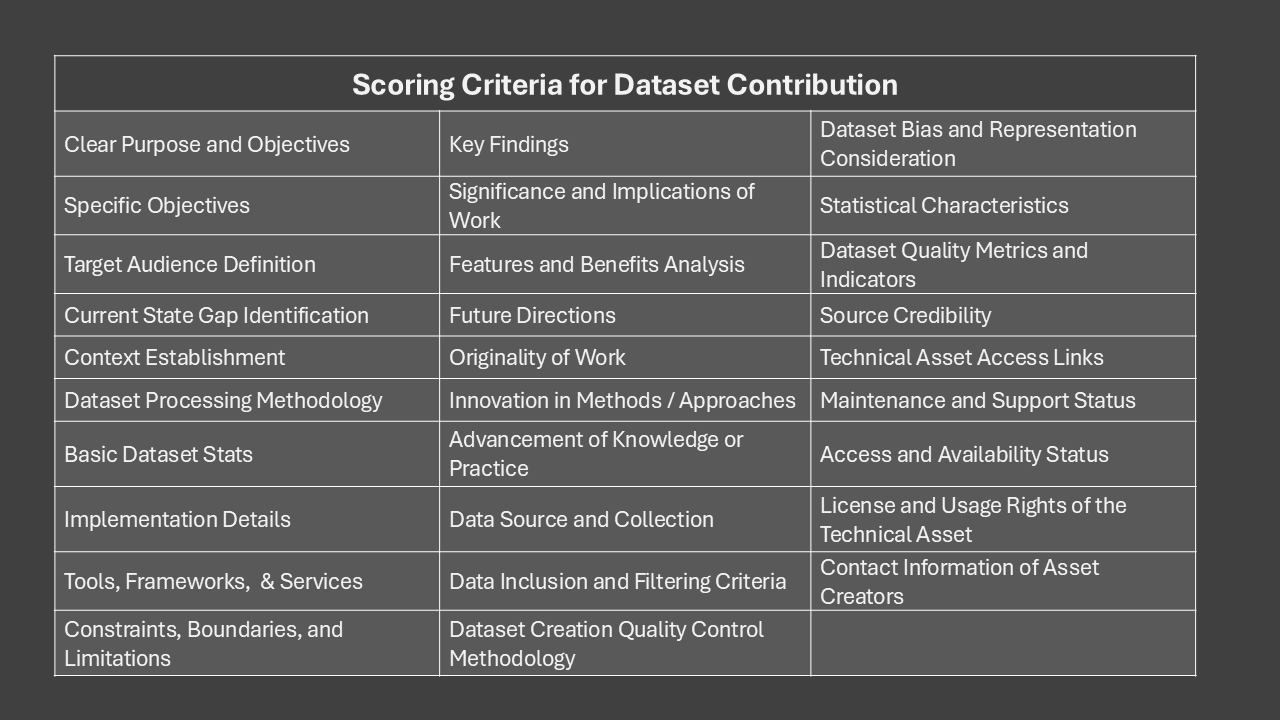
The technical content and resources provided by the authors are evaluated against these criteria to determine the publication's quality and effectiveness. The evaluation process involves systematically answering core questions about the publication's purpose, significance, trustworthiness, and usability.
We have attached the evaluation report for this publication in the document titled "Evaluation Report - Decade of AI and ML Conferences.pdf" in the Resources section. This report provides a detailed assessment of the publication based on the defined criteria. This dataset contribution publication scores 25 out of 29 possible points, meeting most quality criteria. The four criteria not met are listed in following table:
| Criteria | Explanation | Recommendation |
|---|---|---|
| 1. Data Inclusion Criteria | The publication does not provide clear criteria for data inclusion or exclusion from the dataset. While it describes the dataset and its contents, it lacks explicit rules or rationale for how data was selected or filtered, which is essential for transparency and reproducibility. | Include a section that outlines the criteria for data inclusion and exclusion, providing clear rules, justifications for filtering decisions, and any edge cases that were considered. |
| 3. Limitations Discussion | The publication does not discuss any limitations, trade-offs, or potential issues related to the project work. There is no mention of key limitations, scope boundaries, or the impact of any limitations, which are essential for a comprehensive understanding of the research. | Include a section that discusses the limitations of the dataset and the Mini-RAG system, addressing any potential issues, trade-offs, and the impact of these limitations on the research outcomes. |
| 3. Future Directions | The publication does not discuss any future directions or research gaps. While it provides a comprehensive overview of the dataset and its applications, it lacks specific suggestions for future work or improvements, which are necessary to score positively on this criterion. | Include a section that outlines specific future research directions, identifies research gaps, or suggests potential improvements to the current system. |
| 4. Contact Information | The publication does not provide any contact information or support channels for users to reach out for questions or issues. There are no references to external channels such as GitHub issues, support email addresses, or community forums. | Include contact information for the creators or maintainers, such as an email address or links to support channels, to assist users in getting help or reporting issues. |
The report also provides recommendations for addressing these gaps and improving the publication's quality. Authors can use this feedback to enhance their work and meet the criteria more effectively.
This example demonstrates how the evaluation rubric identifies both strengths and specific areas for improvement in a publication. Authors can use these insights to enhance their work while maintaining flexibility in how they address certain criteria.
This evaluation rubric provides a structured approach to assessing AI and data science publications on Ready Tensor. The rubric:
Authors can use this rubric as a guide when preparing their publications. Meeting the criteria ensures publications provide clear value through:
For competition participants, while meeting these criteria establishes baseline quality, exceptional publications often demonstrate unique insights, innovative approaches, or substantial practical impact beyond the basic requirements.
The included example evaluation demonstrates how the rubric works in practice, showing both strengths and opportunities for improvement in a real publication. This practical approach helps authors understand exactly what makes their publications effective and how to enhance their contributions to the AI and data science community.
