This project presents a specialized Retrieval-Augmented Generation (RAG) assistant designed to provide high-fidelity answers derived exclusively from indexed research publications. By utilizing a ReAct-based agentic architecture, the system eliminates general world-knowledge hallucinations, ensuring that the assistant only responds using content retrieved from the specifically activated publication—in this case, "Building CLIP from Scratch".
The architecture is divided into two distinct pipelines: Data Ingestion and Agentic Reasoning. This separation ensures that only pre-validated, filtered data enters the model's context window.
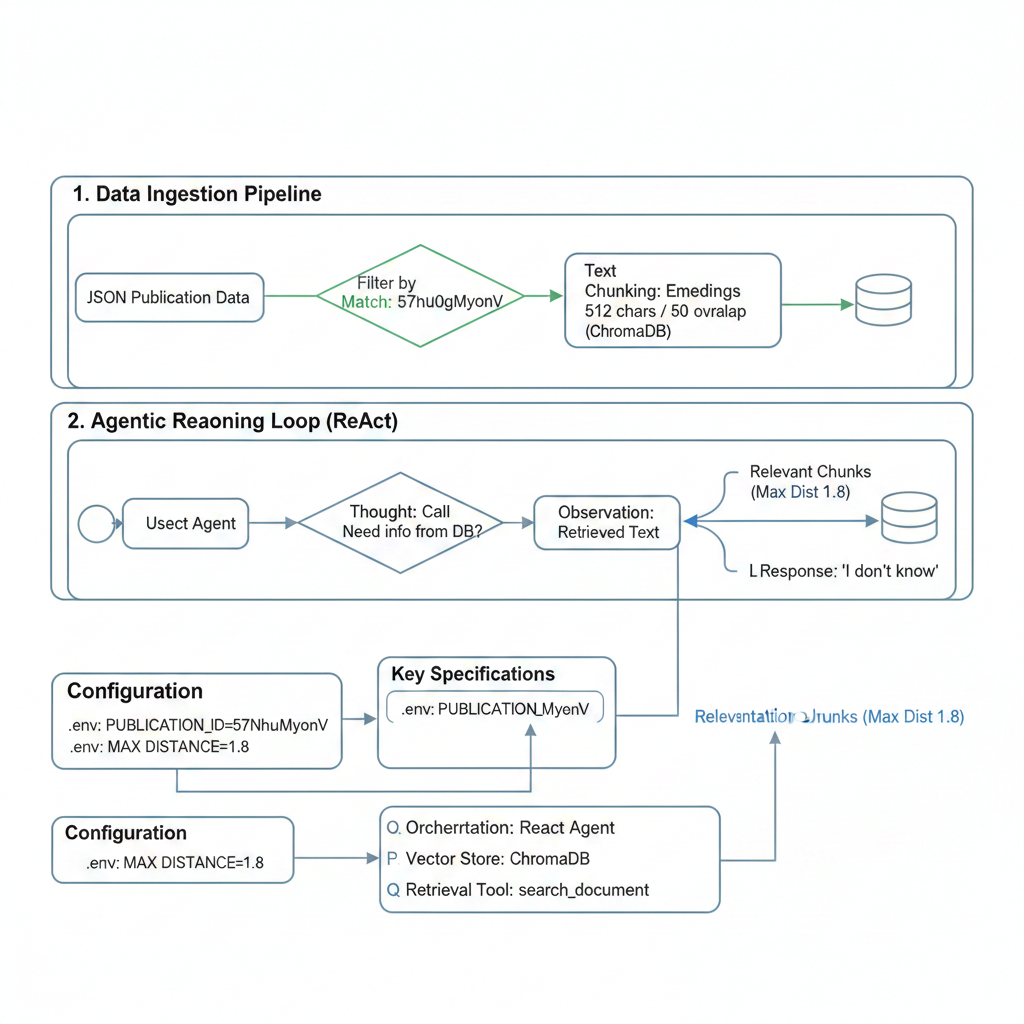
Publication Isolation: The system loads a comprehensive JSON dataset but filters content based on a PUBLICATION_ID defined in the .env configuration.
Embedding & Storage: Filtered text is transformed into vector embeddings and stored in ChromaDB, which serves as the "Sole Source of Truth".
The assistant does not answer queries directly. It follows a Thought-Action-Observation loop:
Thought: The LLM determines what information is needed to answer the query.
Action: The search_document tool is invoked to query the vector database.
Observation: The agent reviews the specific text chunks retrieved by the tool.
Final Answer: A summary is generated based only on the observation. If no data is found, the system defaults to a deterministic "I don't know".
Text Chunking Strategy
To resolve the feedback regarding methodology clarity, the following specific parameters were implemented to optimize retrieval:
512 characters. This size was selected to capture distinct technical concepts without exceeding the context window of the embedding model.
50 characters. This "sliding window" approach ensures that semantic meaning is preserved even if a sentence is split between two chunks.
The retrieval tool uses a Max Distance of 1.8 to ensure that only chunks with high semantic similarity are presented to the agent.
The assistant accurately answers publication-specific questions while rejecting out-of-scope queries with deterministic “I don’t know” responses. This confirms reliable grounding, reduced hallucination risk, and predictable production behavior.
| Query Type | Example Question | System Response | Outcome |
|---|---|---|---|
| In-Scope | """How does CLIP align images and text?""" | Details from publication chunks | ✅ Accurate Retrieval |
| Out-of-Scope | """What is the capital of India?""" | """I don't know""" | ✅ No Hallucination |
| Out-of-Scope | """Who invented Transformers?""" | """I don't know""" | ✅ Knowledge Gatekeeping |
No Hallucinations: The agent is strictly forbidden from using world knowledge.
Dynamic Configuration: The PUBLICATION_ID can be hot-swapped via .env to pivot the entire assistant's knowledge base to a different paper instantly.
Token Efficiency: By limiting MAX_CHUNKS (default: 5), the system prevents token explosion and reduces inference costs.