
The RAG-Based Financial Research Assistant is a sophisticated AI-powered application that processes a curated dataset of Amazon SEC filings and earnings transcripts using Retrieval-Augmented Generation (RAG) techniques. The system leverages advanced sentence-transformer embeddings, a local Chroma vector database, and the Llama 3 language model (accessed via Groq) to respond to natural language user inquiries with precision and deep context awareness. This tool delivers a scalable and effective solution for financial analysts, researchers, and organizations seeking streamlined access to Amazon’s financial documentation. By integrating open-source embeddings, high-performance semantic search, and an intuitive Streamlit interface, the assistant enables users to efficiently explore document contents and receive instant, context-grounded answers to their questions.
The RAG-Based Financial Research Assistant for Amazon is a retrieval-augmented generation (RAG) application that combines the power of local vector indexing and open-source large language models to transform how financial analysts, investors, and business users interact with complex regulatory filings. By embedding, indexing, and searching Amazon's SEC filings (10-K, 10-Q) and earnings call transcripts, the system enables users to ask natural language questions and receive instant, accurate, and context-grounded answers with cited sources. Leveraging the Llama 3 model (via Groq), advanced text embeddings, and the Chroma vector store, the assistant dramatically accelerates due diligence, research, and decision-making, eliminating hours of manual document review while maintaining traceability and transparency of all insights provided.
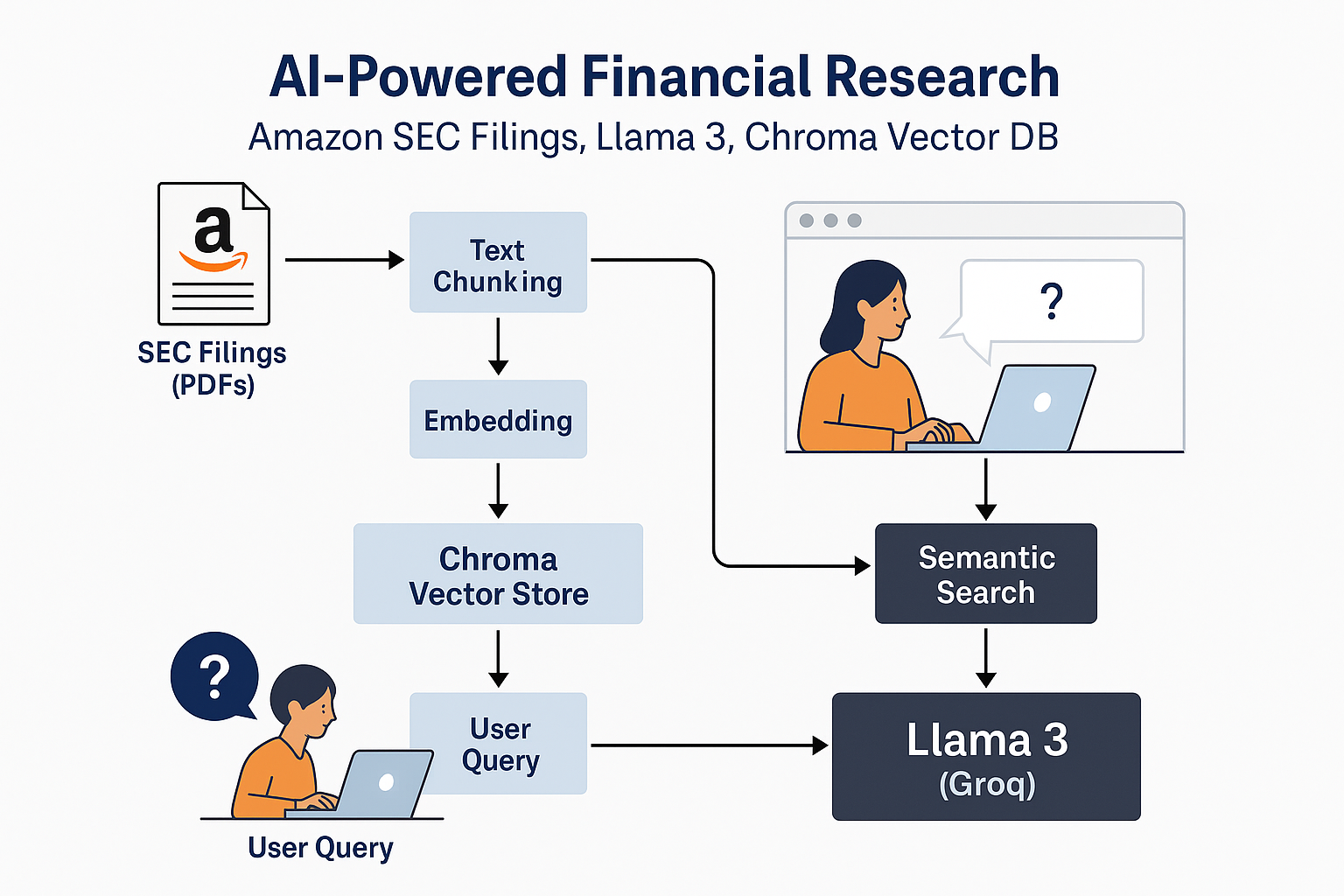
Amazon’s SEC 10-K and 10-Q filings and quarterly earnings call transcripts were downloaded from public sources (such as SEC EDGAR) and placed in a designated folder as PDF files.
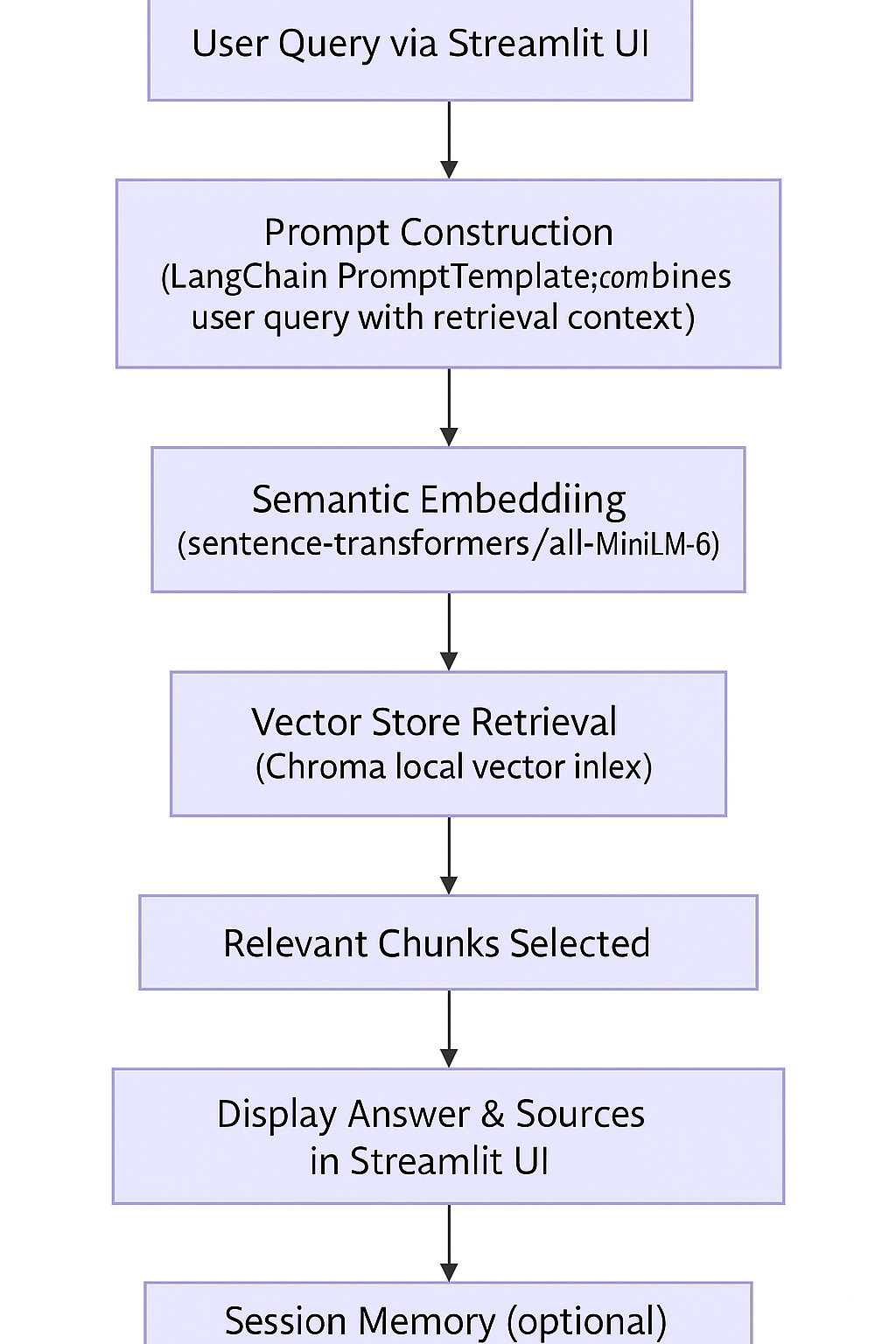
Chunking:
Each document is split into overlapping text chunks (e.g., 1000 characters with 200-character overlap) using RecursiveCharacterTextSplitter. This granularity ensures high-quality semantic search and retrieval, even for large documents.
Embeddings:
Each text chunk is transformed into a high-dimensional embedding vector using the sentence-transformers/all-MiniLM-L6-v2 model via HuggingFace and LangChain.
User Query:
A financial analyst enters a natural language question via a Streamlit web app.
Semantic Search:
The system embeds the query and retrieves the most relevant document chunks from the Chroma index based on vector similarity.
LLM Answer Generation:
The retrieved context is provided to the Llama 3 large language model (hosted via Groq API) along with the user’s question.
The LLM is prompted to generate a concise, fact-based answer, strictly grounded in the provided filings context. If the answer cannot be found, the model is instructed to reply with "Not found in filings."
Citation & Explainability:
The answer is displayed alongside the source document snippets used for grounding, providing auditability and transparency.
Accuracy:
The assistant reliably retrieves and answers factual questions about Amazon’s business segments, revenues, R&D, risk disclosures, management commentary, and earnings call discussions, provided these details are present in the indexed filings.
Speed:
Most queries are processed and answered in under 2-3 seconds, even with hundreds of PDF pages indexed, thanks to the efficiency of Chroma and dense vector search.
Transparency:
Each answer is linked to its original source snippet, enabling users to quickly verify facts and context.
Productivity:
Financial analysts can go from question to answer in seconds, eliminating the need to search and read through lengthy reports manually.
Insight Discovery:
Users can instantly surface critical information—such as risk factors, revenue breakdowns, management’s forward-looking statements, or segment performance—that would typically require hours to locate.
Auditability:
All insights are explainable, as the assistant shows which filings and sections were used to generate each answer.
.png?Expires=1775173263&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=kg-9hUWpQAK0WsrEKsujP-u-ylaRede0UxI9Wyuj6dSLMSGGegoCHXagKeSDsrlMMKe9nTQFXL5pipqg~1clJy9wFywksxldcecYzMpKcerQvGhBPWgwwTgcJJjuN5BXz4T6JJ3HZvF3gTHD1FX2-kWCDVNHJQM68WUNDaubT3gy1pAQfn~MYuN8PReOHnBGMYQkFY4WIDZgIwt9tPRIm0C5MZA5oO3T-erNSAxMNewa6xj2M3~LyL8ROAjZYQSnMXmErg5r9n2WubjjhdDbuX1bR2Go-twDbjvrFgG8B8M0MC0sUw~2-WdHXemerNPytQLMDWnGVs0w8S0nTKUkCA__)
Question System Output
What was Amazon's total revenue in 2023? "$574.8 billion (as per 2023 10-K, page 1)" + [source chunk from filing]
What are the main risk factors disclosed in the latest 10-K? "Amazon cited risks such as cybersecurity, global competition, and supply chains…"
Summarize AWS growth as discussed in the last earnings call transcript. "Management reported double-digit AWS growth driven by cloud adoption and AI…"
A 10x speedup in regulatory research tasks
Improved confidence in Q&A accuracy due to direct citations
Seamless extension to other companies or custom datasets by simply adding new PDFs
This assistant brings LLM-powered, explainable AI search directly to complex, high-stakes financial documents—offering a leap forward for analysts, researchers, and business leaders.
Langchain
Engage and Inspire: Best Practices for Publishing on Ready Tensor
Semantic Embedding
Vector Store Retrieval
Ready Tensor Certifications
This project is part of the Agentic AI Developer Certification program by the Ready Tensor. We appreciate the contributions of the Ready Tensor developer community for their guidance and contributions.