GitHub Repository: samrat-kar/rag-domain-qa-assistant
Large Language Models (LLMs) are powerful but have a critical blind spot: they can only answer from what they were trained on. When you ask them about private documents, proprietary knowledge, or niche domains not well-covered in their training data, they either hallucinate confidently wrong answers or admit they don't know. This is a fundamental limitation for any real-world enterprise or domain-specific use case.
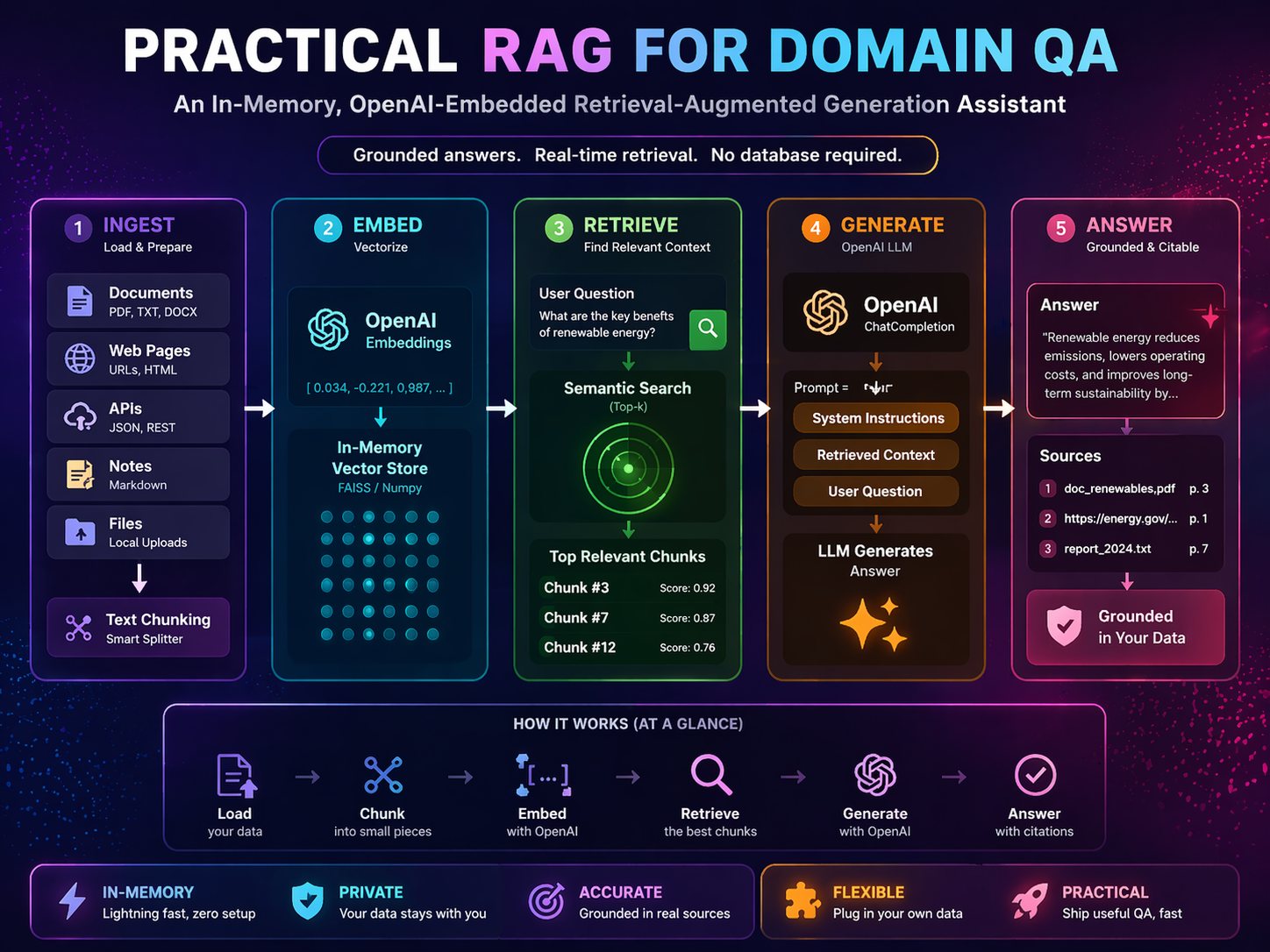
Retrieval-Augmented Generation (RAG) solves this by combining two complementary strengths: the precision of search (finding the right information) and the fluency of generation (turning that information into a clear, coherent answer). Instead of relying on memorized weights, the model is given the relevant text at query time and asked to reason over it.
This project implements a clean, minimal RAG pipeline from scratch — covering document ingestion, semantic chunking, vector embedding, cosine-similarity retrieval, and grounded LLM generation — with the goal of building a working, understandable baseline for document question-answering.
Build and evaluate a simple, reproducible RAG assistant that answers user questions exclusively from a provided local document corpus, grounding every response in retrieved evidence rather than model-memorized knowledge.
Ask domain-specific questions over a curated multi-topic document collection and receive grounded, cited answers that can be traced back to source files.
Generic LLM responses are unreliable for niche domains and private documents. A model trained on public internet data cannot know the contents of your internal files, proprietary reports, or specialized corpora — and when asked, it will often fabricate plausible-sounding but incorrect answers (hallucination).
This project directly addresses that limitation by retrieving relevant text passages from user-provided documents before generation. The model is constrained to answer only from the retrieved context, which:
.env.All documents are local .txt files in the data/ directory, covering seven distinct knowledge domains:
| File | Domain |
|---|---|
artificial_intelligence.txt | AI, ML, LLMs, deep learning, ethics |
biotechnology.txt | Genomics, CRISPR, biotech applications |
climate_science.txt | Climate change, greenhouse gases, impacts |
quantum_computing.txt | Qubits, quantum algorithms, hardware |
sample_documents.txt | General reference |
space_exploration.txt | Missions, rockets, space science |
sustainable_energy.txt | Renewables, solar, wind, energy storage |
Using documents from seven distinct domains allows meaningful cross-domain retrieval testing. A query about machine learning should retrieve from artificial_intelligence.txt and not confuse it with content from quantum_computing.txt — validating that embedding-based retrieval is doing semantic work and not just keyword matching.
.txtThe pipeline follows a standard RAG flow, decomposed into seven sequential stages. Each stage has a clear input, transformation, and output.
What happens: The RAGAssistant.load_documents() method scans the data/ directory and reads every supported file (.txt, .csv, .json, .md) as UTF-8 text. Each file is stored as a dict with a content field and a metadata field containing the source filename and path.
Why: Keeping loading generic (plain text, no parsing) maximizes compatibility across document types and avoids format-specific failure modes during ingestion.
What happens: Each document's text is passed to VectorDB.chunk_text(), which uses LangChain's RecursiveCharacterTextSplitter with a chunk size of 500 characters and 50-character overlap, splitting on \n\n, \n, . , , and "" in that priority order.
Why chunking matters: Embedding an entire multi-page document into a single vector loses retrieval precision — the vector represents an average of all topics in the document. Smaller, focused chunks give embeddings that represent tighter semantic concepts, making retrieval dramatically more accurate.
Why overlap matters: A 50-character overlap ensures that sentences or ideas spanning a chunk boundary are not cut off mid-thought. This preserves local context and prevents information loss at boundaries.
Why recursive splitting: Splitting on paragraph breaks first (\n\n), then line breaks, then sentences, then words preserves the natural structure of the text. It avoids mid-sentence splits unless absolutely necessary, keeping chunks more semantically coherent than naive fixed-length slicing.
What happens: All chunks are batch-embedded using OpenAI's text-embedding-3-small model via OpenAIEmbeddings.embed_documents(). The resulting vectors are stored as a NumPy float32 matrix.
Why OpenAI embeddings: text-embedding-3-small is a production-quality, semantically rich embedding model. It maps text into a 1536-dimensional space where semantically similar texts cluster together — the foundation of meaningful retrieval.
Why float32 NumPy: For small-to-medium corpora, a dense NumPy matrix is fast, simple, and requires no external vector database infrastructure. It keeps the system self-contained and easy to inspect.
What happens: The VectorDB maintains three parallel in-memory lists (_documents, _metadatas, _ids) plus the NumPy embedding matrix (_embeddings). All chunk data is aligned by index position.
Why in-memory: For this assignment's scope (7 documents, ~tens of chunks), an in-memory index provides instant lookup with zero infrastructure overhead. The design can be replaced with a persistent vector database (e.g., Chroma, Pinecone, Weaviate) for larger workloads without changing the rest of the pipeline.
What happens: When a user submits a question, it is embedded using the same text-embedding-3-small model (embed_query()). The query vector is compared against all stored document vectors using cosine similarity:
similarity(q, d) = (q · d) / (||q|| × ||d||)
The top-k chunks ranked by similarity are selected and returned.
Why cosine similarity: Cosine similarity measures the angular distance between two vectors, ignoring their magnitude. This is ideal for text embeddings because it captures semantic direction (what the text is about) independently of text length or embedding scale. Two chunks that discuss the same concept will point in similar directions in embedding space, even if one is longer.
Why top-k (not just top-1): Providing multiple retrieved chunks gives the LLM richer context. A single chunk might partially answer a question; three chunks together may span the full answer across paragraph boundaries. The default n_results=3 balances context richness against prompt length.
What happens: The retrieved chunks are joined with --- separators into a context string. This context plus the user's question are inserted into a ChatPromptTemplate:
You are a helpful assistant. Use only the provided context to answer the question.
If the context does not contain enough information, say so honestly rather than making up an answer.
Context:
{context}
Question: {question}
Provide a clear, concise answer based on the context provided.
The prompt is passed through a LangChain chain (prompt | llm | StrOutputParser) to gpt-4o-mini at temperature 0.2, and the answer string is extracted.
Why temperature 0.2: Lower temperature makes the model more deterministic and factual — appropriate for QA where consistency and accuracy matter more than creativity.
Why explicit grounding instructions: The prompt explicitly tells the model to use only the provided context and to admit when context is insufficient. This is the key RAG safety mechanism that suppresses hallucination — without it, the model may blend retrieved context with memorized training data.
What happens: The query() method returns a dict containing the answer text, the raw context chunks, and the unique set of source filenames that contributed to the retrieved context.
Why return sources: Source attribution is essential for verifiability. Users can inspect which documents the answer came from and cross-check if needed. It also supports debugging — if an answer is wrong, checking sources quickly reveals whether the problem is in retrieval (wrong chunks) or generation (model misread correct chunks).
The corpus spans seven distinct knowledge domains — AI, Biotechnology, Climate Science, Quantum Computing, Space Exploration, Sustainable Energy, and General Reference. Each domain is stored in a separate .txt file. During ingestion, the extract_domain() function in src/vectordb.py maps each source filename to a human-readable domain label:
| Source File | Domain Label |
|---|---|
artificial_intelligence.txt | AI |
biotechnology.txt | Biotechnology |
climate_science.txt | Climate Science |
quantum_computing.txt | Quantum Computing |
space_exploration.txt | Space Exploration |
sustainable_energy.txt | Sustainable Energy |
sample_documents.txt | General |
This domain label is stored in the metadata of every chunk at index time, so every retrieved chunk carries its domain origin.
The VectorDB.search() and ChromaKnowledgeBase.search() methods both accept an optional domain_filter parameter. When set, only chunks belonging to that domain are considered during ranking — non-matching chunks are masked before the cosine similarity sort.
# Restrict retrieval to Biotechnology documents only result = assistant.query("How does CRISPR work?", domain_filter="Biotechnology") # See all available domain labels in the current index print(assistant.list_domains()) # ['AI', 'Biotechnology', 'Climate Science', 'Quantum Computing', ...]
In demo.py, the interactive CLI also supports domain-tag prefixes:
You: [AI] What is backpropagation?
(Filtered to domain: AI)
Assistant: ...
For queries that naturally span multiple domains (e.g., "How is AI used in climate science?"), no filter should be applied — the embedding model handles cross-domain routing implicitly. The domain_filter parameter is optional and defaults to None (full corpus search).
The original in-memory VectorDB is fully functional for small corpora and learning use cases, but re-embeds all documents on every startup. The new ChromaKnowledgeBase in src/knowledge_base.py provides a persistent alternative backed by ChromaDB.
from src.knowledge_base import ChromaKnowledgeBase from src.app import RAGAssistant # Build a persistent knowledge base (embeddings saved to ./chroma_db/) kb = ChromaKnowledgeBase(persist_dir="./chroma_db") assistant = RAGAssistant(store=kb) assistant.load_and_ingest("./data") # only runs once; subsequent startups reuse the index
Both stores share the same interface (add_documents(), search(), list_domains()), so RAGAssistant works with either without any other changes.
ChromaKnowledgeBase.add_documents() checks which source files are already indexed and skips them automatically. This means:
VectorDB (in-memory) | ChromaKnowledgeBase (persistent) | |
|---|---|---|
| Persistence | No — re-embeds on every run | Yes — index survives restarts |
| Incremental updates | No | Yes — skips already-indexed sources |
| Infrastructure | None | Local ./chroma_db/ directory |
| Best for | Learning, quick demos | Production, larger corpora |
Passing the raw user question directly to the embedding model works well for clear, concise queries, but fails for:
QueryProcessor.rewrite() in src/query_processor.py uses the LLM to rephrase a query into a more precise, retrieval-friendly form before embedding:
# Enable at init time assistant = RAGAssistant(use_query_processor=True) # Or per-query result = assistant.query("Tell me about energy", rewrite_query=True) print(result["retrieval_query"]) # → "What are the main sources and technologies of sustainable energy?"
The rewritten query is embedded for retrieval; the original question is still used for the LLM generation prompt, so the final answer remains natural.
QueryProcessor.decompose() splits compound or comparative questions into independent sub-queries, each of which can be retrieved separately:
from src.query_processor import QueryProcessor qp = QueryProcessor(llm) sub_queries = qp.decompose("Compare deep learning and quantum computing") # → ["What is deep learning?", "What is quantum computing?"]
Each sub-query can then be passed to assistant.query() independently and the results merged, giving the LLM richer, targeted context for each part of the comparison.
In the current implementation, each call to assistant.query() is completely independent. The assistant has no memory of previous questions or answers within a session. Every query starts fresh — only the retrieved document chunks and the current question are visible to the LLM.
This is intentional for the baseline: stateless QA is simpler, predictable, and avoids the complexity of managing conversation history. But it has a clear limitation for interactive use — the user cannot ask follow-up questions that reference prior answers.
Turn 1: "What is machine learning?" → ✅ answered from corpus
Turn 2: "Can you give me an example?" → ❌ assistant has no context of Turn 1
To support multi-turn dialogue, conversation history can be maintained as a list of prior (question, answer) pairs and injected into the prompt alongside retrieved context:
# Conceptual extension — not in current codebase history = [] def query_with_memory(assistant, question, history, n_results=3): result = assistant.query(question, n_results=n_results) history_text = "\n".join( f"Q: {h['question']}\nA: {h['answer']}" for h in history[-3:] ) # Inject history into prompt for context-aware generation history.append({"question": question, "answer": result["answer"]}) return result
This pattern — known as windowed conversation memory — keeps only the last k turns in the prompt to avoid exceeding the model's context window. LangChain provides ready-made memory classes (ConversationBufferWindowMemory, ConversationSummaryMemory) that can be plugged into the existing chain.
| Strategy | How It Works | Best For |
|---|---|---|
| No memory (current) | Each query is independent | Simple QA, batch processing |
| Window memory | Last k turns injected into prompt | Short interactive sessions |
| Summary memory | Prior turns summarised by LLM into a short paragraph | Long sessions, limited context window |
| Entity memory | Track key entities (people, topics) mentioned across turns | Domain-specific dialogue |
| External memory | Store session history in a database; retrieve relevant turns | Persistent multi-session agents |
The reasoning in this system operates at two levels:
1. Retrieval reasoning (implicit) — The embedding model reasons about semantic similarity: it maps the user's question and all document chunks into a shared vector space where conceptually related text clusters together. This is not symbolic reasoning, but it is a form of learned semantic inference — the model understands that "machine learning" and "supervised training" are related without explicit rules.
2. Generative reasoning (explicit) — Once relevant chunks are retrieved, gpt-4o-mini performs in-context reasoning over the provided text. The model can:
The temperature setting of 0.2 keeps this reasoning focused and consistent — the model follows the evidence rather than generating creative but unsupported conclusions.
| Enhancement | What It Adds |
|---|---|
| Chain-of-thought prompting | Ask the LLM to reason step-by-step before answering, improving accuracy on complex questions |
| Multi-hop retrieval | Retrieve, generate an intermediate answer, then retrieve again using that answer as a new query |
| Self-consistency | Run the same query multiple times and select the most common answer — reduces variance on ambiguous questions |
| Reasoning traces | Return the LLM's step-by-step reasoning alongside the final answer for auditability |
User Query
│
▼
[Embed Query] ──── text-embedding-3-small ────▶ Query Vector
│
▼
[Cosine Similarity Search] ──── VectorDB._embeddings ────▶ Top-k Chunks
│
▼
[Build Grounded Prompt] ──── ChatPromptTemplate ────▶ Prompt String
│
▼
[LLM Generation] ──── gpt-4o-mini (temp=0.2) ────▶ Answer Text
│
▼
[Return Answer + Sources]
Ingestion flow (one-time at startup):
data/*.txt
│
▼
[load_documents()] ──▶ Document Dicts
│
▼
[chunk_text()] ──▶ Text Chunks (500 chars, 50 overlap)
│
▼
[embed_documents()] ──▶ Float32 Vectors
│
▼
[VectorDB._embeddings] ──▶ In-Memory NumPy Matrix
src/app.py — RAGAssistantThe central orchestration class. It owns the LLM, the prompt chain, and the vector store, and exposes two main methods:
load_and_ingest(data_path) — loads documents from disk and adds them to the vector store.query(question, n_results) — runs the full RAG pipeline (retrieve → build context → generate → return).The LangChain chain (prompt | llm | StrOutputParser) makes the generation pipeline composable and easy to swap components in.
src/vectordb.py — VectorDBThe retrieval engine. Responsibilities:
chunk_text() — splits raw text into retrieval-friendly chunks.add_documents() — embeds and indexes a list of document dicts.search() — embeds a query and returns top-k chunks by cosine similarity.The class is self-contained: it manages its own embedding client and internal storage, making it independently testable.
demo.py — CLI InterfaceMinimal entry point for running the system. It:
RAGAssistant and ingests the data/ directory.| Decision | Choice | Rationale |
|---|---|---|
| Vector store | In-memory NumPy | Zero infrastructure, simple, fits the assignment scope |
| Embedding model | text-embedding-3-small | Production-quality, cost-efficient, 1536-dim |
| LLM | gpt-4o-mini | Capable, fast, cost-effective for QA tasks |
| Chunking strategy | Recursive character splitting | Preserves natural text structure better than fixed slicing |
| Chunk size | 500 chars / 50 overlap | Balances retrieval precision vs. context completeness |
| Similarity metric | Cosine similarity | Magnitude-invariant, standard for text embedding retrieval |
| LLM temperature | 0.2 | Favors accuracy and consistency over creativity |
| Retrieval k | 3 | Enough context breadth without excessive prompt length |
The system is evaluated across four layers:
RetrievalEvaluator.RetrievalEvaluatorsrc/evaluator.py provides a RetrievalEvaluator class with 13 ground-truth QA pairs covering all 7 domains. It runs each question through the full RAG pipeline and measures three metrics:
| Metric | Definition |
|---|---|
| Source Accuracy | Fraction of queries where the expected domain appears anywhere in the top-k retrieved chunks |
| Top-1 Accuracy | Fraction of queries where the expected domain is the highest-ranked retrieved chunk |
| Mean Top Similarity | Average cosine similarity of the top-ranked chunk across all queries |
from src.evaluator import RetrievalEvaluator evaluator = RetrievalEvaluator() output = evaluator.run(assistant, n_results=3) RetrievalEvaluator.print_report(output)
Sample output:
========================================================================
RETRIEVAL EVALUATION REPORT
========================================================================
[PASS] What is machine learning?
Expected : AI
Retrieved: AI
Top sim : 0.8712
[PASS] How does CRISPR gene editing work?
Expected : Biotechnology
Retrieved: Biotechnology
Top sim : 0.8541
...
------------------------------------------------------------------------
Source Accuracy (domain in top-k) : 100.00%
Top-1 Accuracy (domain ranked #1) : 100.00%
Mean Top Similarity : 0.8634
Total Queries Evaluated : 13
========================================================================
| Query | Expected Domain |
|---|---|
| "What is machine learning?" | AI |
| "How does deep learning work?" | AI |
| "What are key AI ethics concerns?" | AI |
| "What is quantum entanglement?" | Quantum Computing |
| "How do quantum computers differ from classical computers?" | Quantum Computing |
| "How does CRISPR gene editing work?" | Biotechnology |
| "What are applications of genomics in medicine?" | Biotechnology |
| "What causes climate change?" | Climate Science |
| "What are the effects of greenhouse gas emissions?" | Climate Science |
| "How does solar energy generate electricity?" | Sustainable Energy |
| "What are the benefits of wind power?" | Sustainable Energy |
| "What was the Apollo moon mission?" | Space Exploration |
| "How do rockets achieve orbit?" | Space Exploration |
For each query, the retrieved context chunks are inspected to verify:
Observed behavior across local test runs:
artificial_intelligence.txt, not space_exploration.txt).In-memory index only — The vector store is not persisted between runs. Every startup re-embeds all documents. For larger corpora or production serving, a persistent vector database (Chroma, FAISS, Pinecone) would be necessary.
No reranker — Retrieval relies solely on first-stage embedding cosine similarity. A cross-encoder reranker (e.g., a fine-tuned BERT model) could improve precision by re-scoring retrieved chunks before passing them to the LLM.
No quantitative benchmark — Evaluation is functional and qualitative. A production system would use a ground-truth QA evaluation dataset with metrics like RAGAS (faithfulness, answer relevance, context precision/recall) for rigorous measurement.
API dependency — Both embedding and generation require live OpenAI API access. An offline alternative (local embedding models via SentenceTransformers + local LLM via Ollama) would remove this dependency.
Single-hop retrieval — Complex multi-part questions that require information from multiple documents may not be fully answered by a single retrieval pass. Multi-hop or iterative RAG approaches could address this.
The system runs as a CLI tool with python demo.py. No server or database setup required. Suitable for individual use, prototyping, and learning.
| Concern | Recommendation |
|---|---|
| Persistence | Replace in-memory VectorDB with Chroma, FAISS, or Pinecone |
| Scale | Add batch embedding with rate-limit handling |
| API reliability | Add retry logic and fallback for OpenAI outages |
| Monitoring | Log query latency, retrieval latency, top-k source distribution |
| Observability | Track user feedback on answer usefulness |
| Auth | Add API key or session auth for multi-user serving |
Create a .env file in the project root:
OPENAI_API_KEY=your_key_here
OPENAI_MODEL=gpt-4o-mini
OPENAI_EMBEDDING_MODEL=text-embedding-3-small
pip install -r requirements.txt
python demo.py
The CLI will:
data/.RAG is one of the most practical and widely adopted patterns in applied LLM engineering today. It bridges the gap between general-purpose language models and domain-specific knowledge by grounding generation in retrieved evidence — making AI systems more accurate, verifiable, and trustworthy for real-world use.
This project provides a compact, readable, end-to-end RAG baseline that is:
It establishes a clean foundation for anyone building document-grounded QA systems, from learning projects to early-stage production prototypes.
This project is published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license.
| Permission | Details |
|---|---|
| Share | Copy and redistribute the material in any medium or format |
| Adapt | Remix, transform, and build upon the material |
| Attribution required | You must credit the original author and indicate if changes were made |
| NonCommercial | You may not use the material for commercial purposes |
| ShareAlike | Adaptations must be distributed under the same CC BY-NC-SA 4.0 license |
Full license text: LICENSE
In plain terms: You are free to learn from, fork, adapt, and share this project for educational, research, and non-commercial use, provided you give attribution and apply the same license to any derivative works. Commercial use (selling, productising, or monetising this code or its derivatives) is not permitted without explicit written permission.
The project builds on several open-source libraries. Their licenses are compatible with non-commercial use:
| Library | License | Notes |
|---|---|---|
| LangChain | MIT | Core abstraction for prompting and chaining |
| langchain-openai | MIT | OpenAI integration for LangChain |
| langchain-text-splitters | MIT | RecursiveCharacterTextSplitter |
| ChromaDB | Apache 2.0 | Persistent vector store |
| NumPy | BSD 3-Clause | Vector math and embedding matrix |
| python-dotenv | BSD 3-Clause | Environment variable loading |
| OpenAI Python SDK | MIT | API client for embeddings and chat |
All libraries listed above permit use, modification, and redistribution for non-commercial purposes. Refer to each library's individual license for full terms.
This project calls the OpenAI API for:
text-embedding-3-smallgpt-4o-miniUse of the OpenAI API is governed by OpenAI's Terms of Service and Usage Policies. Key points relevant to this project:
The seven .txt files in the data/ directory are educational reference documents created for this project covering publicly known topics in AI, biotechnology, climate science, quantum computing, space exploration, sustainable energy, and general science. They are included under the same CC BY-NC-SA 4.0 license as the rest of the project and may be used, adapted, or replaced for non-commercial educational purposes.
RAG Retrieval-Augmented Generation LLM OpenAI GPT-4o-mini text-embedding-3-small LangChain NLP Question Answering Document QA Vector Database Semantic Search Text Embeddings Cosine Similarity Chunking Hallucination Reduction Python Machine Learning Generative AI AI Applications