Docker is a core tool in modern software development, but its documentation is extensive and often difficult to navigate efficiently. Developers frequently struggle to find precise answers to questions related to volumes, Dockerfile instructions, and container behavior using traditional keyword-based search.
This project presents a Docker RAG Assistant that combines semantic search with Retrieval-Augmented Generation (RAG) to provide accurate, context-aware answers grounded in official Docker documentation. Instead of returning links, the assistant retrieves the most relevant documentation sections and generates concise answers with explicit source citations, improving both accuracy and trust.
Docker documentation is large, fragmented, and spread across many pages. Developers often waste time searching for specific information such as command behavior or configuration details.
Traditional keyword-based search fails to capture semantic intent and does not provide direct, well-contextualized answers. Additionally, it does not clearly indicate which documentation sources were used to generate a response.
Retrieval-Augmented Generation is well suited for technical documentation use cases. Rather than relying solely on a language model’s internal knowledge, RAG retrieves relevant documentation sections and uses them as context for answer generation.
For Docker documentation, this approach ensures that answers are accurate, grounded in authoritative sources, and aligned with real-world developer queries expressed in natural language.
The Docker RAG Assistant uses a modular pipeline that:
.txt filesThis design enables fast, reliable, and explainable documentation search.
The system follows a standard Retrieval-Augmented Generation pipeline.
Docker documentation files are first loaded and processed into overlapping text chunks. Each chunk is converted into a vector embedding using the sentence-transformers/all-MiniLM-L6-v2 model and stored in ChromaDB for semantic search.
When a user submits a query, the most relevant documentation chunks are retrieved and passed to Groq’s LLaMA 3 model (llama-3-8b-instant). The model then generates an answer grounded in the retrieved context and returns the response along with explicit source citations.
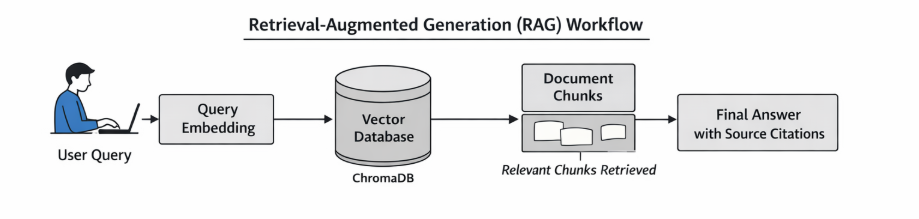
Docker documentation pages often contain multiple related concepts within a single file. To enable effective retrieval, documents are split into smaller overlapping chunks before embedding.
In this project, documentation is divided into chunks of approximately 500 tokens with an overlap of 50 tokens. This chunk size preserves sufficient technical context while maintaining retrieval precision. The overlap ensures that important information spanning chunk boundaries is not lost, improving the quality of retrieved results.
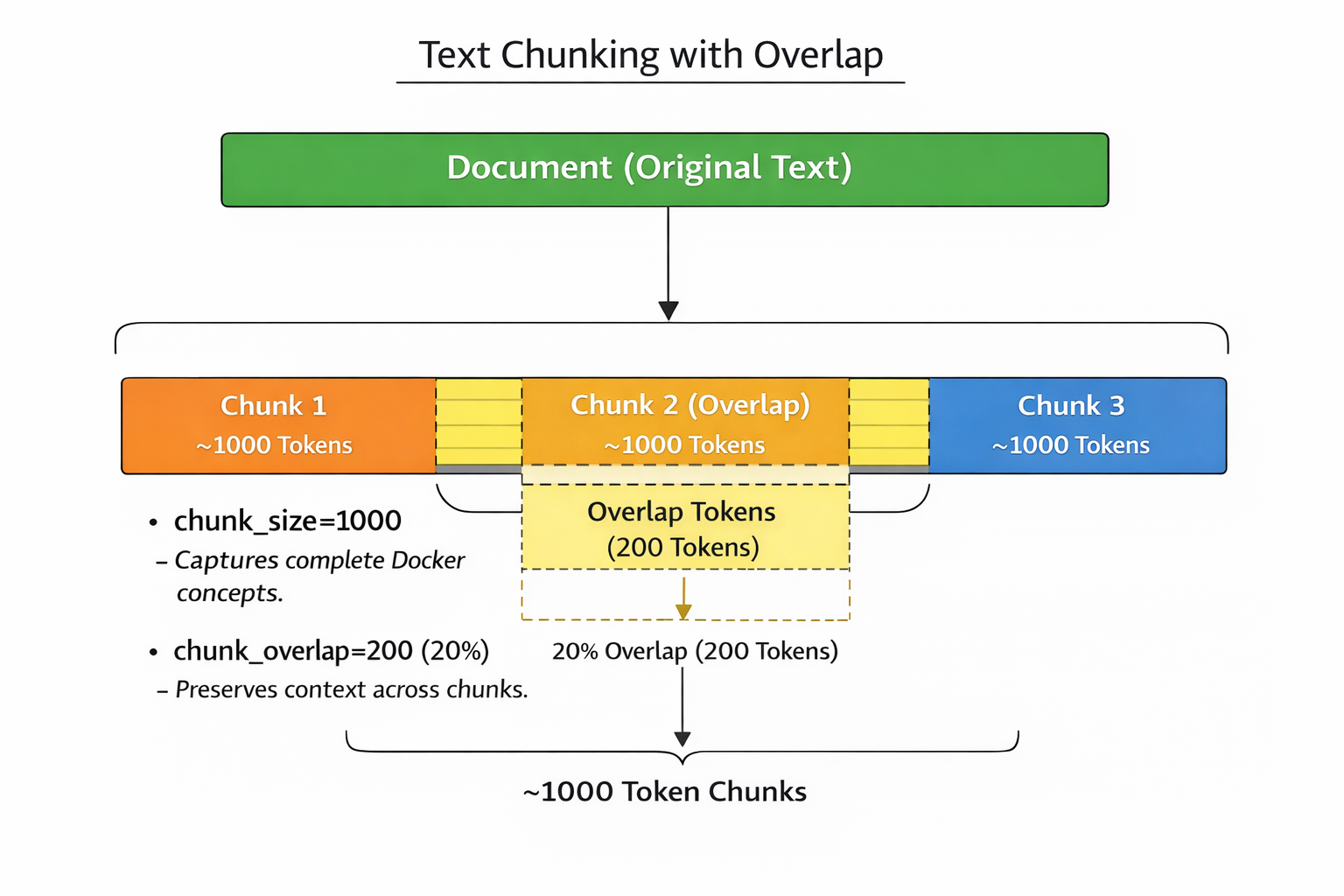
When a user asks a question such as “What is a Docker volume?”, the system converts the query into an embedding and retrieves the most semantically relevant documentation chunks from the vector database.
These chunks are then provided as context to the language model, which generates a concise and accurate explanation. The final response includes references to the exact documentation files used, allowing users to verify the source of the information.
Q: What is a Docker volume?
A: A Docker volume persists data outside the lifecycle of a container. It can be shared across containers and remains even when a container is removed.
Sources: docker_volume_overview.txt, docker_bind_mounts.txt
Q: How does the VOLUME instruction in a Dockerfile work?
A: The VOLUME instruction creates a mount point inside the container and marks it for external volumes so data written there is persisted outside the container layer.
Sources: dockerfile_reference.txt
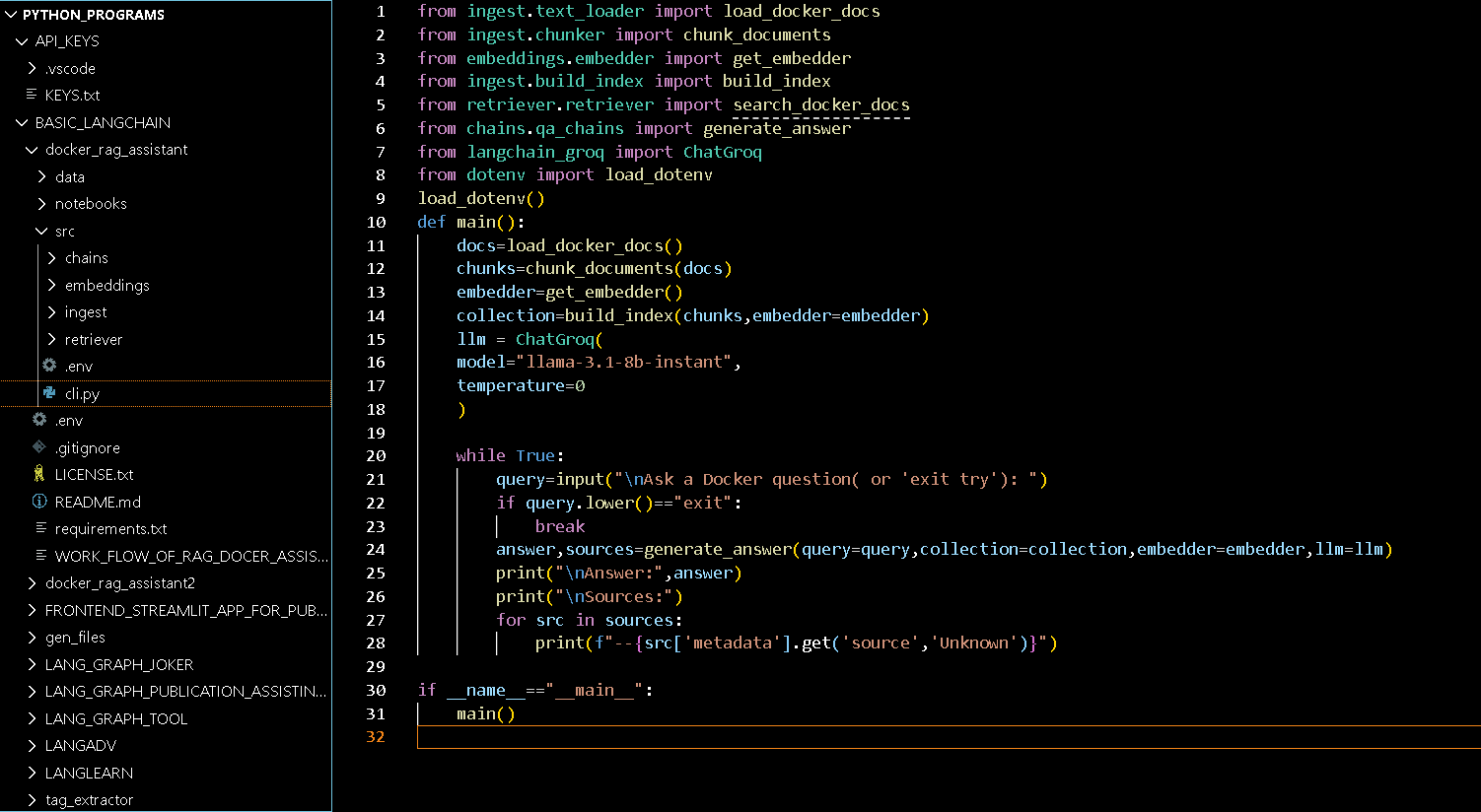
pip install -r requirements.txt python src/cli.py
The current system relies solely on semantic retrieval, which may miss exact keyword matches for certain Docker commands. Introducing hybrid search can further improve retrieval accuracy.
Future improvements include supporting multi-turn conversations, adding automated evaluation, and expanding the knowledge base to include related technologies such as Kubernetes and FastAPI.
This project demonstrates how Retrieval-Augmented Generation can be effectively applied to technical documentation. By grounding responses in official Docker documentation and providing clear source citations, the assistant improves search efficiency, reduces developer friction, and offers a reusable blueprint for documentation assistants in other domains.
