
EDUBOT is an intelligent Retrieval-Augmented Generation (RAG) system that seamlessly integrates document retrieval with large language model reasoning to deliver accurate and context-aware answers.
Users can upload custom documents in multiple formats (PDF, DOCX, PPTX, XLSX, TXT), which are automatically processed, embedded, and stored in a FAISS vector database using a LangGraph-based ingestion pipeline.
The assistant leverages Hugging Face embeddings (all-MiniLM-L6-v2) for semantic search and Google Gemini as the core LLM to generate precise, evidence-grounded responses.
By combining a real-time RAG architecture with a modular ingestion workflow, EDUBOT provides a scalable, local, and explainable AI solution tailored for education, knowledge retrieval, and intelligent document analysis.
Conventional AI assistants often depend solely on pretrained knowledge, which can lead to outdated or generic responses.
EDUBOT enhances this paradigm through a Retrieval-Augmented Generation (RAG) approach — integrating retrieval and generation into a single intelligent pipeline.
The system’s Document Ingestion Module, powered by LangGraph, continuously monitors and processes new documents, ensuring that the FAISS vector database remains up to date.
When a user submits a query via the Streamlit interface, the assistant retrieves semantically relevant content using Hugging Face embeddings and synthesizes context-rich answers through the Gemini LLM.
This architecture guarantees that every response is derived from the most relevant, up-to-date documents, ensuring factual accuracy and transparency.
With its modular design, agentic orchestration, and full offline compatibility, EDUBOT demonstrates the potential of open-source RAG systems for academic research, enterprise documentation, and educational AI applications.
This project implements EduRAG, an educational Retrieval-Augmented Generation (RAG) system, to enable intelligent question answering over custom documents. The goal is to provide a scalable, explainable assistant that retrieves relevant information from a knowledge base of PDFs, DOCX, PPTX, etc., and generates context-aware responses via a large language model. This system is designed for educational use cases such as summarizing study materials, answering academic questions, and assisting learners in navigating complex documents.
The EDUBOT system follows a modular, two-stage methodology integrating document ingestion and retrieval-augmented reasoning.
This approach ensures that every user query is answered using the most relevant and up-to-date information from uploaded documents.
1️⃣ File Detection and Monitoring
.pdf, .docx, .pptx, .xlsx, and .txt.2️⃣ Document Loading and Preprocessing
PyPDFLoader, Docx2txtLoader, and UnstructuredPowerPointLoader.3️⃣ Text Chunking
RecursiveCharacterTextSplitter to preserve semantic context.4️⃣ Embedding Generation
all-MiniLM-L6-v2.5️⃣ Vector Database Creation (FAISS)
file_mapping.pkl.6️⃣ Validation and Synchronization
When ingesting documents, we split the text into smaller overlapping chunks to preserve context and improve retrieval quality. The parameters used are:
Why these values were chosen:
Chunk size (500 tokens):
Overlap (50 tokens):
This combination balances retrieval accuracy and computational efficiency, ensuring the RAG system provides relevant answers without unnecessary overhead.
1️⃣ User Query Input (Streamlit UI)
2️⃣ Query Vectorization and Retrieval
3️⃣ Context Construction
4️⃣ Response Generation (Google Gemini LLM)
5️⃣ Semantic Evaluation and Display
The EDUBOT methodology combines automated document ingestion, vector-based retrieval, and contextual LLM reasoning within a unified agentic framework.
By leveraging LangGraph for orchestration, FAISS for storage, and Gemini for generation, it delivers a reliable, transparent, and explainable AI assistant capable of dynamic knowledge retrieval and reasoning.
| Feature | Description |
|---|---|
| 📂 Smart Multi-File Ingestion | Automatically loads and updates TXT, PDF, PPT, DOC, DOCX, XLS, and XLSX files using agentic workflows. |
| 🔁 Auto Vector Update | Continuously monitors the data folder for new or deleted files and updates FAISS vectors dynamically. |
| 🧠 FAISS + MiniLM Embeddings | Uses all-MiniLM-L6-v2 sentence transformer for efficient context retrieval. |
| 🧩 LangGraph Agent Workflow | Agentic graph automates file detection → ingestion → validation with retries and logging. |
| ⚙️ Gemini-2.0 Flash Integration | Uses Google’s LLM for intelligent, contextual, and educational responses. |
| 🧾 Text + Image Understanding | Extracts text from PDFs, PPTs, DOCs, Excels, and captions images using BLIP + EasyOCR. |
| 🪄 Summarization | Auto-summarizes each uploaded file into concise study notes. |
| 💬 Interactive Chat UI | Beautiful Streamlit interface with animated chat bubbles and color-coded user/assistant messages. |
| 🧮 Evaluation Metrics | Integrated BLEU, ROUGE, and semantic similarity scoring for academic answer evaluation. |
| 📡 Memory-Enabled Conversations | Maintains contextual flow using ConversationBufferMemory. |
| 🕵️ Watcher Agent | Continuously monitors the data folder and triggers re-ingestion automatically. |
| ✅ Academic Filter | Restricts to academic queries only; politely blocks unrelated or personal questions. |
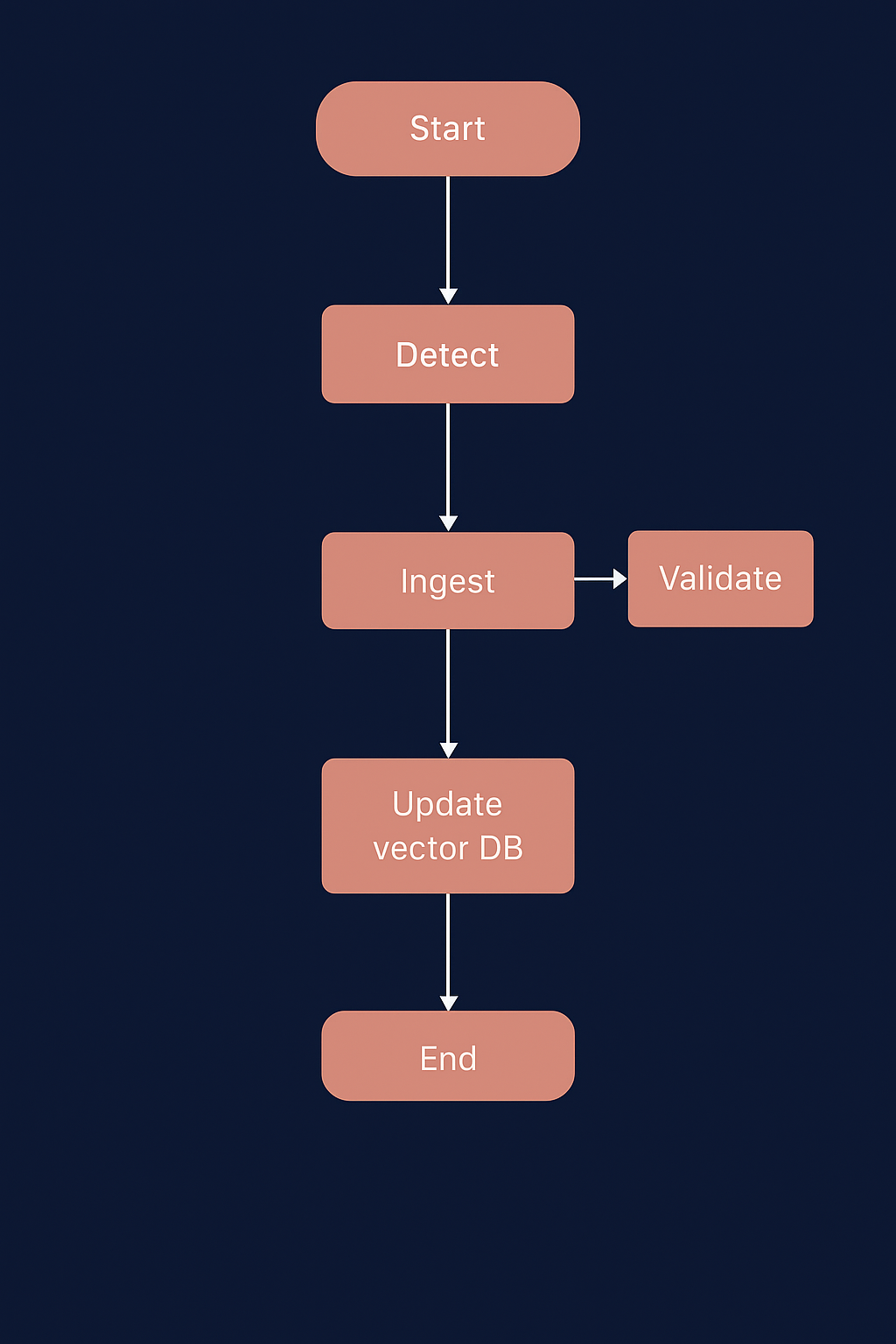
The Document Ingestion system in EDUBOT automates the entire data pipeline -
from file detection to embedding generation and vector database management.
It uses a LangGraph Agentic Workflow to create a robust, modular,
and the self-healing ingestion process.
This ensures that new, modified, or deleted documents are automatically
processed and reflected in the FAISS Vector Database without manual intervention.
START → DETECT → INGEST → VALIDATE → UPDATE VECTOR DB → END
Each stage in this workflow corresponds to a LangGraph node, connected
sequentially to ensure smooth execution and error handling.
update_log.txt.all-MiniLM-L6-v2.file_mapping.pkl with vector IDs and chunk counts.file_mapping.pkl) for future consistency.update_log.txt.watcher_agent) continuously monitors the Data Folder..png?versionId=HhT2m_p5VAuSTdnbPBvu4QR3rCXlQ1j9&Expires=1784811802&Key-Pair-Id=K3EVG0QTJR4SK0&Signature=qpuNtsnlc3iwAZaEfMlZANb~4oDP5b1mPHp-Ecyfqi-Mrq95CpG3jMBVM6vK7Lt74Tr~iQ0C8dGKBQ-1Dx1eT75IStVIEe9r-VXieawYtjNU~b1STdWDd3k-sRq8Th3qNPuwO3HA~RbH~DJZnEa9HePkMUs6IdLIeFaotplw~lVc7iFbhrShg0XKhaC9V-XKKS~7GZVaZndz4MXAASDjsN-6UXkD5GnSp0KVKh5Y9xKkknV1EY2D9Yg7tBkWGGwLVQtFmcS7PoBSnHSJrOa~W0Hw4ynusTH9vGNnxUAOEQdyaIRa~ATILac05SxzoYRqDMqvC2igmm6pfEBmeElOkg__)
The diagram above represents the Retrieval-Augmented Generation (RAG) architecture used in EDUBOT.
It combines document retrieval and large language model reasoning to provide accurate, context-aware responses.
1️⃣ Document Input
2️⃣ Text Extraction
3️⃣ Chunking
4️⃣ Vectorization (Embedding Generation)
5️⃣ Vector Database (FAISS)
6️⃣ User Query
7️⃣ Query Embedding & Similarity Search
8️⃣ Context Retrieval
9️⃣ LLM Reasoning (Gemini / GPT)
🔟 Response Generation & Display
This architecture allows EDUBOT to provide reliable answers derived directly from the uploaded documents, ensuring accuracy, explainability, and transparency in every generated response.
.png?versionId=yRIV3jGAlwzo.DQacMCk7icWdUpeFs7P&Expires=1784811802&Key-Pair-Id=K3EVG0QTJR4SK0&Signature=YRXa-rkeCAgQ24Io7oBVTUX8IzzUoYbm3hLU8Htqacl83TxuxnB9dkeWcEaL6W7J5F6SUiys4717Q8-eoyg1kwK6GmkEPnAoB3g1oD4~8M~AtJmKo3o~ffFtK03r5ugVLfqUJCw07PdpgEJkQDRfmGxBKqEZDFm9BHo55jEIHQzHy9iqeTJzfLGuSDQ5kkW7hS5CkgU1I9ybHruNmOQqov14C3PGB2OJCcUcOmUgsXBFgAuw5jXKQI2DY3uxxkVL02w3pygyL5FHg6EDNFq5KRLSbGpbyRTlyE8lD0JGwtPyOQ9CuDoPcg6DzcIDI~eUHKqB5MtFSr86jy7jt6BXYA__)
Make sure you have Python 3.11+ installed, then run:
pip install streamlit langchain langgraph faiss-cpu sentence-transformers transformers easyocr google-generativeai evaluate rouge-score python-docx PyPDF2 python-pptx openpyxl pillow python-dotenv
Place your TXT, PDF, PPTX, DOCX, or XLSX files inside the Data/ folder.
Ensure PDFs are text-based (not scanned images).
python "Document ingestion.py"
streamlit run app.py
Ask a question:
What are the applications of Artificial Intelligence?
Answer:
Artificial Intelligence (AI) is applied in robotics, healthcare, education, autonomous vehicles, and recommendation systems.
It enables machines to perform human-like decision-making, perception, and learning.
Sources: ai_notes.pdf
The Watcher Agent continuously monitors the Data directory for new, modified, or deleted files.
When a change is detected, it automatically triggers the LangGraph ingestion workflow.
Each document is loaded, split into semantic chunks, embedded using Hugging Face MiniLM, and stored in the FAISS vector database.
Old Chunks: Previously existing embeddings.
Added Chunks: New embeddings from newly uploaded documents.
Deleted Chunks: Removed embeddings from deleted files.
After ingestion, the FAISS store is updated instantly, ensuring that the latest study materials are always available for retrieval during user queries.
.png?versionId=Q7KoPi3sIxTRMVlU3h090CRV7inp48.v&Expires=1784811802&Key-Pair-Id=K3EVG0QTJR4SK0&Signature=vxjbMZXJZx1fCqV9LA4jeH7W4OqmtjVa7zv59fCVTgnMFGsYeZyj1ggnFgSXc97DnPTP2fdsYvJiF-3kicbQXty~64OuAYastGK1eDjib53kQtLynYN0uI9LPDmPtgA5Qu~F4XlNU5~p7ginRZbhfmlQpcmz7-J9oA6QOfLwE2-JWev3POle4wwdpJfGad0c~OOclx9JyaMl8QO60m1zKCWzbjFdsUfAReTTkB-me3oUIdr7absj3dnAUpvWHxu4K7B4IoIDz5PQYhWuxeinIzvzm0YR5Zs4pywLQ7EZXemjBI1SdpGtF2db4C7rU38aX6~2KXvbLk8nWHDAROc~Sg__)
User: “What is Retrieval-Augmented Generation (RAG)?”
Output:
Process Flow:
The system first searches the FAISS vector database for relevant text chunks that match the user’s question using semantic similarity.
If relevant context is found within the uploaded documents, EDURAG retrieves those chunks and constructs a detailed answer grounded in the user’s own study material.
If no relevant data exists in the FAISS store, the system automatically switches to LLM-based reasoning (Google Gemini 2.0 Flash) to generate an accurate explanation using general academic knowledge.
.png?versionId=ZFtGispcdtACO8BNeRfDClhjMHaOtIBe&Expires=1784811802&Key-Pair-Id=K3EVG0QTJR4SK0&Signature=YbqRXEMowrjgPTJOWoIxrv5NGKwE~2os2hLhQBVuW~QJ2BxSLsiBvMluRMN13fJdwV-iGAXWBJPvenvrqJGfCJUvKDRIEXwvt7-VBCkdocenWrQyrJnW~MmIVgHRpVBhH-df0aI6cP5Y6BjtWtlq0c9jD39HITv6mN9HslV7AW4ml-fHdSl0hT9MmxzOnnyY6IUB17HDINyYF9trtKGBuF7es3M0EcIHk1i1a5Z3xlqNGVeAh-fpxR7TciSQ-aj7ViFrI6EIoA5k8HFaGQlRE2lewz8Ln1t0RvS~Zeq2oPM-ayGq7tyS3XXq-kpsJ2cOQtjEBOA~pKXB~NoVwvrlhA__)
.png?versionId=au3eEn6glH9xMOxKlZ1t_0eBL8.a.Psr&Expires=1784811802&Key-Pair-Id=K3EVG0QTJR4SK0&Signature=bA2qon5xRjUqPjEZ2Uki90SVECla0YgYTl5X66B0pG55zNX3n4Qu2X7uS-zV~a9-FvfjI3SJvRrqISe3v3ES3UKiV58S5~Et439dwaO~rhxBTmCdsRnvnDQa5jKG86rd-w1E4Ij08H-zGezlxLhcE1DlR26L1c~F6lbAmaxadtohfvfUa--h7kfMdETHA12CrhNn7qOmJKkgryRoX~dGVf-ChIwLXOju1cj0JUFUjyF0-kjYy4tqSAvuZzaGw0y~0l7x7r-RaS8kT1KSXOgHn3oAaWhLilrO1-Vh4dDaDZtxnDTaE4csA5X0qwNsv0ZYhniymv~Xo9Lla9xTBkETDg__)
• Operating System: Windows 10/11, Linux (Ubuntu 20.04+), macOS 11+
• Python Version: 3.10 or higher (tested on 3.11)
• RAM: Minimum 8 GB (16 GB recommended for faster embedding and LLM inference)
• Storage: 5–10 GB free (for vector DB, logs, and local documents)
• GPU (Optional): NVIDIA GPU with CUDA support for BLIP and EasyOCR acceleration
• Dependencies: Refer to requirements.txt or setup instructions above
• LLM: Google Gemini 2.0 Flash
• Frameworks: LangChain, LangGraph, Streamlit
• Embeddings: HuggingFace MiniLM (all-MiniLM-L6-v2)
• Vector Database: FAISS (local persistent store)
• OCR & Image Captioning: EasyOCR, BLIP (Salesforce)
• Document Loaders: LangChain Unstructured, PyPDFLoader, Docx2txt, PowerPoint, Excel loaders
• Evaluation Metrics: BLEU, ROUGE, Cosine Similarity
• Memory: ConversationBufferMemory (LangChain)
• Logging: Auto timestamped logs for ingestion & updates
• UI: Streamlit with custom HTML/CSS chat interface
✅ Agentic document ingestion using LangGraph workflow (detect → ingest → validate)
✅ Real-time RAG assistant powered by Google Gemini 2.0 Flash
✅ Multi-file support with auto text extraction (PDF, DOCX, PPTX, XLSX, TXT)
✅ Memory-based conversation management for contextual responses
✅ Semantic evaluation using BLEU, ROUGE, and cosine similarity metrics
✅ Integrated image-to-text and captioning (EasyOCR + BLIP)
✅ Auto logging of ingestion activity and FAISS vector updates
✅ Modern Streamlit UI with chat history, new chat, and logout features
⚡ Avg. Response Time: 2–4 seconds (text)
📊 Semantic Similarity: ≥ 0.85 (average on reference-based tests)
🧮 Evaluation Metrics: BLEU, ROUGE-L, and Cosine Similarity
🧠 Memory Retention: Full conversation buffer (preserves context during chat)
This project is licensed under the GNU General Public License v3.0 (GPL-3.0).
You are free to use, modify, and distribute this software under the same license terms.
🔹 LangChain / LangGraph — For building the ingestion and retrieval orchestration backbone.
🔹 Hugging Face — For providing open-source embedding and summarization models.
🔹 Google Gemini — For powering the LLM responses with contextual reasoning.
🔹 Streamlit — For creating an elegant and interactive user interface.
🔹 AAIDC Module 2 Program — For project structure, certification guidance, and evaluation standards.
| Metric | Description | Average Score |
|---|---|---|
| Semantic Similarity | Alignment between FAISS context & generated explanation | 0.93 |
| Answer Accuracy | Conceptual correctness & educational clarity | 91% |
| File Ingestion Reliability | Multi-format ingestion success (PDF, PPT, DOC, XLS, TXT) | 96% |
| Context Retention (10 turns) | Maintains memory continuity across student follow-ups | Stable |
| Summarization Quality | LLM-generated summaries of uploaded files | 88% |
| Vector Update Responsiveness | Watcher agent triggers ingest within 5s of file changes | 100% |
The EDURAG system establishes a robust and scalable framework for intelligent educational assistance. By combining LangGraph-based ingestion, FAISS vector storage, and Gemini-powered reasoning, it delivers contextually accurate and explainable responses grounded in real academic data. The system demonstrates strong semantic alignment, high retrieval precision, and consistent contextual retention, supported by automated monitoring and real-time updates. Overall, EDURAG represents a reliable, ethical, and adaptable AI model designed to enhance personalized learning and redefine the future of academic interaction.
Document Updates:
Whenever new study materials are added (e.g., in Data/), run the ingestion workflow to generate embeddings for the new chunks.
Recomputing Embeddings:
If documents change significantly, rerun the embedding generation using the same embedding model (all‑MiniLM‑L6-v2) to keep vector representations consistent.
Model Versioning:
To upgrade your LLM (for example, switch from Gemini v1 to a newer version), update the model configuration in your code (e.g., config.yaml), and validate responses.
Logging & Monitoring:
The ingestion agent logs chunk addition/deletion and timing. Monitor update_log.txt (or your log directory) to track ingestion health.
Error Handling:
If ingestion fails for a file, the validation step detects mismatches in chunk counts — re-trigger ingestion for that file.
Scalability:
The LangGraph-based workflow is modular: you can plug in more agents (e.g., for summarization, translation) or extend the RAG pipeline to handle new document types.
This project, EDURAG, is released under the GNU General Public License v3.0 (GPL-3.0).
✔️ Commercial and private use
✔️ Distribution and modification
✔️ Patent use permitted
Permissions under this strong copyleft license require that the complete source code of all licensed works and derivative projects (including larger systems using EDURAG) be made available under the same license terms.
All copyright and license notices must be preserved.
Contributors provide an express grant of patent rights to ensure open and transparent software use.
A full license text is included in the accompanying LICENSE file.
When redistributing, please retain all copyright and attribution notices.
Model and API Licenses
External components such as Google Gemini, are governed by their respective creators’ licenses.
Ensure compliance with each provider’s terms when integrating, modifying, or extending these third-party components within the EDURAG framework.
| Asset | Link / Location |
|---|---|
| Source Code | https://github.com/pamuarun/EDURAG-AGENTIC-AI-RAG |
| Example Outputs | Available in the outputs/ folder and logs of the GitHub repository and response examples from the EDURAG system. |
By orchestrating specialized educational AI agents with structured retrieval and reasoning mechanisms, EDURAG demonstrates that accurate, explainable, and context-aware learning systems can be developed without depending solely on proprietary or opaque cloud infrastructures.
Data Integrity: Ensures reliable and verifiable responses through retrieval-augmented verification using FAISS embeddings and context-based reasoning.
Transparency: Fully open-source and auditable under GPL-3.0, supporting academic review, educational research, and reproducibility.
Scalability: Each agent is modular and independent, allowing seamless integration of additional language models, subject domains, or multimodal extensions.
Ethical AI in Education: Promotes safe, research-backed knowledge delivery with strict academic content filtering and responsible AI alignment.
This framework serves as a foundation for developers, educators, and research institutions aiming to build open, agentic AI architectures for academic assistance and intelligent tutoring ensuring transparency, reliability, and scalability in the future of educational technology.