This project presents SustainaRAG, a lightweight Retrieval-Augmented Generation (RAG) assistant designed to help SMEs explore and design sustainable business strategies. By leveraging LangChain, FAISS, and Hugging Face LLMs, the tool retrieves answers from a curated ESG/CSR document set via a simple Streamlit UI.
SustainaRAG indexes sustainability reports and answers user questions using vector similarity search and LLM responses. It’s ideal for researchers, CSR consultants, and SMEs looking to accelerate sustainability insights without deep technical know-how.



“Figure 1: SustainaRAG answering a query about examples of corporate responsibility best practices.”
As of 2024, compliance with the EU Corporate Sustainability Reporting Directive (CSRD) has become mandatory for large EU and non-EU companies operating in Europe. However, SMEs face significant challenges accessing structured guidance.
This tool offers early-stage support for SMEs attempting to align with ESG frameworks such as the EU Taxonomy, GRI, and SFDR. By providing a simple retrieval-based interface, SustainaRAG helps bridge the gap between regulatory expectations and operational implementation.
CSR and ESG reports are long, inconsistent, and fragmented. SMEs often lack tools or expertise to parse and operationalize them effectively. SustainaRAG solves this by offering a semantic search interface powered by a RAG pipeline.
The system was tested using a small curated dataset of multiple PDF reports from EU institutions, CSR policy frameworks, and industry case studies. These were converted to text, chunked (~500 tokens), and embedded via SentenceTransformers.
Documents were loaded using LangChain’s PyPDFLoader, chunked into overlapping segments (500 tokens, 50 overlap), embedded using HuggingFace SentenceTransformers (all-MiniLM-L6-v2), and stored in a FAISS index. Metadata (title, source) was retained for future traceability.
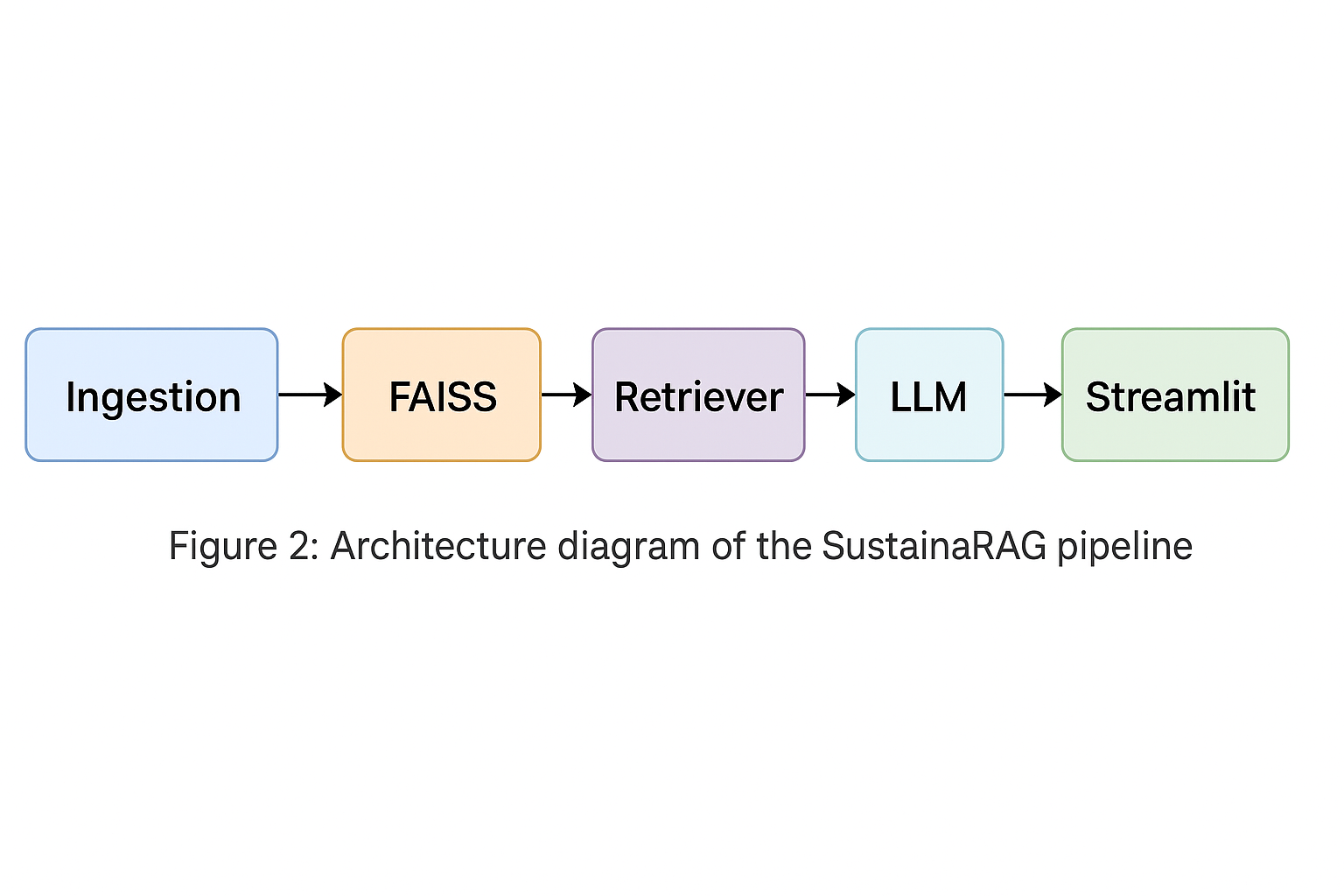
“Figure 2: Architecture diagram of the SustainaRAG pipeline.”
SustainaRAG uses a curated corpus of multiple sustainability documents sourced from publicly available European Union CSR frameworks, ESG guidelines, and industry-specific reports. These include regulatory texts, case studies from multinational companies, and implementation roadmaps.
Documents were converted to text (via PDF parsing), chunked into ~500-token passages with overlap, and embedded using SentenceTransformers. The FAISS index stores embeddings and associated metadata.
Documents were loaded using LangChain’s PyPDFLoader, chunked with overlap (500 tokens, 50 overlap), embedded using all-MiniLM-L6-v2, and stored in a FAISS index. Metadata fields (title, source) were preserved for traceability.
uv pip install -r requirements.txtstreamlit run app.py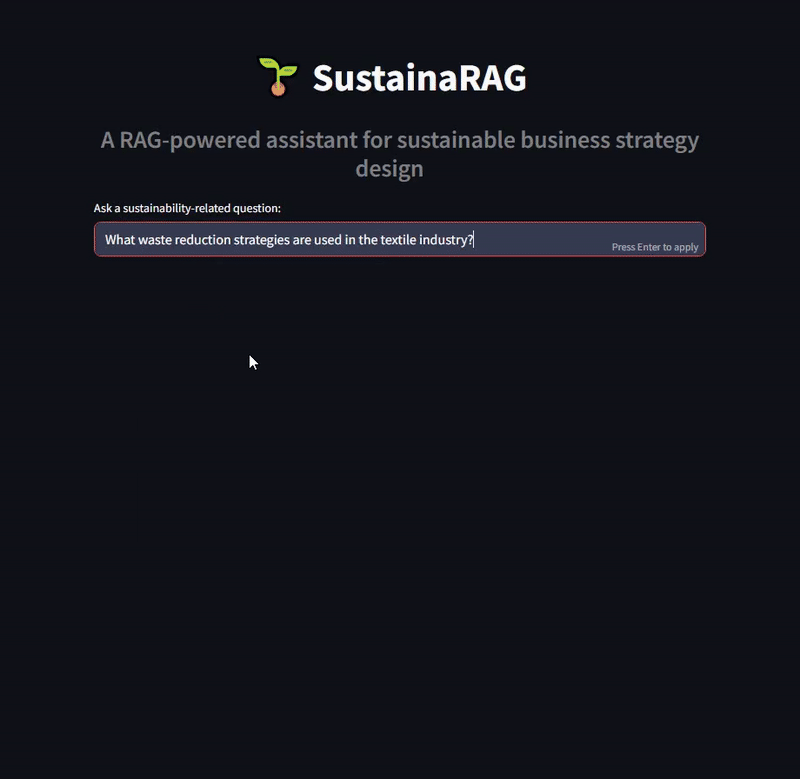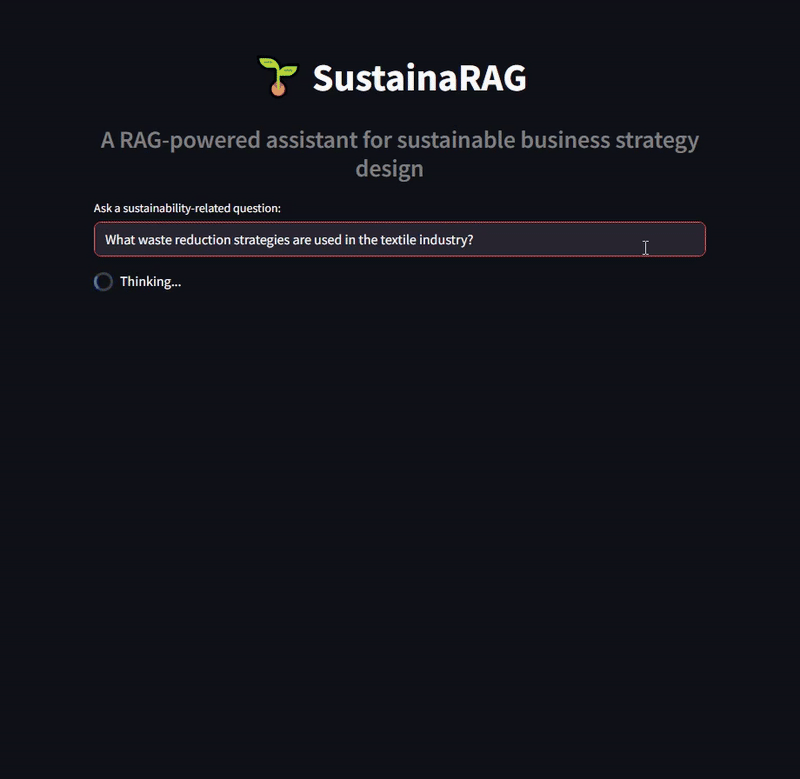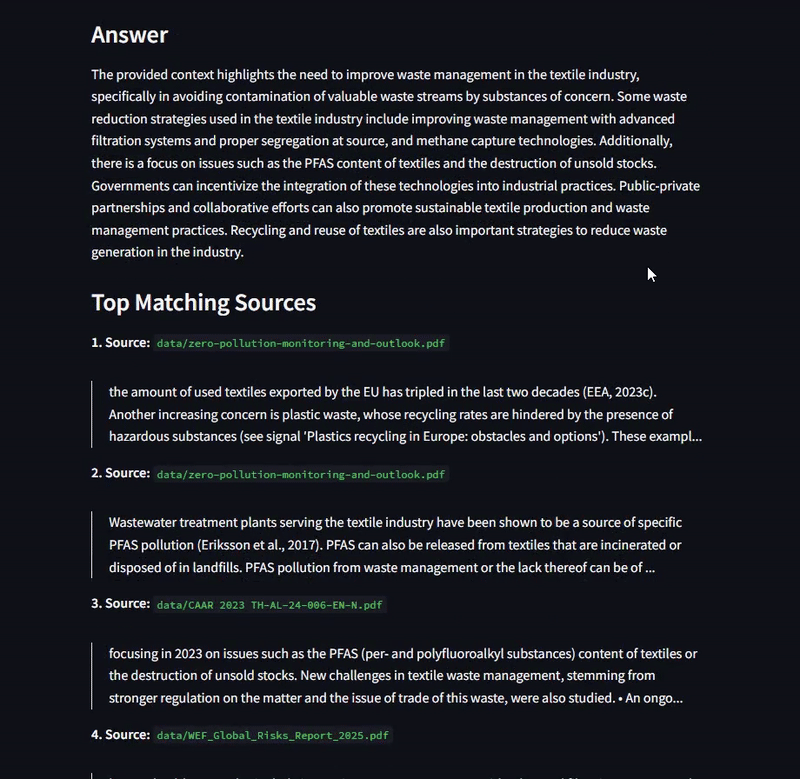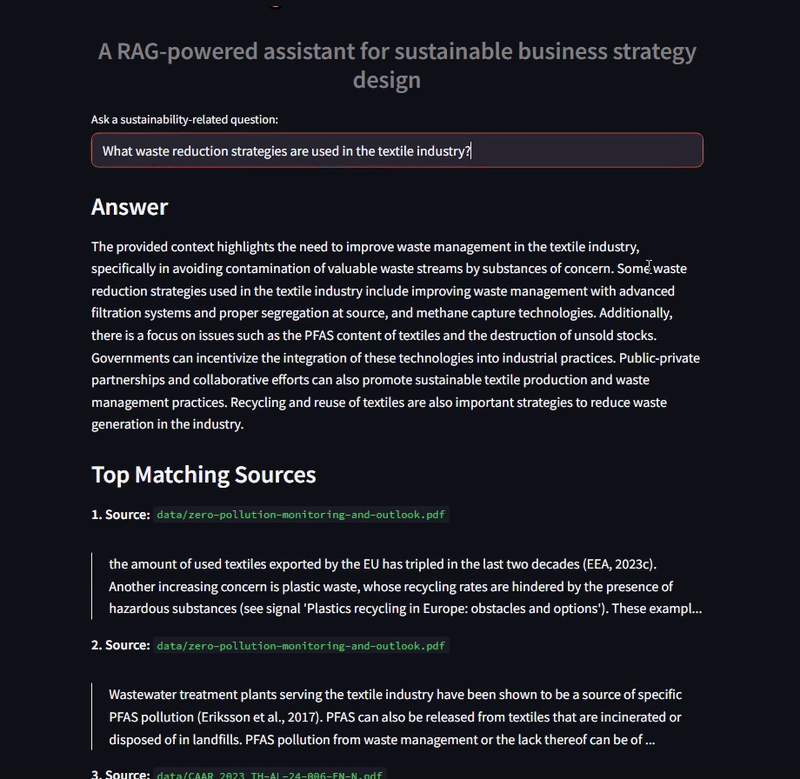
The assistant was evaluated manually across 20 ESG/CSR questions using a set of test queries. The quality of answers was judged based on semantic correctness, relevance to retrieved documents, and completeness. Future work includes integrating user feedback loops and automatic relevance scoring.
Performance Observations:
Success: Correct retrieval for “3 pillars of sustainability” with concise LLM-generated summary.
Failure: CSRD 2024-specific queries failed due to lack of latest source inclusion.
Contact:
https://github.com/kostas696