Agentic AI systems are transforming the way we interact with digital tools. They are replacing traditional, manual navigation with intelligent, conversational interfaces. Users can simply express what they want in natural language rather than switching between apps and interfaces to complete tasks and let AI handle the rest. This paradigm shift is especially powerful in productivity ecosystems like Google Workspace, where everyday tasks often span multiple services: Gmail, Calendar, Contacts, and more.
By offloading coordination and decision-making to an agent, users can focus on intent rather than execution. But this raises an important question: when should we use intelligent agents, and when are simpler workflow automations sufficient?
As AI capabilities mature, it becomes essential to understand the distinction between workflows and agents, and to choose the right tool for the job:
Workflows perform best in environments with predictable, rule-based processes. They follow a fixed sequence of actions, making them ideal for repetitive operations where inputs, outputs, and decision logic are clearly defined.
Agents, in contrast, are designed for dynamic and uncertain contexts. They handle ambiguous instructions, shift behavior based on evolving conditions, and coordinate across multiple systems to accomplish goals that have not been explicitly programmed in advance.
Use an agent when:
For more details, visit: From Workflows to Agents: When Predictable Paths Aren't Enough
This is precisely where Google Workspace shines as a use case: users constantly jump between Gmail, Calendar, Contacts, and others to connect pieces of information and execute related tasks. Each switch not only costs time, but also mental effort. A capable agent bridges these services seamlessly, understanding the intent behind a request and carrying out the steps needed without making the user shift contexts.
Our AI-powered Google Workspace Agent is built to simplify your workday by providing a central, intelligent interface across all Workspace services. Whether you're drafting emails, scheduling meetings, or managing contacts, the agent streamlines your actions through a simple, natural language interface.
Conversational interface: Interact with Gmail, Calendar, Contacts, and more without switching tabs.
Context-aware intelligence: The agent understands the relationships between emails, meetings, and people, and can find the correct date or time range based on natural language requests.
Multi-step automation: Perform complex tasks that involve multiple steps and Google services.
Verification: Check if there is sufficient context and valid data to proceed with calling the next planning task in a multi-step process.
No-code interaction: No technical knowledge needed. Just describe what you want as if you were speaking to a human.
Multi-account management: Securely manage multiple Google accounts with seamless authentication. To choose which account to use, just specify related account information in the request(for example, "use my personal account" or "use my work account").
Memory: The agent can remember and use previous interactions to inform future actions.
This project showcases the power of LangGraph's agent orchestration, demonstrating how advanced AI tooling can unlock meaningful productivity gains in real-world environments. By deeply integrating with Google's APIs and layering intelligent reasoning over them, we deliver a smoother, smarter, and more intuitive Workspace experience.
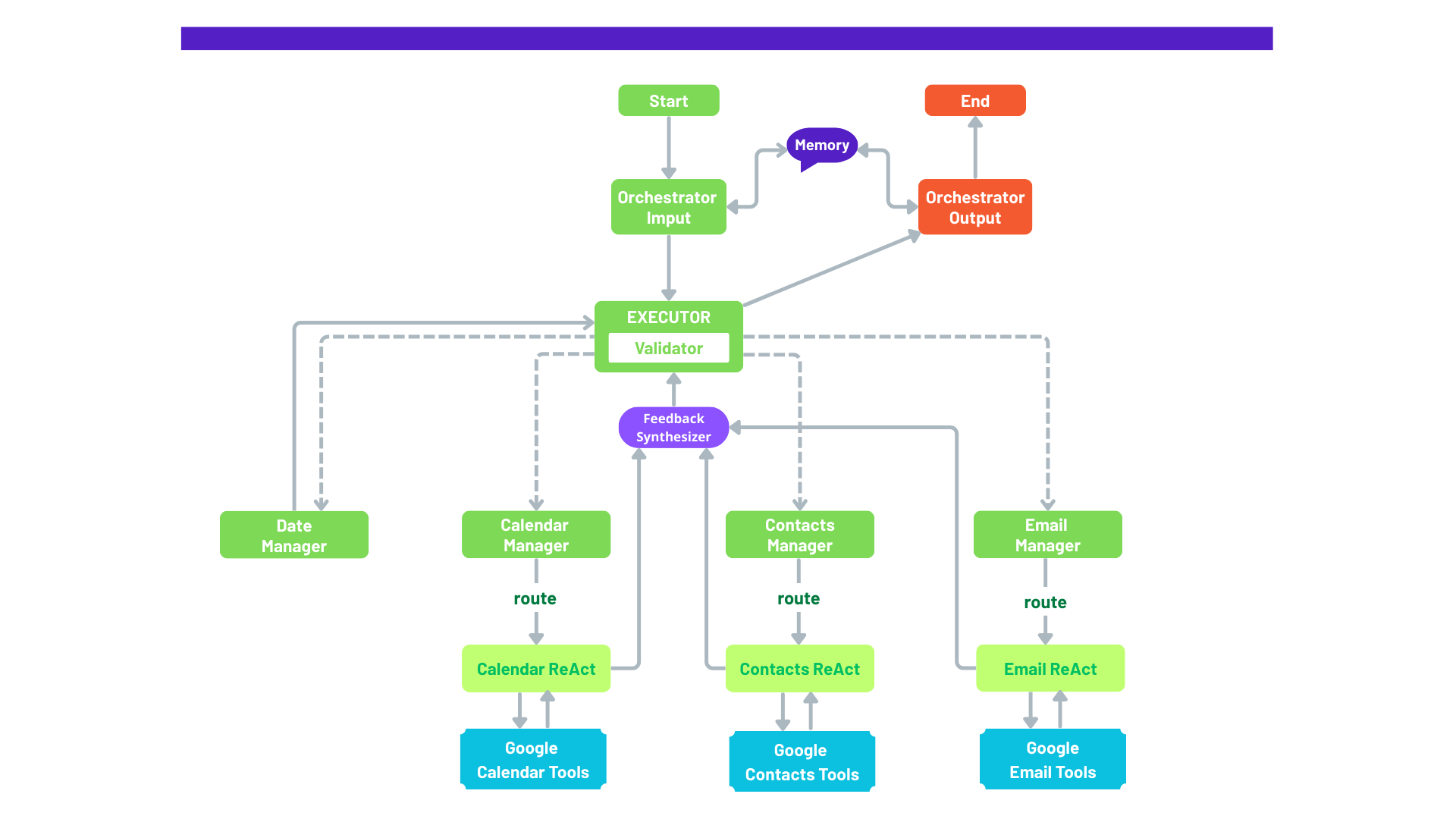
Figure: High-level architecture of the Google Workspace Agent showing orchestration, managers, and ReAct Agents.
Our Google Workspace Agent leverages a carefully selected stack of technologies:
LangGraph serves as the backbone for agent orchestration. It provides a graph-based framework for managing custom agent systems and maintaining state across interactions.
LangChain provides the foundation for LLM integration and tool creation. It also offers automatic integration with LangGraph and LangSmith.
LangSmith monitors, traces, and evaluates every step of the reasoning and tool execution process. It also provides a comfortable web interface to visualize the flow of information through the agent network.
PostgreSQL handles persistent storage for conversation history and agent state, enabling continuity across sessions.
Google Auth/API Client provides the interface to Google Workspace services (Gmail, Calendar, Contacts). It allows us to authenticate with different Google accounts and access their services using the Google API.
The LLM provider is OpenAI, configured with low temperature settings to ensure reliable and consistent responses for productivity tasks.
For the implementation of the agent system, we built several specialized components:
Prompts: A structured module for managing the various prompts used throughout the system. It allows loading prompts from a YAML file and is fully compatible with LangChain's PromptTemplate. It supports dynamic input variables. It incorporates key elements such as role, goal, instructions, context, constraints, format, and examples. The class also supports reasoning strategies, including chain-of-thought, ReAct, and self-ask.
Configuration: The system configuration is managed through Pydantic Settings, which enables structured, type-safe loading of environment variables and .env files. This approach ensures robust validation, centralized configuration management, and seamless integration with deployment environments.
Notebooks for testing: The src/test_notebooks directory contains a suite of interactive Jupyter notebooks used to validate the system’s core functionalities. These include operations on calendar events, contact management, natural language date parsing, email handling, multi-agent orchestration, prompt template construction from YAML configurations, and Google Workspace user authentication and credential flows. As functional tests and live documentation, the notebooks help developers verify component behavior and explore system interactions using real-world scenarios.
Google Service Layer: A comprehensive module that manages all interactions with Google APIs, handling authentication flows, credential management, and user account associations. It provides a robust storage system using SQLite for securely persisting user credentials and implements OAuth2 consent flows for seamless account authorization. The layer features a UserService class that manages multiple Google accounts per user, automatically refreshes expired tokens, and maintains user-account relationships. It includes data models using Pydantic for type safety and validation and supporting operations like account association, credential refresh, and user information retrieval. The consent flow component streamlines the authorization process with browser integration, token exchange, and a user-friendly command-line interface. This module is the foundation for all Google Workspace interactions, enabling secure multi-account management while abstracting away the complexities of OAuth2 authentication and token lifecycle management.
Agents: This module contains all the logic for the specialized managers and the orchestrator, including the Google tools for the specialized managers. We will see this module in more detail in the next section.
This architecture allows us to create a conversational assistant that can understand complex requests involving multiple Google Workspace services, break them down into manageable steps, and execute them while maintaining context and providing clear feedback to the user.
Let's examine the custom multi-agent architecture used in this project. We will use the term node to refer to each individual agent in the architecture.
The Orchestrator Input node plays a central role in our multi-agent system by analyzing user inputs, breaking them into actionable subtasks, and creating an ordered list of managers to call. As the first node in a directed graph architecture, it interprets requests using the current conversation context and account information, then builds an execution plan that guides the entire orchestration pipeline. This plan includes step-by-step reasoning and a list of managers to call, each with a detailed query. The output is a JSON object containing the reasoning and the sequence of manager instructions.
For instance, consider the following output example:
{ "reasoning": "The user's request involves creating a draft email for a contact named Carlos and includes checking the user's free time for tomorrow. Therefore, we need to use the 'contacts_manage' to find Carlos's email address and 'calendar_manage' to check the user's availability. Since the user specified the university account, we will use this account for both managers. First, we will use 'date_manage' to determine the specific date for 'tomorrow' and then check the calendar for free time slots. Finally, we will create the draft email using 'email_manage'.", "managers": [ { "route_manager": "date_manage", "query": "Determine the date for 'tomorrow' from the current date." }, { "route_manager": "contacts_manage", "query": "Find the contact information for Carlos in the personal account." }, { "route_manager": "calendar_manage", "query": "Check for free time slots on the determined date from 9 am to 5 pm in the personal account." }, { "route_manager": "email_manage", "query": "Create a draft email in the personal account to Carlos, thanking him for his efforts this week in the sales department. Include the user's free time tomorrow from 9 am to5 pmm to set up a meeting. Best regards, Manuel-test." } ] }
This component ensures queries are routed based on context, account identity, and task type (e.g., date parsing, contact retrieval, calendar lookup, or email generation). Its ability to reason through complex requests and produce structured outputs enables reliable coordination across the broader agent system.
The Orchestrator Output node is the final stage in the multi-agent system, responsible for synthesizing the results from all specialized managers into a clear, coherent response for the user. Once the Orchestrator Input has defined the execution plan and the system has gathered all manager outputs, this node combines those responses along with the conversation history into a final user-facing answer.
It processes the collected manager outputs, integrating their content into a structured Markdown message. If any manager encounters an error or cannot complete its task, the Orchestrator Output explains the issue transparently to the user. It ensures consistent tone and language, mirrors the style of the original request, and preserves all relevant content such as event titles, links, email bodies, or other domain-specific information.
This component also maintains strong context awareness, referencing previous user messages when needed and clearly indicating when past interactions influence the current response. It handles output from various managers—like date, contacts, email, and calendar—while respecting their specific formatting and content conventions. In cases where the user’s request doesn’t involve any manager-specific actions, the Orchestrator Output can still generate a general response, ensuring that all meaningful user queries receive an appropriate reply.
The Executor executes the action plan generated by the Orchestrator Input. It sequentially calls each manager while preserving and forwarding the context produced by previously executed managers. This design ensures that any manager requiring information from a previous step—such as a contact's email or a resolved date—receives it properly. For this to work, the initial plan must respect logical dependencies between managers and define an execution order accordingly.
Between each manager call, a Verifier Step is performed to validate whether the context gathered so far is sufficient to proceed. A dedicated Verification Agent handles this step that checks the outputs of prior managers and determines whether the next one has the necessary input to operate correctly.
Perfect. Here's a rewritten and expanded section for your documentation that covers both the Orchestrator Executor and the new Verifier Step, integrating the purpose of the verifier and how it operates based on the agent prompt you provided:
The Orchestrator Executor executes the action plan generated by the Orchestrator Input node. It sequentially calls each manager in the specified order, ensuring that each has access to the full context, including the original user request and the responses from previously called managers. This context propagation is critical for resolving inter-manager dependencies, such as using a resolved date to check calendar availability or a contact's email to compose a message. For this reason, the Orchestrator Input must output an execution plan that lists managers and respects the logical dependencies between them.
Execution is not a blind step-by-step process; instead, it is adaptive and verified at each stage to ensure continuity, accuracy, and data sufficiency before moving on.
Between each manager invocation, the system performs a Verifier Step—a critical checkpoint determining whether the information collected so far is sufficient to proceed. This step is handled by a dedicated Verifier Agent, whose job is to assess the output of the previous managers and confirm that the current context meets the requirements of the next one.
The Verifier checks for ambiguities, missing data, or incomplete resolutions that could compromise downstream tasks. For instance, if a user asks to email "Carlos" but the contacts_manage manager returns multiple matches, the Verifier halts execution and prompts the user to clarify which Carlos is meant. Similarly, if no contact is found or the chosen contact lacks an email address, the system cannot proceed to email_manage and will inform the user accordingly.
Here’s a typical example:
User request: “Email Carlos to thank him for this week’s work.”
Orchestrator Input plan:
contacts_manage → get Carlos’s infoemail_manage → draft emailVerifier outcome:
If contacts_manage returns multiple possible matches, and email_manage expects only one recipient, the Verifier returns:
{ "action": "ask_to_user", "detail": "Multiple contacts matched the name 'Carlos'. Please specify which one you meant before drafting the email." }
Thanks to this stepwise verification, the system avoids cascading errors and guarantees that each manager operates on a valid, disambiguated context. It elevates the robustness of the orchestration pipeline, making it resilient, transparent, and interactive when ambiguity arises.
In our system, managers are specialized agents that act as routers for specific domains, such as calendar, contacts, and email. Their primary role is to take the query generated by the Orchestrator Input and forward it to the appropriate account(s) based on context and user intent. Each manager is responsible for one domain and ensures the query reaches the correct target account, for example, the personal account, work account, or both.
Managers are designed to handle multiple accounts efficiently. When a user query involves various accounts (e.g., "Check my meetings for tomorrow in all my calendars"), the manager dispatches these calls asynchronously, allowing for parallel execution and significant time savings. This pattern applies across all router managers in the system, ensuring scalability and responsiveness regardless of the number of accounts linked.
A typical example is a user asking, “What events do I have tomorrow?” In this case:
Among all managers, the Date Manager is unique. Unlike others, it doesn't route requests to external services but rather interprets natural language references to time. It leverages a few-shot prompting strategy, where an LLM is guided using multiple contextual examples (e.g., “next Monday,” “last Friday afternoon,” “the beginning of June”) to improve accuracy in resolving time expressions. This allows it to handle vague or ambiguous time references with high reliability, an essential step before invoking any time-sensitive action, such as scheduling or availability checking.
Together, these managers form the operational backbone of our multi-agent system. While their tasks are domain-specific, their design as intelligent routers makes them modular and efficient. Most importantly, this architecture allows for seamless integration of new agents to add a new functionality; one simply needs to define its routing logic and implement the corresponding React (execution handler). This extensibility ensures the system can evolve rapidly while maintaining consistency and scalability.
The Feedback Synthesizer node transforms raw agent responses into clear, user-friendly replies. After each specialized manager completes its operation, whether related to calendar, contacts, or email, their corresponding React (execution handler) returns structured data. This data is then passed to the Feedback Synthesizer node, which converts it into a single coherent message that answers the specific query planned initially by the Orchestrator Input.
This process happens individually for each manager. When the system invokes the calendar manager, for example, all the responses it gathers from the underlying accounts (via React) are consolidated and formatted by the synthesizer into a single message about calendar availability or events. The same applies to contacts (e.g., when searching for or listing contact information) and emails (e.g., summarizing drafts or confirming sent messages).
In short, the Feedback Synthesizer guarantees that every response, no matter how complex the backend routing or the number of accounts, is polished, accurate, and aligned with the user’s original request.
ReAct Agents are domain-specific executors responsible for low-level operations across calendars, emails, and contacts. Each agent operates independently without persistent memory, relying entirely on the tools available and the input received for each task. They do not retain past messages or interactions, which allows them to remain lightweight, stateless, and easily parallelized across user accounts.
The core strength of ReAct Agents lies in their tool-augmented reasoning and their ability to reason step-by-step about the user’s intent, invoke the appropriate tools, and return structured JSON results that feed into the Feedback Synthesizer. These agents are the final performers in the orchestration chain, translating high-level plans into concrete actions.
Each ReAct Agent has access to a tailored set of tools:
Calendar Agent
Email Agent
Contacts Agent
All agents follow strict guidelines for input validation, timezone handling, and error prevention. For example, the Calendar Agent uses ISO time formats in the Europe/Paris timezone, while the Email Agent ensures HTML-formatted bodies and proper recipient validation. The Contacts Agent handles name normalization when searching (e.g., retrying without accents) and limits tool retries to prevent infinite loops.
This modular structure ensures that each ReAct Agent remains focused, accountable, and easy to extend. Adding a new domain (e.g., document or task managers) requires defining a new agent, equipping it with a toolset, and connecting it to the orchestration flow. Their stateless nature makes them ideal for concurrent execution across multiple accounts and consistent with the broader principles of composability in multi-agent systems.
The Google Tools nodes act as the bridge between our multi-agent system and Google Workspace services like Calendar, Gmail, and Contacts. Each tool enables ReAct Agents to perform specific actions, such as searching for emails, creating events, or updating contacts, through well-defined, structured calls to Google's APIs.
Rather than requiring user credentials and account info in every tool call, these details are passed automatically through the graph’s state. This allows each tool to know who the user is and which Google account to operate on, without extra configuration from the agent.
All tools are designed to return standardized, predictable outputs, making it easy for other nodes like the Feedback Synthesizer to generate user-facing messages. To ensure system stability, tools include safeguards such as rate limiting (using the @limit_calls decorator) to prevent infinite loops, and robust error handling to manage API failures or permission issues gracefully.
This design keeps ReAct Agents focused on reasoning and decision-making, while the tools handle the complexity of interacting with external services in a reliable and scalable way.
One of the key challenges in building an agent system is maintaining state across multiple interactions. Our solution implements a sophisticated state management approach with two distinct types of state graphs, each with different memory capabilities:
Dual State Graphs:
ReAct Agent State Graph: Manages the state of specialized worker agents but does not maintain memory of past interactions. Each time a ReAct agent is invoked, it starts with a fresh state, focusing only on the current task. This state includes:
Orchestrator State Graph: Maintains the overall conversation context and preserves memory across multiple interactions. This persistent state includes:
PostgreSQL Checkpointing: We leverage LangGraph's checkpointing capabilities. This enables:
Context Window Management: To optimize token usage and maintain focus, we used a sliding window approach that preserves only the most recent interactions using LangChain's built-in functionality:
from langchain_core.messages import trim_messages
This limits the conversation history to the last five user/agent interactions, reducing costs while maintaining sufficient context for coherent responses. The Orchestrators trimmed this history while still having the ability to retrieve older context from the database when needed.
The system employs a dual-model approach to balance performance and cost efficiency:
main_model = ChatOpenAI(model="gpt-4o-2024-08-06", temperature=0.0) mini_model = ChatOpenAI(model="gpt-4o-mini", temperature=0.0)
This strategy allows us to:
Connecting to Google's services requires careful handling of authentication and API interactions:
OAuth Consent Flow: We implemented a streamlined OAuth process that guides users through connecting their Google accounts to the agent.
Multi-Account Support: The system can manage multiple Google accounts simultaneously, with the orchestrator routing operations to the appropriate account based on user preferences or explicit instructions.
To set up the Google Workspace Agent, follow these steps:
git clone https://github.com/MAQuesada/Google-Workspace-Agent cd Google-Workspace-Agent
curl -sSL https://install.python-poetry.org | python3 - poetry install poetry self add poetry-plugin-shell poetry shell
Create a .env file with the following variables:
OPENAI_API_KEY=your_openai_api_key POSTGRES_DB_URI=postgresql://username:password@localhost:5432/dbname GOOGLE_CLIENT_ID=your_google_client_id GOOGLE_CLIENT_SECRET=your_google_client_secret GOOGLE_PROJECT_CREDENTIALS_PATH=path/to/credentials.json
Run the consent flow script to link Google accounts:
python src/google_service/consent_flow.py
Follow the prompts to authorize the application and associate accounts with local usernames.
Launch the interactive notebook:
jupyter notebook src/test_notebooks/test_end_to_end.ipynb
Here are some example interactions with the Google Workspace Agent, demonstrating the system's capabilities, ranging from simple tasks to more complex ones that require integrating all the agents.
Case 1: Simple interaction to show the memory capabilities of the orchestrator, the multi-account support.
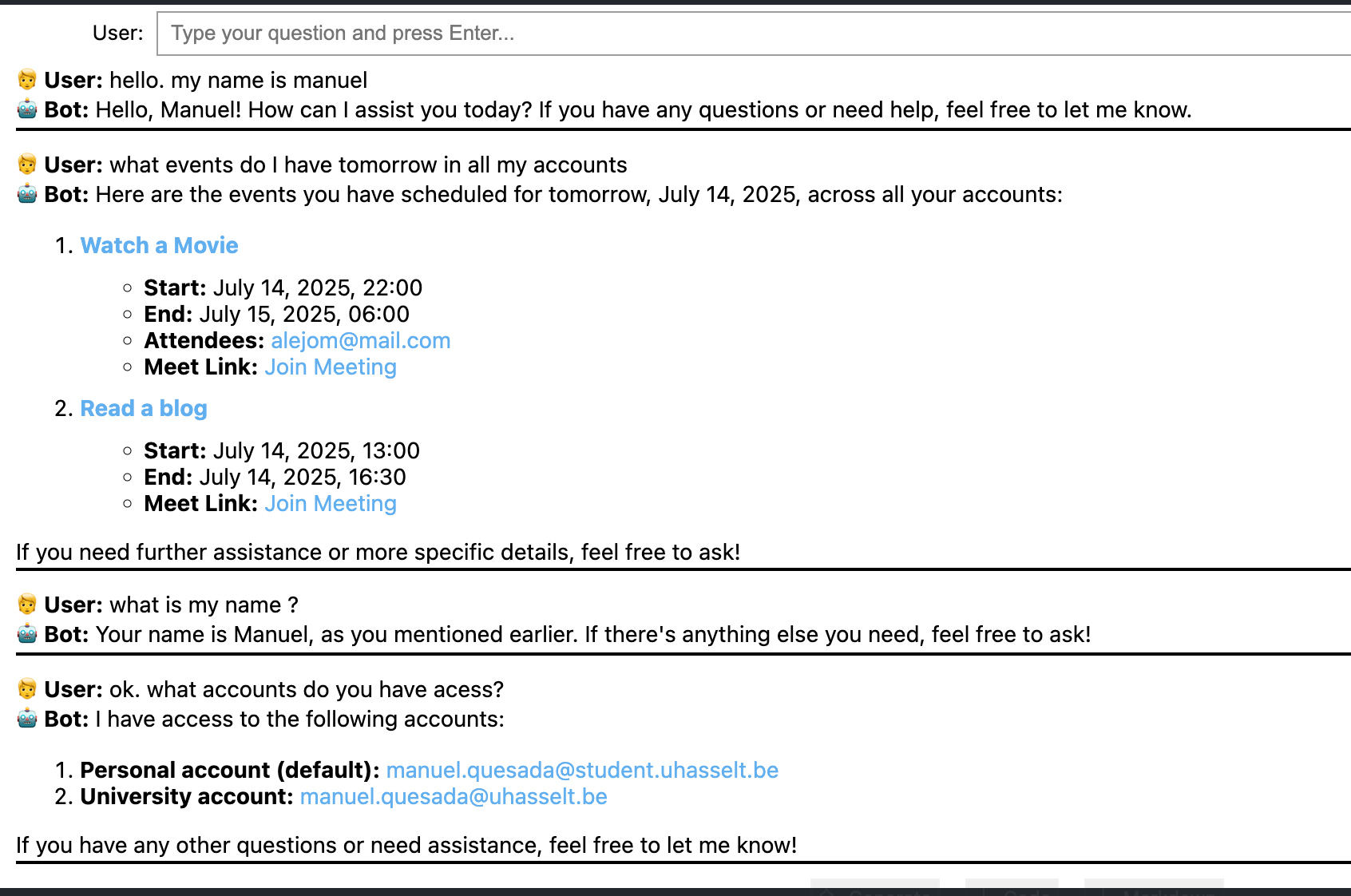
Case 2: Creating an event and adding attendees can be done using Google Contacts. In this particular case, there were multiple contacts named "Manuel." The agent asked for clarification instead of randomly adding one or all of them to avoid confusion.
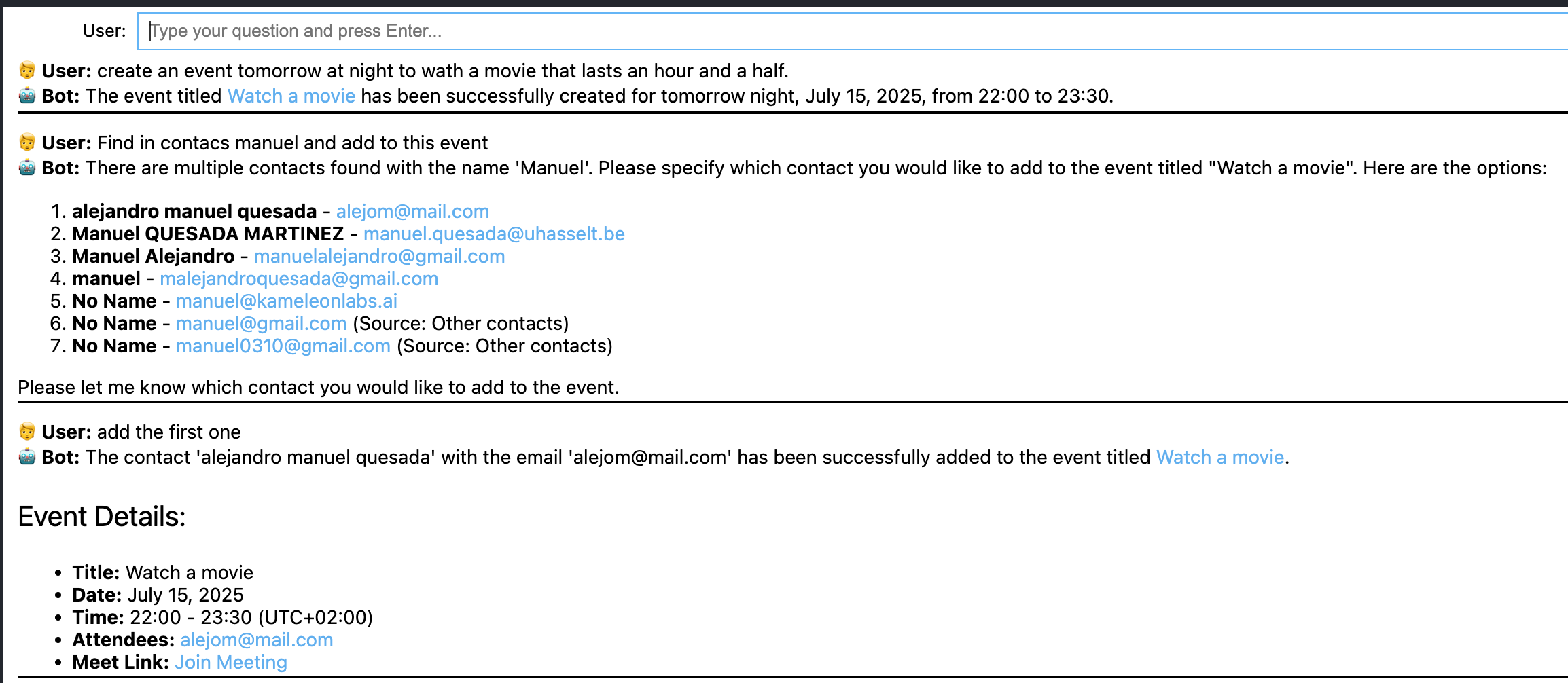
Case 3. A bit more complex interaction that illustrates how the multi-agent system coordinates tasks such as scheduling, email drafting, and contact management through seamless integration with the user's university account, handling data gaps (e.g., missing email addresses), and dynamically updating content to maintain contextual accuracy and efficiency.

Add Support for Google Search: Integrating search capabilities to find relevant information can be vital to give grandness to the agent.
Add Voice Interface: Enable voice commands for hands-free operation.
Serve this agent as a service: Deploy this agent to allow users to interact with it through a web interface or Telegram.
Multi-modal Interaction: Investigating how to effectively combine text, voice, and visual inputs to create a more natural and accessible agent interface. This includes research on context preservation across different modalities.
Prompt Refinement & Tool Expansion: Fine-tuning specific node prompts and expanding the system's toolset to improve reliability and adaptability in more complex scenarios.
Model Optimization: Leveraging more capable models for deep reasoning tasks while exploring hybrid strategies to balance performance and cost. This includes investigating smaller, specialized models for specific tasks.
Automated Evaluation: Developing specialized metrics to evaluate the performance of the agent in different scenarios, or even using LangSmith together another evaluation framework to track and analyze the agent's behavior automatically.
Scalability Testing: Conducting stress tests with more users and concurrent workflows to ensure the architecture scales effectively in production environments.
This project is open for contributions, feedback, and collaboration.
Feel free to reach out or fork the project!