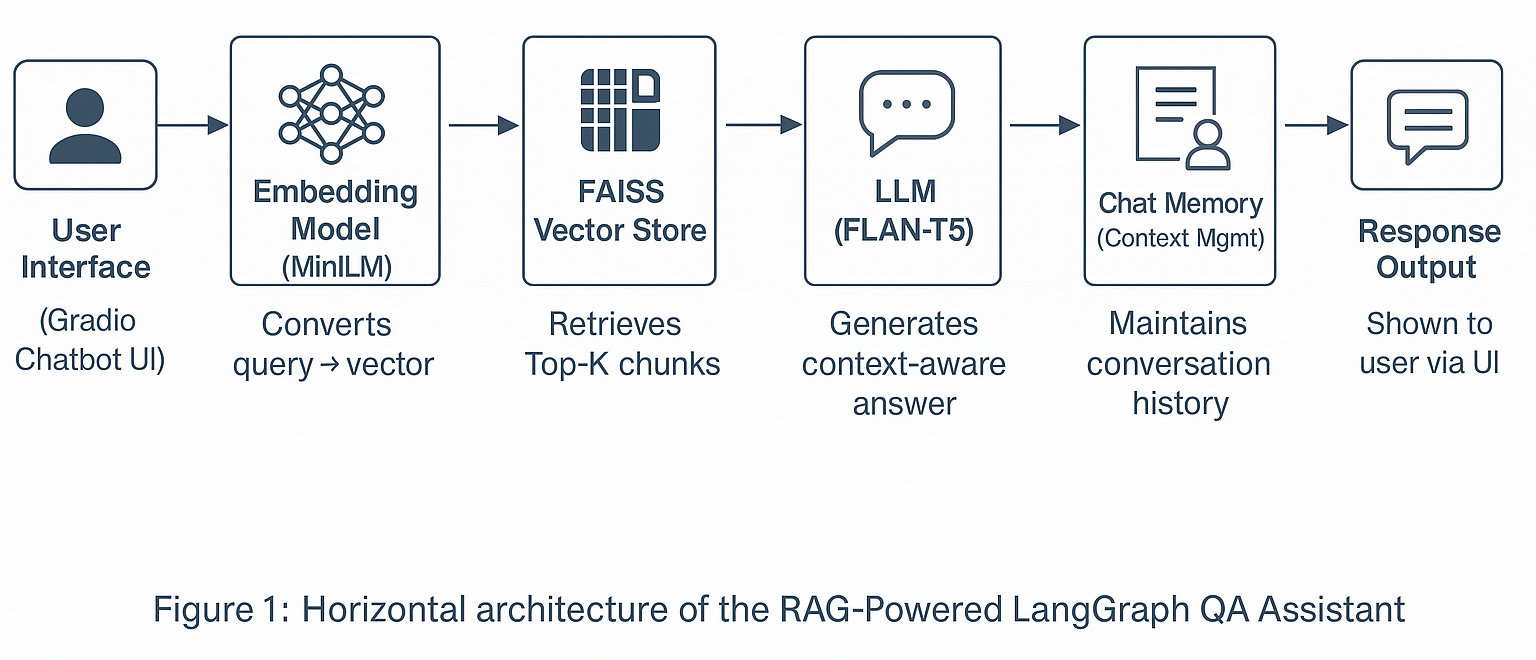
This project introduces a LangGraph-Based Retrieval-Augmented Generation (RAG) QA Assistant — an intelligent assistant capable of delivering accurate and context-aware answers from LangGraph documentation.
Unlike generic QA bots, this assistant emphasizes privacy-preserving local computation, combining:
It demonstrates how an offline RAG pipeline can power efficient, explainable, and domain-specific AI assistants.
While LLMs like GPT or Gemini excel in general-purpose reasoning, they lack:
The goal of this project is to build a local, explainable RAG-based QA system that:
| Layer | Functionality |
|---|---|
| Document Loader & Chunker | Splits input text into overlapping chunks (500 chars, 100 overlap) |
| SentenceTransformer Embeddings | Converts text into vector representations |
| FAISS Vector Index | Enables fast top-k retrieval |
| FLAN-T5 Model | Generates structured, context-aware answers |
| Memory Buffer | Maintains short-term conversational history for contextual continuity |
| Evaluation Layer | Computes cosine similarity scores between query and retrieved chunks |
| UI (Gradio) | Enables interactive QA experience with sidebar examples |
To improve coherence, the text is split into overlapping chunks — ensuring that critical information spanning boundaries isn’t lost during retrieval.
def chunk_text(text, size=CHUNK_SIZE, overlap=OVERLAP): """Split text into overlapping chunks for better context retention.""" paragraphs = text.split("\n\n") chunks = [] for para in paragraphs: para = para.strip() if not para: continue start = 0 while start < len(para): end = min(len(para), start + size) chunks.append(para[start:end]) start += size - overlap return chunks
The system encodes document chunks using a SentenceTransformer model and normalizes vectors to improve retrieval accuracy. If an existing FAISS index is found, it’s reused for faster startup.
embedder = SentenceTransformer(EMBED_MODEL_NAME) embeddings = np.array(embedder.encode(docs_list, show_progress_bar=True), dtype="float32") embeddings = normalize(embeddings, axis=1) index = faiss.IndexFlatIP(embeddings.shape[1]) index.add(embeddings)
The assistant uses an in-memory store (chat_memory) to maintain the last three conversation turns, improving contextual continuity.
It also calculates retrieval similarity scores to measure how relevant the fetched context was.
chat_memory = [] def evaluate_retrieval_quality(question, context): """Calculate cosine similarity between query and retrieved context.""" q_vec = embedder.encode([question]) c_vec = embedder.encode([context]) score = cosine_similarity(q_vec, c_vec)[0][0] return round(float(score), 4)
The assistant constructs a detailed prompt with:
A strong system instruction (to prevent hallucination)
Previous chat memory
The retrieved document chunks as context
It then uses FLAN-T5-small to generate the final answer.
def generate_answer(question, top_k=TOP_K, max_new_tokens=300): q_vec = np.array([embedder.encode(question)], dtype="float32") q_vec = normalize(q_vec, axis=1) D, I = index.search(q_vec, k=min(top_k, len(docs))) context = "\n\n".join([docs[int(idx)] for idx in I[0] if idx < len(docs)]) retrieval_score = evaluate_retrieval_quality(question, context) conversation_context = " ".join([f"User: {q}\nAI: {a}" for q, a in chat_memory[-3:]]) prompt = ( STRONG_SYSTEM_INSTRUCTION + "\n\n" f"PREVIOUS CONVERSATION:\n{conversation_context}\n\n" f"CONTEXT:\n{context}\n\n" f"QUESTION: {question}\n\nAnswer now:" ) inputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=1024) outputs = model.generate(**inputs, max_new_tokens=max_new_tokens, num_beams=4) answer = tokenizer.decode(outputs[0], skip_special_tokens=True) chat_memory.append((question, answer)) return f"{answer}\n\n🧭 Retrieval Similarity Score: {retrieval_score}"
Overlapping Context Chunking for better retrieval precision
FAISS Vector Store for high-speed similarity search
Semantic Embedding Normalization to reduce drift in vector space
Conversation Memory (chat_memory) to retain multi-turn context
Retrieval Quality Scoring to measure answer reliability
Robust Prompting with hallucination prevention instructions
Interactive Gradio UI with sidebar examples for quick evaluation
Internal Documentation Assistants — for teams using LangGraph or internal AI frameworks
Developer Onboarding Tools — helping new members learn project architecture quickly
Enterprise Knowledge Bases — local, secure, RAG-powered assistants for restricted data
Education & Research — a template for understanding RAG pipelines and retrievers
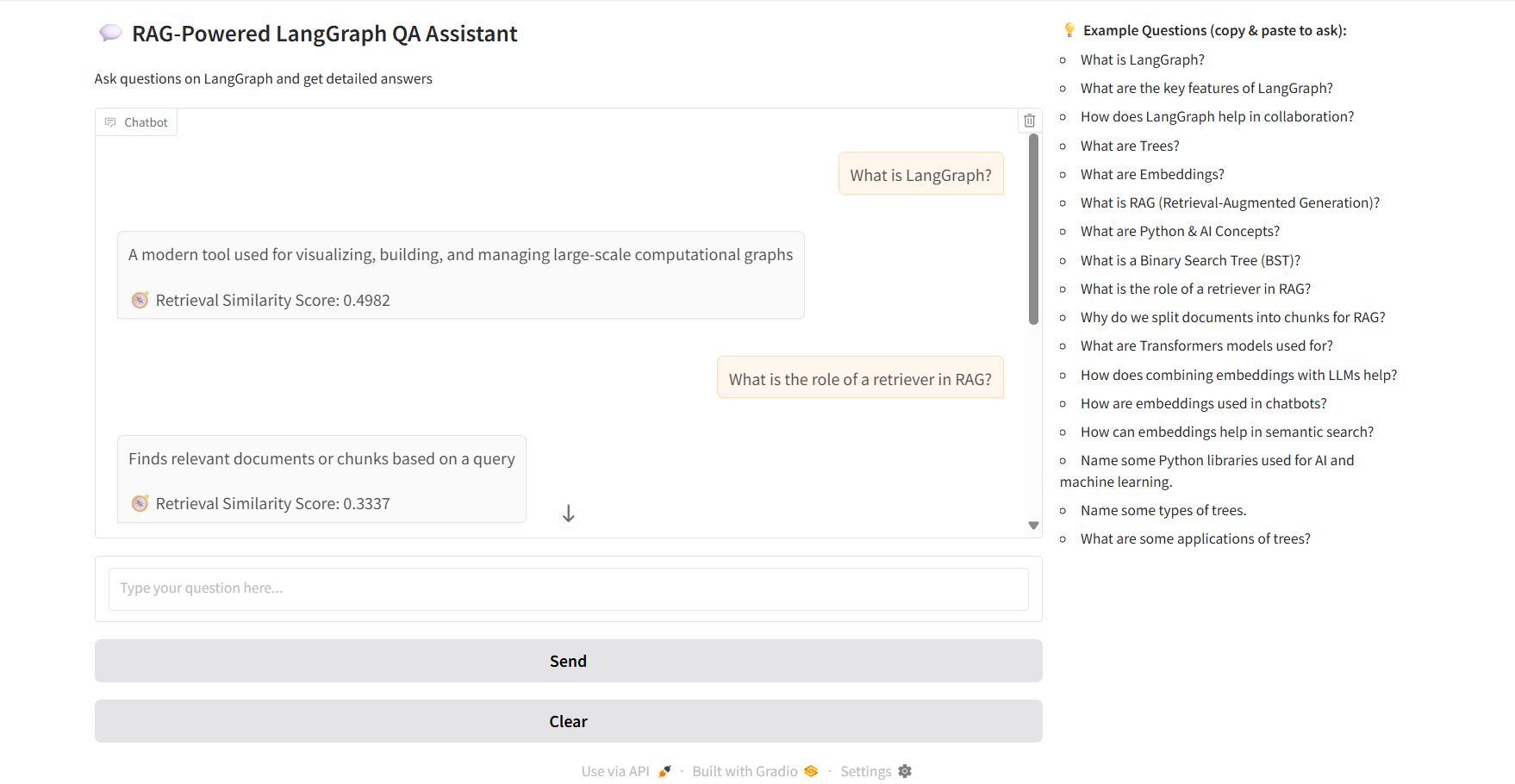
RAG-Powered LangGraph QA Assistant UI :
The complete working code for this RAG-powered LangGraph QA Assistant can be accessed on GitHub:
Clone or download to run the project locally.
This assistant showcases how LangGraph and RAG principles can be merged to create a powerful, explainable, and privacy-preserving knowledge retrieval system.
It introduces retrieval evaluation, context memory, and modular configuration, offering a strong foundation for context-aware, domain-specific assistants.
By integrating memory management and retrieval evaluation directly into the workflow, this system demonstrates practical strategies to manage conversation history and maintain context — key aspects of building truly interactive, reasoning-aware AI assistants.