The objective of this project was to develop an efficient, deployable dialogue summarization model using open-source LLMs. Dialogue summarization is a high-impact task for customer service, meeting assistants, financial assistants, personal AI agents, and enterprise workflow automation.
This project focuses on selecting an optimal base model through benchmarking, fine-tuning it on a conversational summarization dataset, optimizing efficiency using LoRA/QLoRA, evaluating performance with industry-standard metrics Producing a deployable inference-ready model
You may be wondering, why Dialogue Summarization?
Dialogue summarization is uniquely challenging because:
Inputs contain multi-turn, unstructured speech
Speakers often introduce new topics without transitions
Long context must be compressed without losing meaning
HighlightSum is a particularly suitable dataset because it contains real, multi-speaker conversations paired with concise “highlight” summaries, closely matching real-world summarization needs. Its a collection of large-scale dialogue summarization dataset from AMI, SamSUM & DialogSUM, consisting of 31,108 dialogues with corresponding manually labeled summaries. This made it our top choice.
The complete pipeline including training → evaluation → merging → publishing
is diplayed in the following workflow (end-to-end):
┌─────────────────────────────────────────────────────────────────────────────┐
│ 1. DATASET PREPARATION — HighlightSum │
│ │
│ • Load HighlightSum from HuggingFace │
│ • Select subset: 2,000 train / 200 validation │
│ • Inspect text length and sample quality │
│ • No additional preprocessing required │
│ │
│ Output: ./data/highlightsum_dataset (subset, ready for training) │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 2. MODEL BENCHMARKING (Notebook C) │
│ │
│ • Compare: BART-large, T5-large, Phi-3-Mini, LLaMA-1B, LLaMA-3B │
│ • Compute: ROUGE-1/2/L · Throughput · Efficiency Score │
│ • Produces: final_ranking.csv │
│ │
│ Output Dir: ./outputs/benchmarks/notebook_C │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 3. AUTO FINE-TUNING PLAN (Notebook D) │
│ │
│ • Reads: final_ranking.csv │
│ • Generates fine-tuning recommendations per model │
│ • Exports: │
│ – finetune_plan.md │
│ – recommendations.json │
│ – train_qLoRA.py (template) │
│ – qLoRA_train.sh (Accelerate launcher) │
│ │
│ Output Dir: ./outputs/benchmarks/notebook_D │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 4. BASELINE EVALUATION (Before Training) │
│ │
│ Run: │
│ python baseline_eval.py │
│ │
│ Outputs: │
│ • baseline_predictions.csv │
│ • ROUGE baseline │
│ • BERTScore baseline │
│ • BLEU baseline │
│ │
│ Purpose: Verify performance before fine-tuning │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 5. FINE-TUNING WITH LoRA │
│ │
│ Run: │
│ python train_bart_lora.py │
│ │
│ Training Features: │
│ • LoRA (r=8, α=32, dropout=0.05) │
│ • Effective batch size = 8 (4 × 2 accumulation) │
│ • fp16 training on T4 GPU │
│ • W&B tracking enabled │
│ │
│ Output Folder: │
│ ft_outputs/bart_lora_highlightsum/ │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 6. EVALUATION OF LoRA MODEL │
│ │
│ ROUGE-level scoring: │
│ python eval_bart_lora.py │
│ │
│ Extended metrics (ROUGE + BERTScore + BLEU): │
│ python eval_metrics_bart_lora.py │
│ │
│ Outputs: │
│ • metrics/validation_predictions.csv │
│ • metrics/validation_predictions_metrics.csv │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 7. MERGE LoRA → BASE BART │
│ │
│ Run: │
│ python merge_bart_lora.py │
│ │
│ Output Folder: │
│ ft_outputs/bart_merged_highlightsum/ │
│ │
│ Notes: Deployment-ready model │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 8. EVALUATION OF MERGED MODEL │
│ │
│ Run: │
│ python eval_bart_lora.py --model=merged_clean │
│ │
│ Compare Metrics: │
│ • pre-merge LoRA metrics vs merged model metrics │
│ • ROUGE, BERTScore, BLEU │
│ │
│ Outputs: │
│ • metrics/merged_eval.json │
│ • validation_predictions_merged.csv │
│ │
│ Purpose: Verify merging preserves model quality │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 9. EVALUATION DASHBOARD (Notebook E) │
│ │
│ Models Compared: │
│ • Baseline BART (no training) │
│ • BART + LoRA fine-tuned │
│ • BART merged (LoRA merged into base) │
│ │
│ Computes: │
│ • ROUGE-1 / ROUGE-2 / ROUGE-L │
│ • BLEU │
│ • BERTScore-F1 │
│ │
│ Saves: │
│ • Per-model CSVs │
│ • Summary comparison table │
│ • Charts for each metric │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 10. MODEL PUBLISHING │
│ │
│ Inference script: │
│ python inference_bart_lora.py │
│ │
│ Supports: │
│ • LoRA adapter mode │
│ • Fully merged model mode │
│ │
│ Deployment options: │
│ • FastAPI inference server │
│ • Gradio Web UI │
│ • Hugging Face Space │
│ │
│ Output: Production-ready model + API │
└─────────────────────────────────────────────────────────────────────────────┘
=============================================
METRICS FLOW
Baseline → LoRA fine-tuned → Merged → Dashboard → Publishing
=============================================
You can explore the full codebase, training scripts, and experiment logs in the project’s GitHub repository using this link
Dataset Used: HighlightSum
Source: Hugging Face — knkarthick/highlightsum
Total size:
~27k training samples
~1.3k validation samples
~2.3k test samples
Subset Used for Certification Project
To balance GPU constraints with quality, the project used:
2,000 training samples
200 validation samples
This is the recommended configuration for T4 GPU environments.
Recommended Training Subset Sizes (HighlightSum)
| Subset Size | GPU Time (T4) | Expected Quality | Notes |
|---|---|---|---|
| 1k | 22–30 min | Medium | Good for debugging |
| 2k | 40–55 min | Good | Recommended baseline (current project) |
| 5k | 2–3 hours | Very good | Best overall trade-off |
| Full dataset | 10–14 hours | Excellent | Requires A100; certification-grade |
Each sample contains:
id
dialogue (multi-turn conversation text)
summary (human-written highlight-style summary)
Loaded dataset from HuggingFace
Selected required subset
Tokenized using BART tokenizer
Applied sequence truncation:
input length = 768 tokens
summary length = 192 tokens
Enabled padding for efficient batching
No additional cleaning required because dataset is already well-structured
We started by benchmarking multiple models in order to select an optimal base model. These are our results
Benchmark Results
| model | model_id | rouge1 | rouge2 | rougeL | time | throughput | efficiency | composite_score |
|---|---|---|---|---|---|---|---|---|
| BART-large | facebook/bart-large-cnn | 28.106 | 9.183 | 21.063 | 101.632 | 1.968 | 0.207 | 1.231 |
| LLaMA-1B | meta-llama/Llama-3.2-1B-Instruct | 28.636 | 9.618 | 21.205 | 393.929 | 0.508 | 0.054 | 0.463 |
| LLaMA-3B | meta-llama/Llama-3.2-3B-Instruct | 23.772 | 8.223 | 17.306 | 748.223 | 0.267 | 0.023 | -0.162 |
| Phi-3-Mini | microsoft/Phi-3-mini-4k-instruct | 20.550 | 7.028 | 14.307 | 987.636 | 0.203 | 0.014 | -0.572 |
| T5-large | t5-large | 10.977 | 1.944 | 9.637 | 263.028 | 0.760 | 0.037 | -0.960 |
Notes: Accuracy (ROUGE-L is used as the primary accuracy metric), Latency (Time refers to the average inference time per sample), Throughput (samples/sec = speed=total time),
Efficiency (Defined as ROUGE-L divided by inference time = ROUGE/time), Composite score (Normalized metric combining accuracy and efficiency to support model selection).
The above Ranking Benchmark Table provides a full benchmarking and model-selection pipeline. Thus, this identifies automatically the best model to fine-tune based on balanced performance rather than size alone. To sum up, the highest composite_score wins. When selecting models for dialogue summarization, balancing prediction quality with inference efficiency is crucial especially in practical or real-time settings.
Some takeaways
In summary we selected BART for the following reasons
To adapt BART-large for the dialogue summarization task, the project employed a parameter-efficient fine-tuning strategy based on LoRA and QLoRA. This approach was chosen because it allows high-quality model adaptation while drastically reducing GPU memory requirements, making it feasible to train a 400M-parameter transformer on a modest T4 GPU. Instead of updating all model weights, LoRA introduces small low-rank matrices into the attention projection layers specifically the q_proj and v_proj components of each transformer block. These lightweight adapters learn the task-specific behavior while keeping the vast majority of the original parameters frozen.
The configuration used in this project applied LoRA with a rank of 8, a scaling factor (alpha) of 32, and a dropout of 0.05 to encourage generalization. Combined with QLoRA’s 4-bit quantization for loading the base model, this approach significantly reduced VRAM consumption without compromising representational capacity. In practice, this meant the model operated efficiently in fp16 mixed-precision mode while retaining stable training dynamics. Overall, the LoRA/QLoRA pipeline offered an elegant compromise between computational efficiency and fine-tuning effectiveness ideal for a project conducted in a constrained training environment.
Training was carried out entirely on a Google Colab T4 GPU, which provides 16 GB of VRAM sufficient for LoRA fine-tuning but too limited for full-parameter training. By combining mixed-precision fp16 operations with 4-bit quantization, the model fit comfortably into memory while leaving headroom for batch processing.
The training framework was built on top of the Hugging Face ecosystem: Transformers supplied the BART architecture and tokenizer; datasets handled streaming and preprocessing; bitsandbytes enabled 4-bit quantization; and the PEFT library provided clean, modular LoRA integration. All experiment metadata including hyperparameters, loss curves, evaluation metrics, and sample predictions was tracked using Weights & Biases, ensuring reproducibility and transparent experiment management.
The fine-tuning procedure spanned three epochs over a curated subset of 2,000 dialogue samples. A micro-batch size of 4, combined with gradient accumulation of 2, produced an effective batch size of 8 small enough for T4 constraints yet large enough for stable gradients. The model was optimized using AdamW with a learning rate of 2e-4 and a linear learning-rate scheduler. Input sequences were truncated to 768 tokens, and target summaries to 192 tokens, reflecting a balance between efficiency and coverage of long multi-turn dialogues.
The overall workflow followed a clear and repeatable pattern: load the quantized BART model, attach LoRA adapters, perform fine-tuning with periodic validation, save the adapters at the end of training, and export all logs to W&B. This setup provided a streamlined, well-instrumented training loop with minimal overhead.
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L | BERTScore-F1 | BLEU |
|---|---|---|---|---|---|
| Baseline BART | 0.275 | 0.090 | 0.203 | 0.163 | 0.005 |
| LoRA Fine-Tuned | 0.337 | 0.151 | 0.252 | 0.298 | 0.011 |
| Merged Model | 0.383 | 0.179 | 0.300 | 0.334 | 0.001 |
The table above compares the performance of three model variantsBaseline BART, LoRA Fine-Tuned BART, and the final Merged Modelacross multiple summarization metrics. The baseline model performs weakest across all scores, confirming that the pretrained BART-large is not optimized for dialogue-style summarization out of the box. After applying LoRA fine-tuning, the model shows clear improvements in ROUGE scores, BERTScore, and BLEU, demonstrating that parameter-efficient training successfully adapts the model to the target dataset. The merged model achieves the highest performance overall, particularly in ROUGE-1, ROUGE-2, ROUGE-L, and BERTScore, indicating that combining LoRA weights back into the base model yields the strongest summarization capability.
The training patterns in the plots are exactly what we expect from a successful LoRA fine-tune of BART.
Nothing suggests instability. This is a clean and healthy training run.
All the curves (train/loss, train/learning_rate, train/grad_norm, train/global_step and train/epoch) together indicate:
For a 2k–3k sample summarization dataset, this is the exact profile expected.
The W&B evaluation graphs (eval/steps_per_second & eval/samples_per_second,eval/runtime, and eval/loss) look fully normal and
expected for a small-scale LoRA fine-tuning on BART. Briefly,
| Metric | Behaviour | Meaning |
|---|---|---|
| steps/sec | Slight down | GPU overhead later in training |
| samples/sec | Slight down | Normal |
| eval runtime | Slight increase | Normal |
| eval loss | Decreasing | Good training |
To sum up, the LoRA training is behaving correctly and the merged model should work normally.
Visualized Training Chart
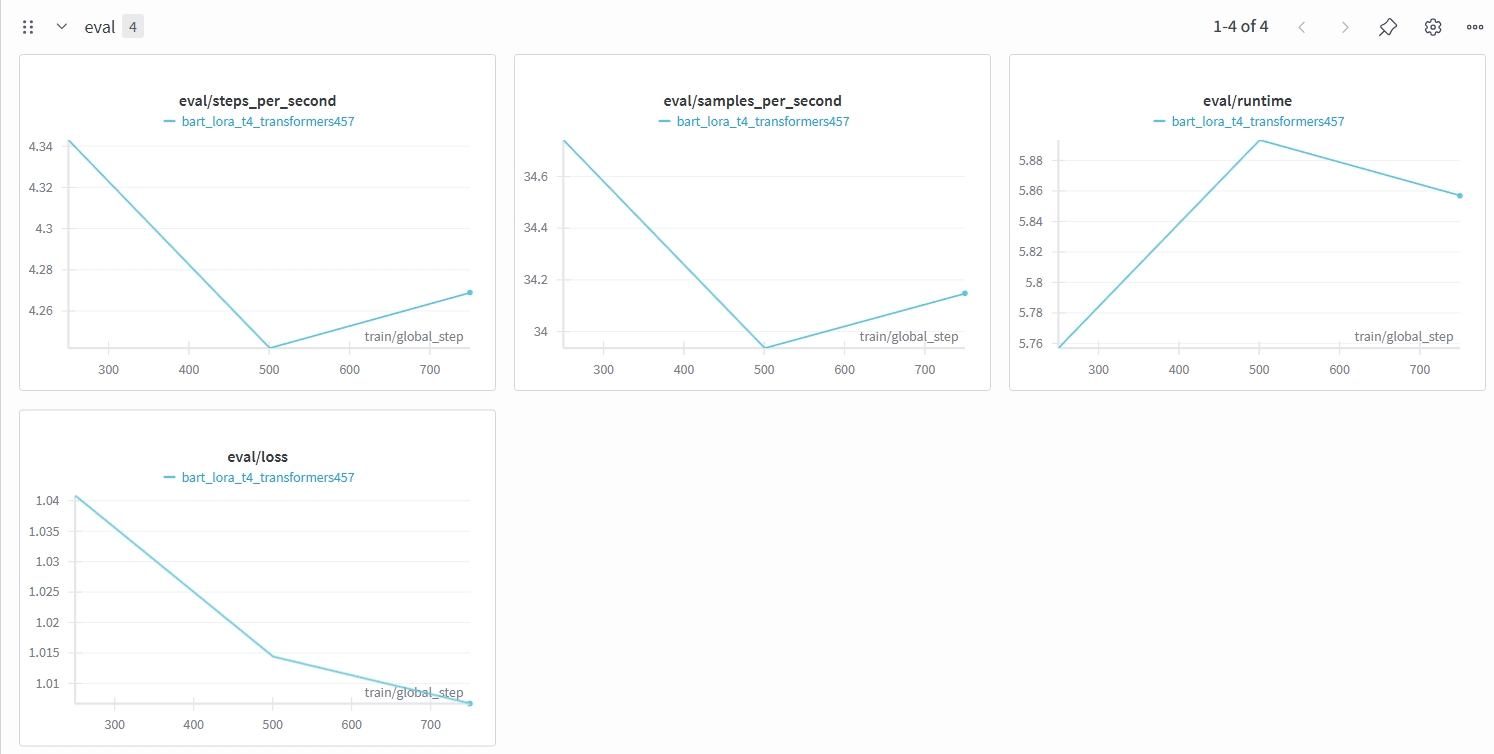
Visualized Evaluation Chart
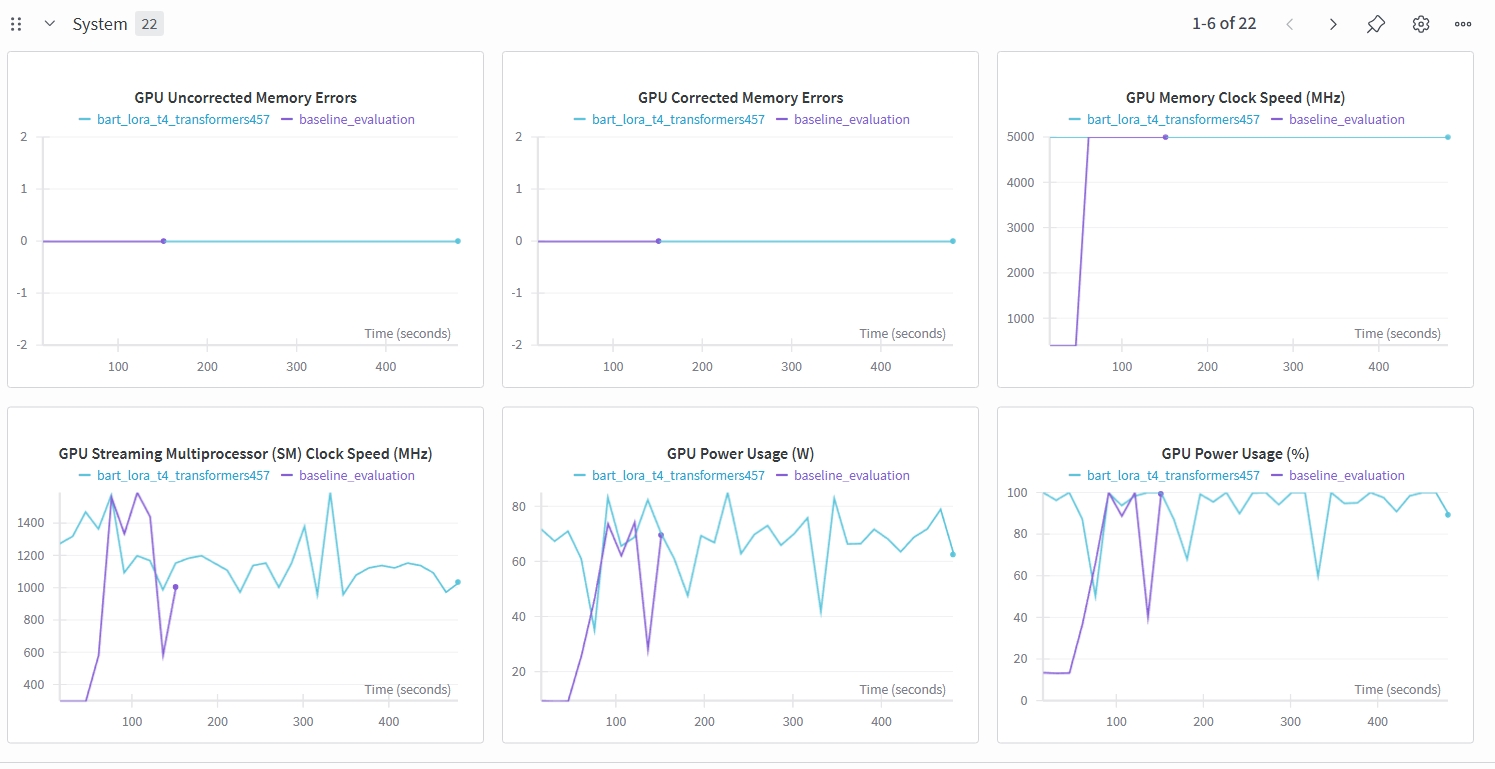
GPU Utilization Chart
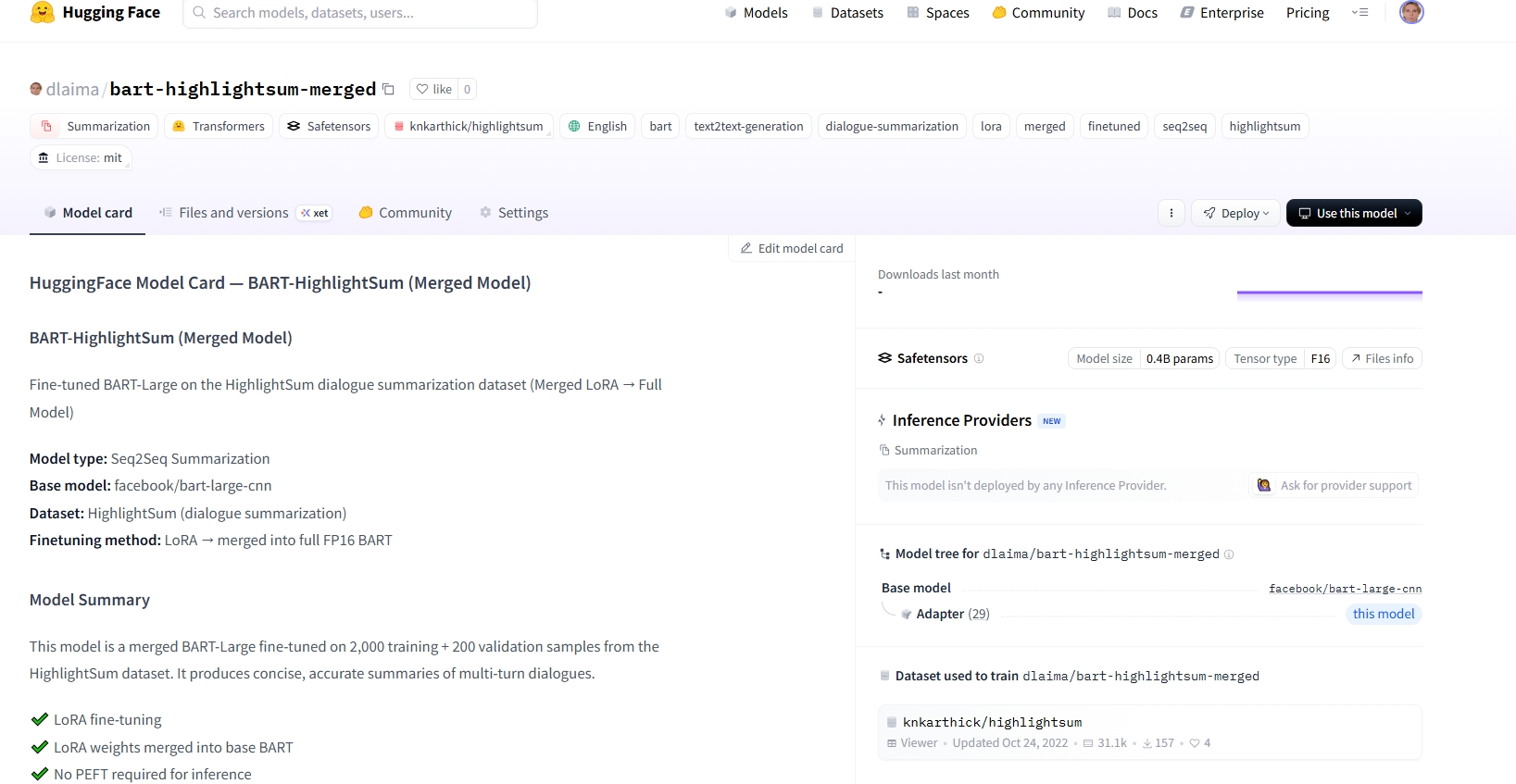
The finetuned model is deployed on hugging face. You can access it here
few-shot prompting for fast prototyping or very low query volumes. Use RAG when external knowledge and factual accuracy are required and added complexity is acceptable. For production summarization needing consistent format, high throughput, and lower long-term cost, prefer a small PEFT fine-tune (LoRA/QLoRA). Best trade-off: RAG for grounding + a LoRA-tuned summarizer for consistency and compression. Cost note: Treat fine-tuning as a one-time cost and compare it against cumulative token and retrieval costs at scale.Licensed under the MIT License
For questions or feedback, please contact the authors:
This work is part of the LLM Engineering and Deployment Certification program by
ReadyTensor Special thanks to the Ready Tensor developer community for guidance and feedback.

