Medical Report Tracker is a web-based application that leverages Retrieval-Augmented Generation (RAG) technology to enable intelligent querying and analysis of patient lab results over time. The system processes multiple PDF lab reports, extracts and chunks textual content, creates semantic embeddings, and stores them in a vector database for efficient retrieval. When users pose natural language questions about patient health metrics, the application retrieves relevant context from the vector database and generates accurate, context-aware responses using Large Language Models (LLMs).
The application addresses the challenge of analyzing longitudinal patient data by automatically processing lab reports, extracting key information, and providing an intuitive interface for querying trends, specific metrics, and comparative analyses. Built with FastAPI for the backend and a modern web interface, the system supports multiple LLM providers (OpenAI, Groq, Google Gemini) and uses ChromaDB for persistent vector storage. For testing and demonstration purposes, the application includes a data generation module that creates realistic lab reports using the Faker and ReportLab libraries, simulating real-world medical documentation.
Key features include patient-specific querying with automatic context filtering, a RAG pipeline that processes documents through chunking and embedding stages, and a user-friendly web interface that allows healthcare professionals to ask questions in natural language. While the current user interface has been intentionally kept simple for ease of use and demonstration purposes, the system architecture is designed with scalability and extensibility in mind, presenting significant potential for industry-grade upgrades. These enhancements could include advanced visualization dashboards, real-time data synchronization, multi-user authentication and authorization, integration with Electronic Health Record (EHR) systems, comprehensive audit logging, and enterprise-level security features. The system demonstrates the practical application of RAG technology in healthcare data management, enabling efficient extraction of insights from unstructured medical documents without requiring manual data entry or complex database schemas.
The Medical Report Tracker employs a Retrieval-Augmented Generation (RAG) methodology to enable intelligent querying of patient lab results. The approach combines semantic search capabilities with generative AI to provide accurate, context-aware responses.
The system follows a structured pipeline for processing lab reports: Extraction → Chunking → Embedding → Storage → Retrieval → Generation. PDF documents are first loaded and text content is extracted using PyPDF, preserving the structured format of lab reports. Metadata such as patient name, report number, and date are automatically extracted from filenames using regular expression pattern matching.
Documents are segmented using LangChain's RecursiveCharacterTextSplitter with a chunk size of 500 characters and 10% overlap between chunks. This approach ensures that related information spans across chunk boundaries, maintaining context continuity while optimizing for retrieval efficiency. The chunking strategy prioritizes sentence boundaries and paragraph breaks to preserve semantic coherence.
Each document chunk is converted into a dense vector representation using HuggingFace's sentence-transformers/all-MiniLM-L6-v2 model, which generates 384-dimensional embeddings capturing semantic meaning. These embeddings are stored in ChromaDB, a persistent vector database that enables efficient similarity search. The vector database maintains associations between embeddings, original text chunks, and metadata, allowing for both semantic retrieval and metadata-based filtering.
When processing user queries, the system employs a two-stage retrieval approach: semantic search followed by optional patient filtering. The query is first converted to an embedding vector, and cosine similarity is used to retrieve the most relevant document chunks from the vector database. If a patient is selected, results are post-filtered to include only chunks associated with that patient's metadata, ensuring query responses are scoped to the relevant patient context.
The retrieved context chunks are combined with the user's question and formatted according to a predefined prompt template. This prompt instructs the LLM to answer based solely on the provided context, ensuring responses are grounded in the actual lab report data. The system supports multiple LLM providers (OpenAI, Groq, Google Gemini) through a unified interface, allowing flexibility in model selection based on performance requirements and cost considerations.
For demonstration and testing purposes, the methodology includes a synthetic data generation component using the Faker library to create realistic patient demographics and the ReportLab library to generate standardized PDF lab reports. This approach enables comprehensive testing of the RAG pipeline without requiring access to real patient data, while maintaining the structural and formatting characteristics of authentic medical documents.
The Medical Report Tracker successfully demonstrates the practical application of RAG technology in healthcare data management. The system effectively processes multiple lab reports, extracts patient information and test results, and provides accurate, context-aware responses to natural language queries about patient health metrics.
The system successfully answers various types of questions with detailed, data-driven responses. Below are examples demonstrating the system's capabilities:
Question: "What is the patient's current hemoglobin level?"
Response:
The patient's current hemoglobin level is 16.73 g/dL, as reported in KRAUSE's lab report #4
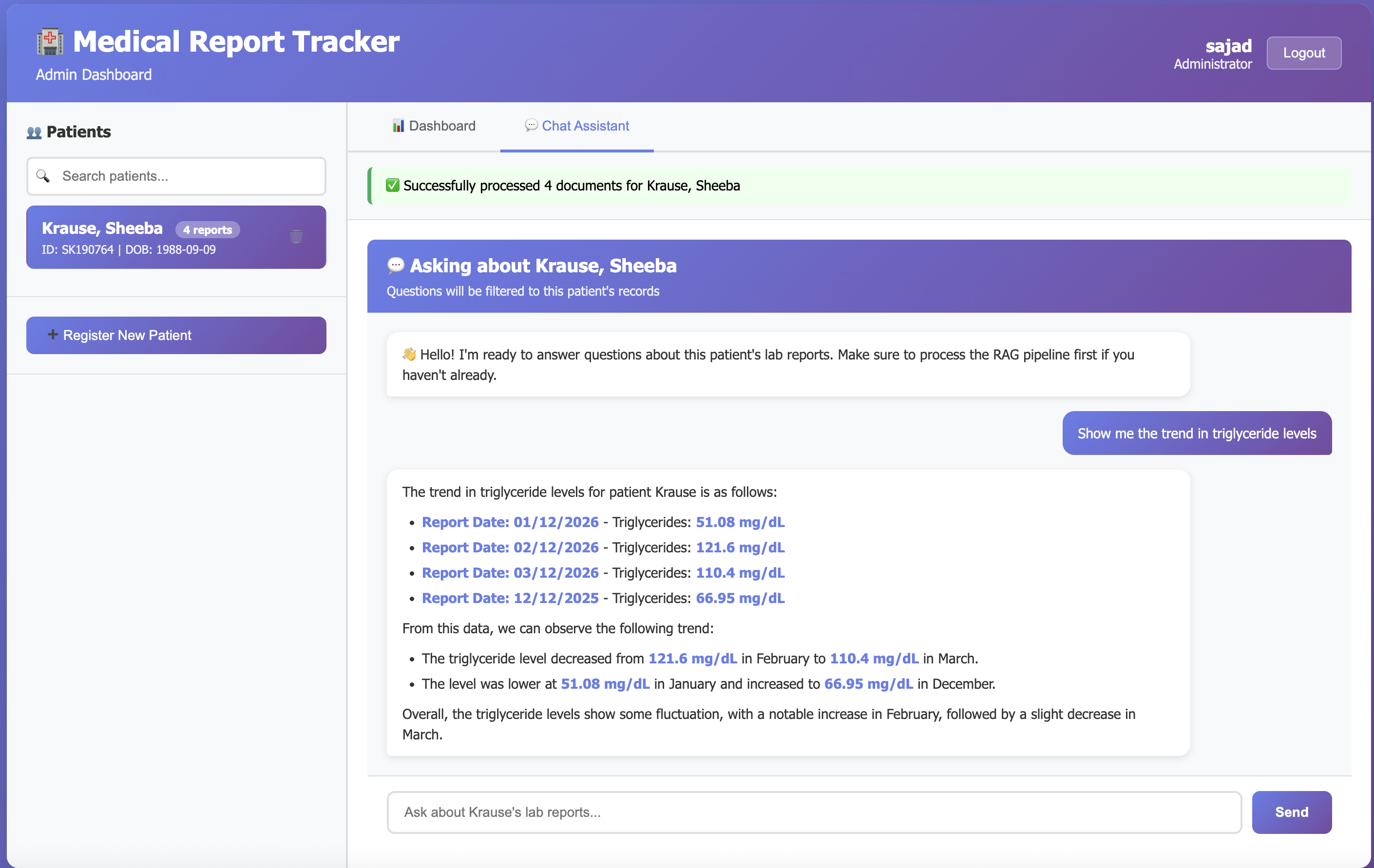
Question: "Show me the trend in triglyceride levels"
Response:
The triglyceride levels for KRAUSE, LAUREN over the reported periods are as follows:
- Report #1 (12/08/2025): 88.11 mg/dL (within the reference range of 50-150 mg/dL)
- Report #2 (01/08/2026): 134.77 mg/dL (within the reference range of 50-150 mg/dL)
- Report #3 (02/08/2026): 61.98 mg/dL (within the reference range of 50-150 mg/dL)
- Report #4 (03/08/2026): 79.05 mg/dL (within the reference range of 50-150 mg/dL)
Trend Analysis:
- The triglyceride levels started at 88.11 mg/dL, increased to 134.77 mg/dL, then decreased to 61.98 mg/dL, and finally rose again to 79.05 mg/dL.
- Overall, there is a fluctuation in the triglyceride levels, with a peak in January 2026, followed by a decrease in February and a slight increase in March.
Question: "What are the patient's liver function test results?"
Response:
The liver function test results for the patient KRAUSE are as follows:
Report #1:
- Protein, Total: 7.1 g/dL (Reference range: 6.1-8.1 g/dL)
- AST: 30 U/L (Reference range: 10-40 U/L)
- ALT: 7 U/L (Reference range: 9-46 U/L, noted as low)
Report #2:
- Protein, Total: 6.54 g/dL (Reference range: 6.1-8.1 g/dL)
- AST: 23 U/L (Reference range: 10-40 U/L)
- ALT: 18 U/L (Reference range: 9-46 U/L)
Report #3:
- Protein, Total: 7.11 g/dL (Reference range: 6.1-8.1 g/dL)
- AST: 47 U/L (Reference range: 10-40 U/L, noted as high)
- ALT: 58 U/L (Reference range: 9-46 U/L, noted as high)
Report #4:
- Protein, Total: 6.88 g/dL (Reference range: 6.1-8.1 g/dL)
- AST: 12 U/L (Reference range: 10-40 U/L)
- ALT: 43 U/L (Reference range: 9-46 U/L)
In summary, the AST and ALT levels vary across the reports, with some values being high or low compared to the reference ranges.
The system successfully demonstrates accurate retrieval of specific values, trend analysis across multiple time periods, and comprehensive reporting of test results with reference ranges. Patient-specific filtering ensures responses are scoped to the selected patient's data, and the natural language interface eliminates the need for complex database queries. The RAG pipeline effectively processes unstructured PDF documents and enables intuitive querying of longitudinal patient data.