This project presents a practical implementation of a Retrieval-Augmented Generation (RAG)–based AI assistant designed to answer user queries using custom document collections. The system combines document retrieval with large language models (LLMs) to generate context-aware and grounded responses.
The assistant loads domain-specific documents, processes them into searchable text chunks, and stores vector embeddings in a vector database. When a user submits a query, the system retrieves the most relevant document chunks and uses them as contextual input for the language model to generate accurate and informative answers.
This project serves as a hands-on introduction to RAG architecture and agentic AI concepts, focusing on real-world implementation using Python, vector databases, embeddings, and LLM frameworks. The resulting system demonstrates how retrieval-enhanced AI assistants can reduce hallucinations and improve response relevance when working with private or domain-specific data.
Large Language Models (LLMs) have demonstrated strong capabilities in natural language understanding and generation; however, they struggle when answering questions about private or domain-specific data that is not part of their training set. Retrieval-Augmented Generation (RAG) addresses this limitation by combining document retrieval with generative models.
This project presents a practical, hands-on implementation of a RAG-based AI assistant designed to answer user queries using custom documents. The goal is to demonstrate how agentic AI systems can be built by orchestrating document ingestion, vector search, and controlled LLM prompting in a modular pipeline suitable for real-world applications.
Traditional language models generate responses based on their pre-trained knowledge, which can lead to hallucinations or outdated answers when handling domain-specific queries.
The challenge is to build a system that:
The system is designed as a general-purpose document question-answering assistant. In this implementation, the primary document domain consists of text-based educational and technical documents.
Typical query types include:
This makes the system applicable to domains such as education, internal knowledge bases, technical documentation, and research assistance.
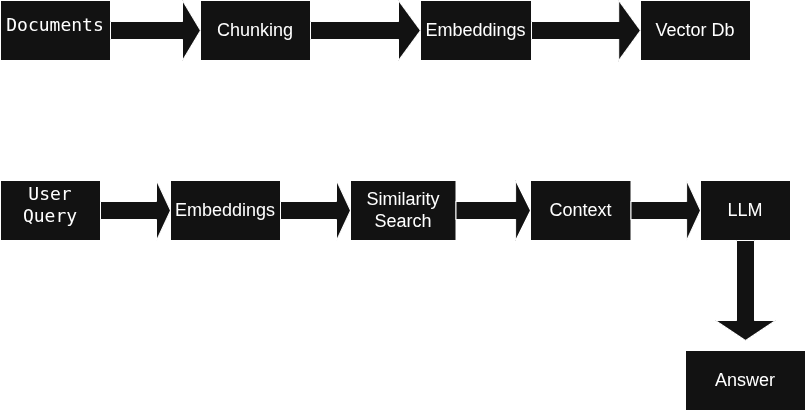
Figure 1: High-level architecture of the RAG-based AI assistant showing document ingestion, vector storage, retrieval, and response generation.
The assistant follows the sequence below when answering a question:
This project emphasizes modularity and provider flexibility by decoupling the large language model, embedding model, and vector database components. Each component was selected to balance performance, ease of use, and suitability for an educational RAG implementation.
The system supports multiple large language model (LLM) providers through LangChain abstractions. At runtime, the assistant automatically selects an available model based on the configured API keys. The supported LLMs include:
gpt-4o-mini)llama-3.1-8b-instant)gemini-2.0-flash)This fallback-based selection mechanism ensures flexibility across environments and enables experimentation with different LLM providers without modifying the core application logic. A temperature of 0.0 is used to promote deterministic and fact-focused responses, which is especially important in retrieval-augmented systems.
For semantic embedding, the system uses the Sentence Transformers library with the model:
sentence-transformers/all-MiniLM-L6-v2This embedding model was chosen due to its strong performance on semantic similarity tasks, low computational overhead, and widespread adoption in RAG-based applications. Both document chunks and user queries are embedded using the same model to ensure consistency in the vector space.
The project uses ChromaDB as the vector database for storing and retrieving document embeddings. ChromaDB was selected because it provides:
Each document is split into overlapping text chunks using a recursive character-based splitting strategy before being embedded and stored. Metadata such as source document index and chunk index is preserved to maintain traceability during retrieval.
A structured RAG prompt template is used to strictly constrain the language model’s behavior. The prompt explicitly instructs the model to answer questions only using the retrieved context and to acknowledge when insufficient information is available. This design reduces hallucinations and reinforces grounded, document-based responses.
Overall, these design choices reflect a practical, extensible approach to building Retrieval-Augmented Generation systems while maintaining clarity and control over model behavior.
The implementation of the RAG assistant uses the following technologies:
This modular stack allows the system to switch between different model providers while keeping the retrieval pipeline consistent.
The system follows a standard Retrieval-Augmented Generation (RAG) pipeline, implemented in a modular and extensible manner.
Text documents are stored in the data/ directory and loaded into the system at runtime. Each document is read from disk and represented with its content and metadata, enabling traceability during retrieval.
To improve retrieval accuracy, documents are split into smaller text chunks. Chunking is performed using a fixed character-length strategy, ensuring that each chunk remains semantically meaningful while fitting within embedding model constraints.
Each text chunk is converted into a numerical vector using a pre-trained embedding model. These embeddings capture semantic meaning and enable similarity-based search.
All embeddings, along with their associated text and metadata, are stored in a vector database (ChromaDB). This allows efficient similarity search across large document collections.
When a user submits a query, the query is embedded using the same embedding model. The vector database is then queried to retrieve the most relevant document chunks based on semantic similarity.
A prompt template is designed to combine the retrieved context with the user’s question. The prompt explicitly instructs the language model to rely on the provided context when generating responses.
The final response is generated by passing the constructed prompt to a large language model. The output includes both the generated answer and the supporting retrieved context, ensuring transparency and explainability.
The RAG-based AI assistant successfully retrieves relevant document chunks and generates answers grounded in the provided context. Manual testing across multiple query types demonstrated improved factual accuracy compared to a standalone language model without retrieval.
While a formal quantitative evaluation was outside the scope of this project, qualitative analysis showed:
This confirms the effectiveness of Retrieval-Augmented Generation for building reliable document-aware AI systems.
This project focuses on building a functional RAG pipeline rather than exhaustive evaluation. As a result, retrieval performance metrics such as precision, recall, and retrieval latency were not formally measured.
Future improvements include:
These enhancements would further strengthen the system’s robustness and applicability in production environments.
The full source code for this project is available on GitHub:
GitHub Repository:
https://github.com/Sifen1995/tensor_project1
The repository includes:
This project demonstrates a practical and extensible implementation of a Retrieval-Augmented Generation–based AI assistant. By combining document retrieval with controlled language model generation, the system provides accurate, transparent, and context-aware responses.
The project serves as a strong foundation for exploring advanced agentic AI systems and highlights the value of RAG architectures in real-world AI applications.