PaperPulse is a powerful and intuitive application designed to help you chat with your research papers. It leverages a Retrieval-Augmented Generation (RAG) pipeline to provide accurate, context-aware answers from your own document library. This tool is available as both a user-friendly Streamlit web application and a command-line interface (CLI).
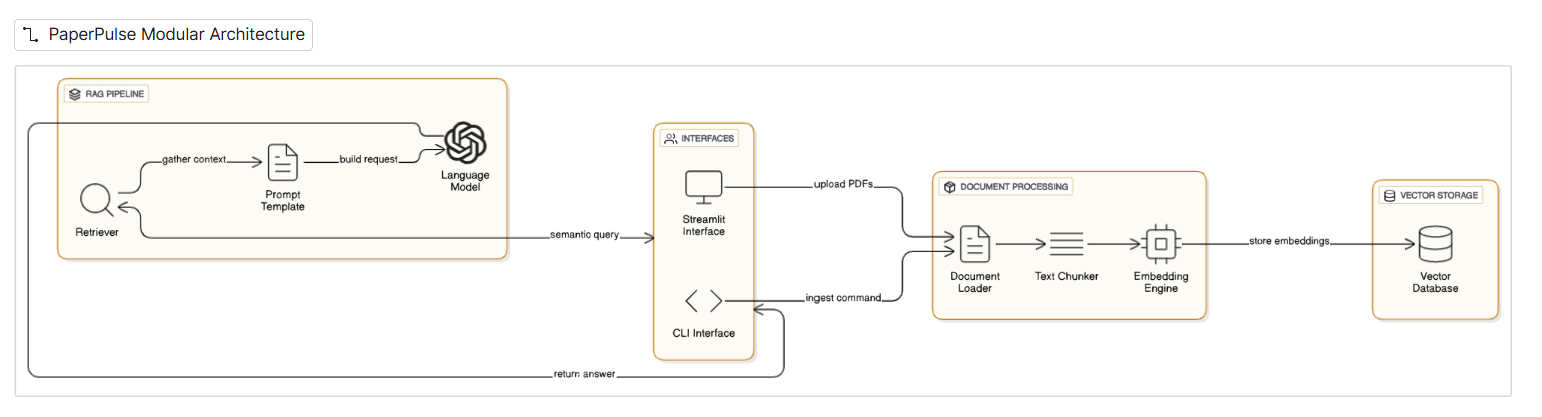
System Architecture:
PaperPulse employs a modular architecture, integrating a vector database for efficient document retrieval and a large language model for natural language understanding and generation. The system workflow begins with user queries, which are semantically encoded and matched against a corpus of scientific papers stored in the vector database. Retrieved documents are then synthesized by the language model to generate concise, accurate summaries or answers.
Technical Innovations:
PaperPulse stands out for its seamless integration of RAG with scalable vector databases, enabling real-time retrieval from large and evolving scientific corpora. The use of domain-adapted language models further enhances the accuracy and relevance of generated content. Additionally, the platform’s modular design facilitates easy adaptation to new research domains and data sources.
Evaluation and Use Cases:
In pilot deployments, PaperPulse demonstrated significant improvements in literature review efficiency, with users reporting faster discovery of relevant papers and higher satisfaction with the quality of generated summaries. The system has been adopted by research groups across multiple disciplines, including life sciences and computer science.
Key Features:
Contextual Search: PaperPulse interprets complex research queries, retrieving the most relevant literature based on semantic similarity rather than simple keyword matching.
Automated Summarization: The assistant generates clear and concise summaries of retrieved papers, helping users quickly grasp key findings and methodologies.
Citation Extraction: PaperPulse automatically identifies and formats citations for referenced works, streamlining the research writing process.
Role-Based Access Control: The system supports differentiated access levels, ensuring data privacy and compliance with institutional requirements.
all-MiniLM-L6-v2: For efficient and accurate document embeddings.Follow these steps to set up and run PaperPulse on your local machine.
git clone https://github.com/sri1991/paperpulse cd paperpulse
It's recommended to use a virtual environment to manage project dependencies.
python -m venv venv source venv/bin/activate # On Windows, use `venv\Scripts\activate`
Install the required Python packages using the requirements.txt file.
pip install -r requirements.txt
PaperPulse requires a Groq API key to function. Create a .env file in the root of the project directory and add your key:
GROQ_API_KEY="your-groq-api-key"
You can run PaperPulse in two ways:
To launch the web application, run the following command in your terminal:
streamlit run app.py
This will open the PaperPulse interface in your web browser, where you can:
The CLI is ideal for programmatic access or for users who prefer the terminal.
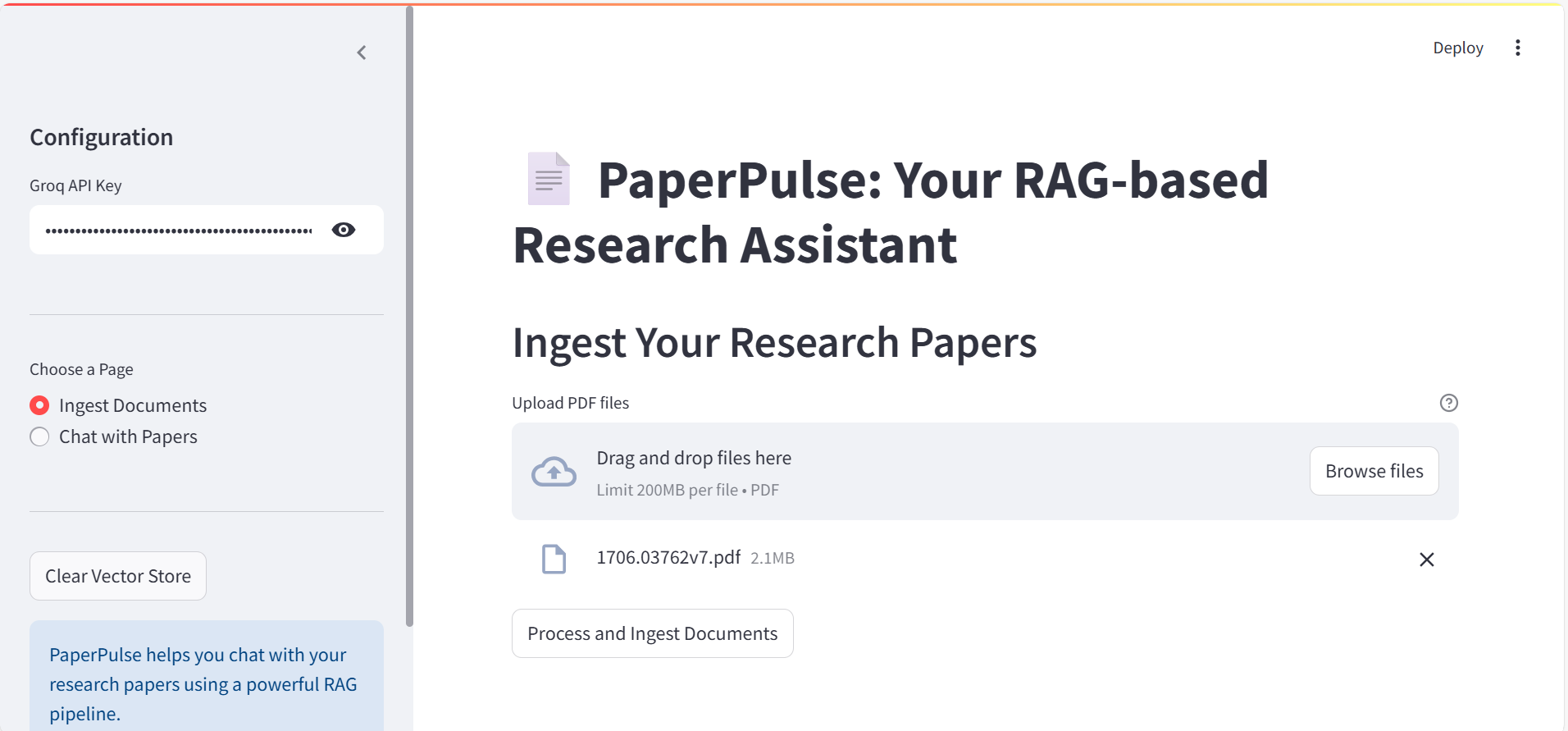
To process and ingest documents from a directory, use the ingest command:
python paperpulse.py ingest path/to/your/papers
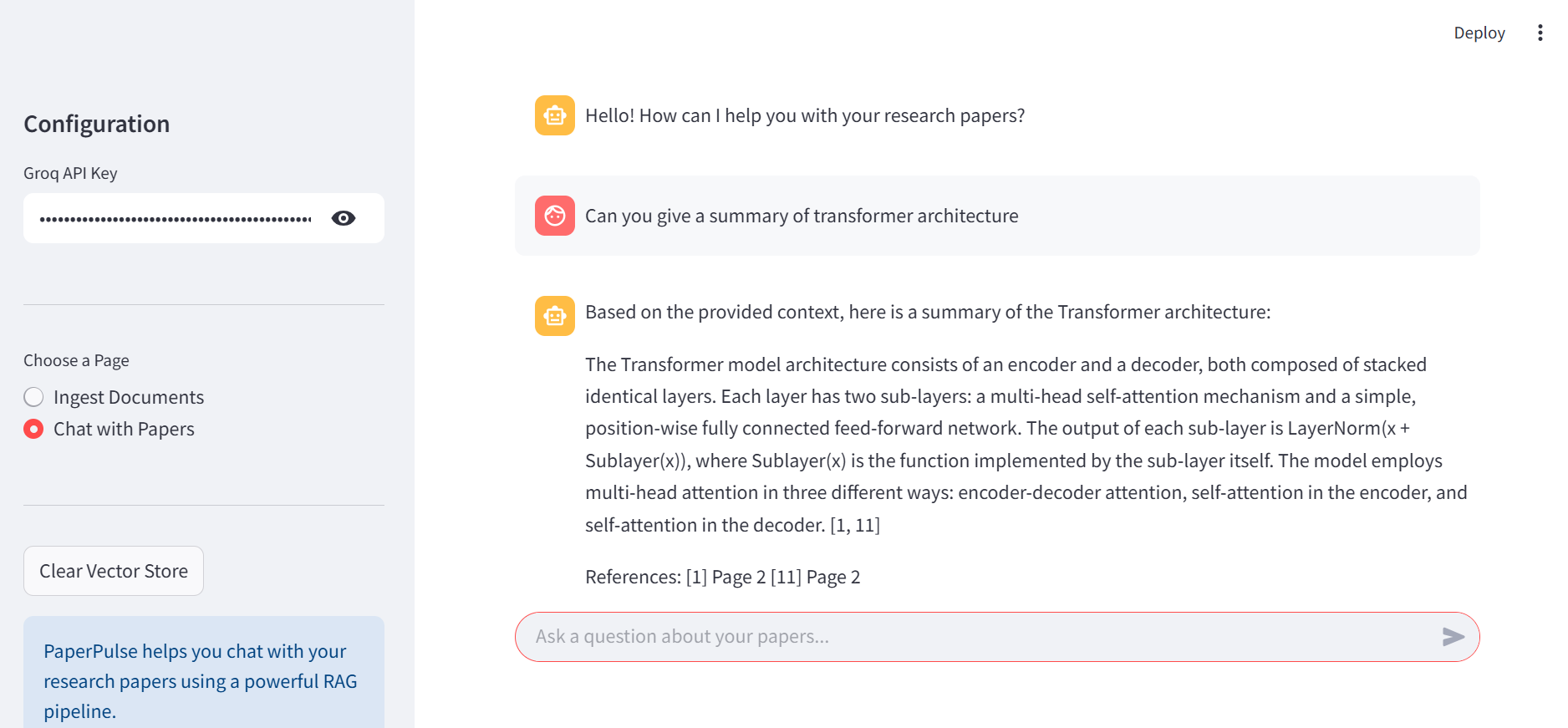
To start an interactive chat session, use the query command:
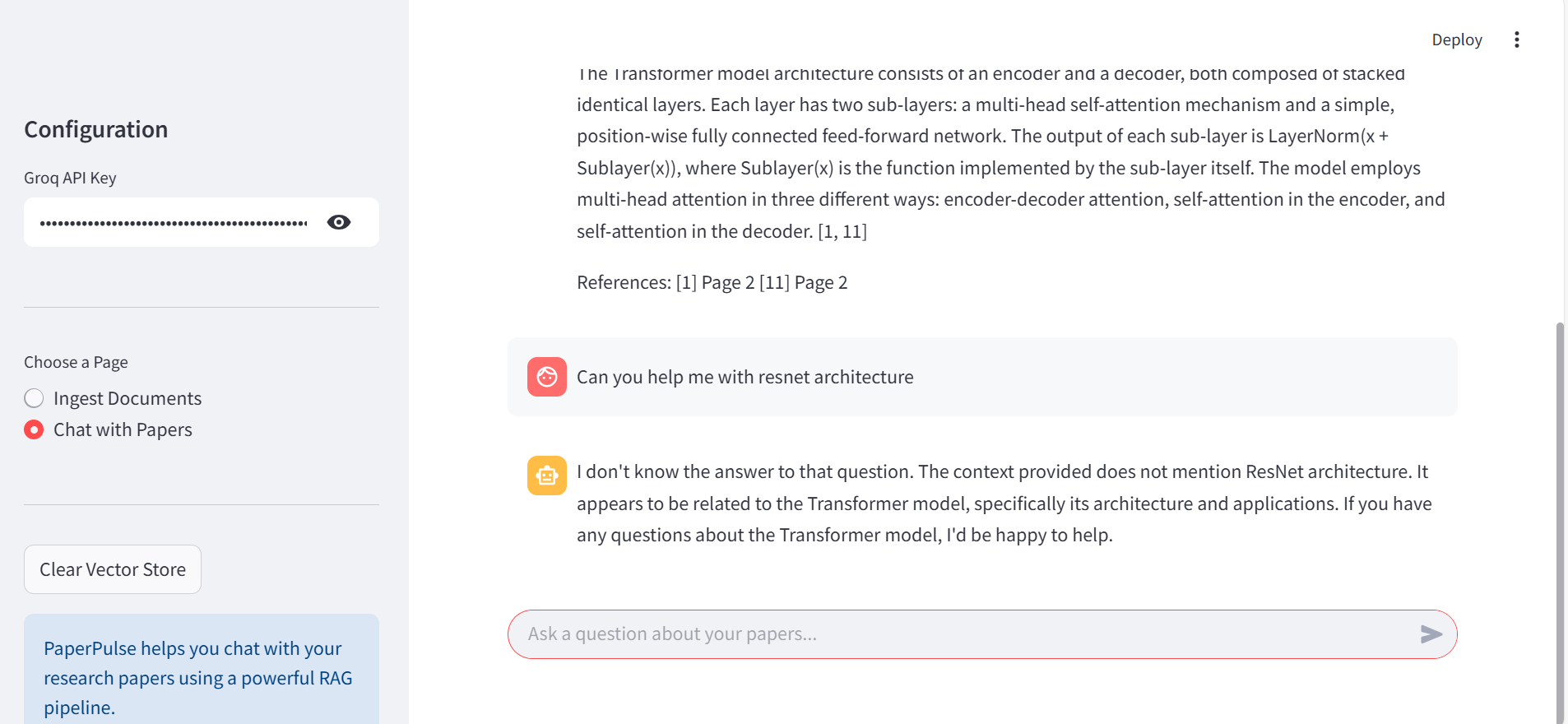
When a query is asked outside the knowledgebase is also handled gracefully.
python paperpulse.py query
.env
app.py
chroma_db_paperpulse_st/
paperpulse.py
requirements.txt
temp_uploads/
app.py: The main file for the Streamlit web application.paperpulse.py: The main file for the command-line interface.requirements.txt: A list of all the Python packages required for the project..env: Stores environment variables, such as your Groq API key.chroma_db_paperpulse_st/: The directory where the Chroma vector store for the Streamlit app is persisted.temp_uploads/: A temporary directory for storing uploaded files during processing.PaperPulse is designed with extensibility in mind. Planned and suggested future enhancements include:
Contributions are welcome! If you have any ideas, suggestions, or bug reports, please open an issue or submit a pull request.