Government policy documents contain valuable information, but they are often difficult to search and understand. They are usually long, written in formal language, and spread across multiple websites. Users must manually read large documents to find answers to simple questions, which is time-consuming and often frustrating.
Policy-RAG-BOT solves this problem by providing an intelligent chatbot that can answer questions directly from official policy documents. Instead of generating answers from general knowledge, the system retrieves relevant parts of the document and uses them to produce grounded and reliable responses. This ensures that answers remain accurate, transparent, and verifiable, addressing the critical need for trustworthy information access in the government policy domain.
This project demonstrates the approach using the Year-End Review 2024: Ministry of Environment, Forest and Climate Change (India). However, the system is designed to work with any government policy document, report, or publication, making it a flexible and adaptable solution for various policy domains.
Government documents present several significant accessibility challenges that hinder effective information retrieval. Information is difficult to search efficiently because traditional keyword-based search methods often fail to capture the semantic meaning of queries. Documents are long and complex, frequently spanning hundreds of pages with dense technical language that makes quick fact-finding nearly impossible. Users cannot easily extract specific facts without reading through entire sections, and traditional chatbots may hallucinate incorrect answers when they lack proper grounding in source documents.
These limitations significantly reduce accessibility and trust in automated information systems. The goal of this project is to build a system that addresses these challenges comprehensively. The system answers questions directly from policy documents without making assumptions or fabricating information. It avoids hallucinations by strictly adhering to retrieved context, refuses to answer when information is unavailable rather than guessing, and provides a simple conversational interface that makes complex policy information accessible to all users.
Policy-RAG-BOT uses a Retrieval-Augmented Generation (RAG) architecture to ensure accurate and grounded responses. Instead of relying only on a language model's general knowledge, which can lead to hallucinations or outdated information, the system first retrieves relevant document sections and then generates answers using that retrieved information. This two-stage process ensures responses remain grounded in official sources and can be verified against the original documents.
Document → Chunking → Embedding → Vector Database User Question → Query Processing → Retrieval → LLM → Answer
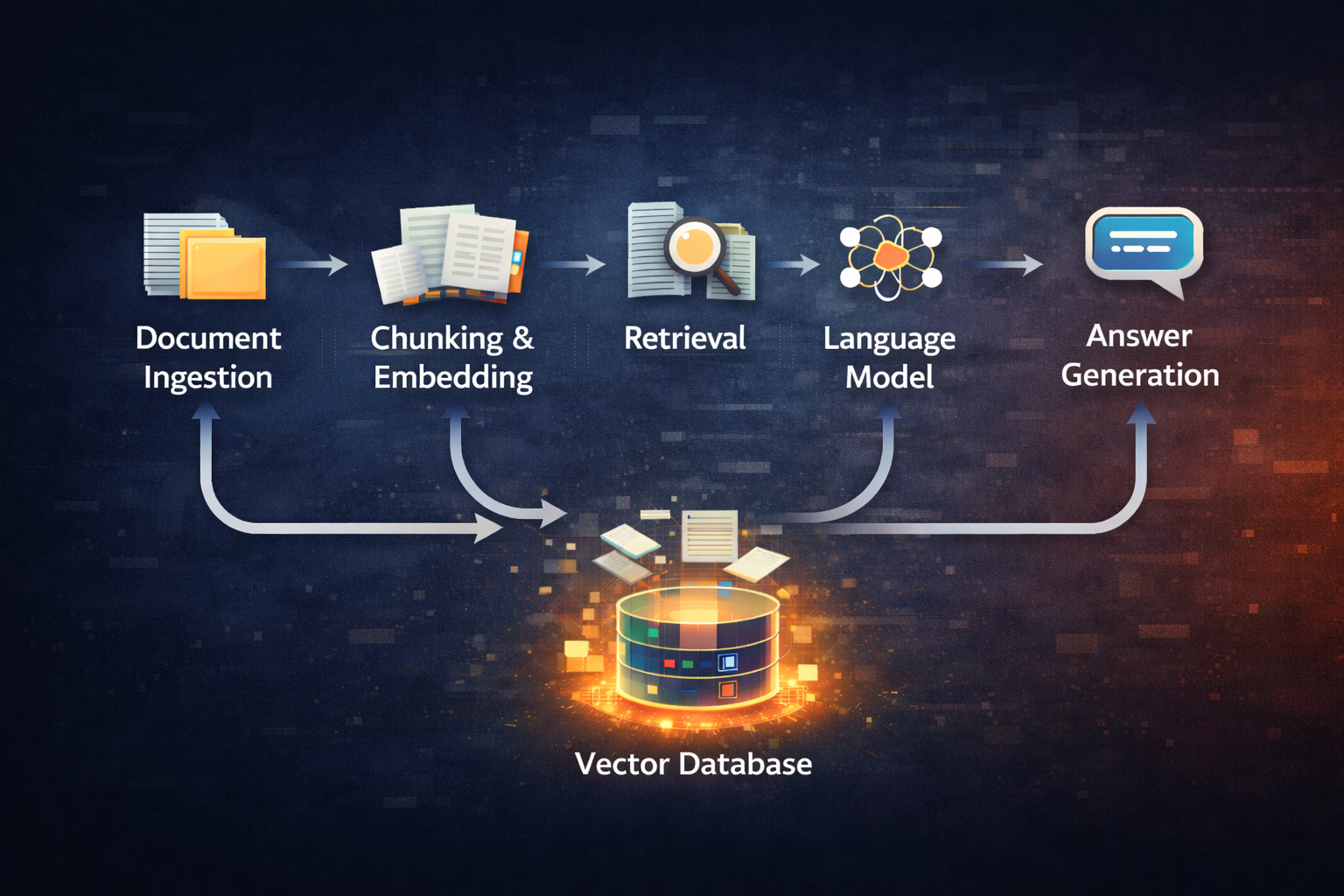
The system operates through four main stages that work together seamlessly. First, document ingestion loads and processes policy documents into a format suitable for retrieval. Second, document chunking and embedding converts text into semantic vectors that capture meaning. Third, retrieval of relevant document sections uses similarity search to find the most pertinent information. Finally, answer generation using retrieved context produces natural language responses grounded in official sources.
Policy documents are loaded from the local data/ folder, which serves as the central repository for all policy materials. The system supports multiple document formats to accommodate various government publication standards. PDF files are the primary format, as most government reports are published in this format, and text files provide an alternative for simpler documents or extracted content.
The loading process uses LangChain's directory loader to systematically process all documents in the data folder:
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader loader = DirectoryLoader("data/", glob="*.pdf", loader_cls=PyPDFLoader) documents = loader.load()
This automated approach ensures that new documents can be added simply by placing them in the data folder, requiring no code modifications.
Documents are split into smaller overlapping chunks to optimize retrieval performance. The chunking process is critical because it determines how information is organized and retrieved. Large chunks may contain too much irrelevant information, while small chunks may lack sufficient context for meaningful retrieval.
The configuration balances these competing concerns:
CHUNK_SIZE = 500 CHUNK_OVERLAP = 50
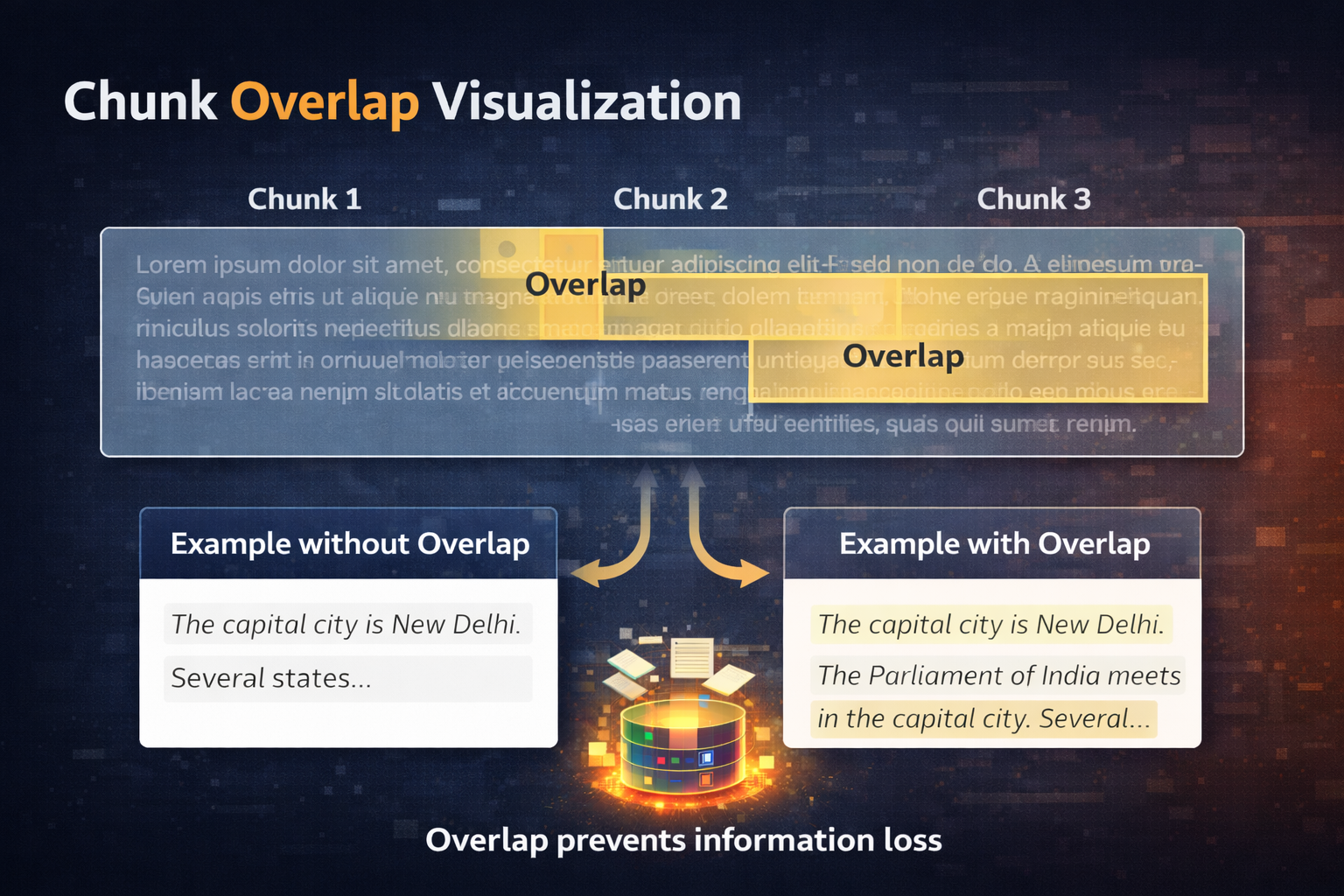
Chunk overlap prevents loss of information at chunk boundaries, which is essential for maintaining context. Without overlap, important sentences may be split incorrectly, reducing retrieval accuracy. For example, a sentence spanning a chunk boundary would be split, potentially losing its complete meaning. The 50-character overlap ensures that critical information near boundaries appears in both adjacent chunks, improving the likelihood of successful retrieval.
The implementation uses LangChain's RecursiveCharacterTextSplitter, which intelligently splits text at natural boundaries:
from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50 ) chunks = text_splitter.split_documents(documents)
Each chunk is converted into a vector embedding that captures its semantic meaning. Embeddings transform text into numerical representations that enable mathematical comparison of semantic similarity. This process is fundamental to the retrieval system's ability to find relevant information based on meaning rather than just keyword matching.
The system uses the sentence-transformers/all-MiniLM-L6-v2 model, which is specifically optimized for semantic similarity tasks:
from langchain_huggingface import HuggingFaceEmbeddings embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L6-v2" )
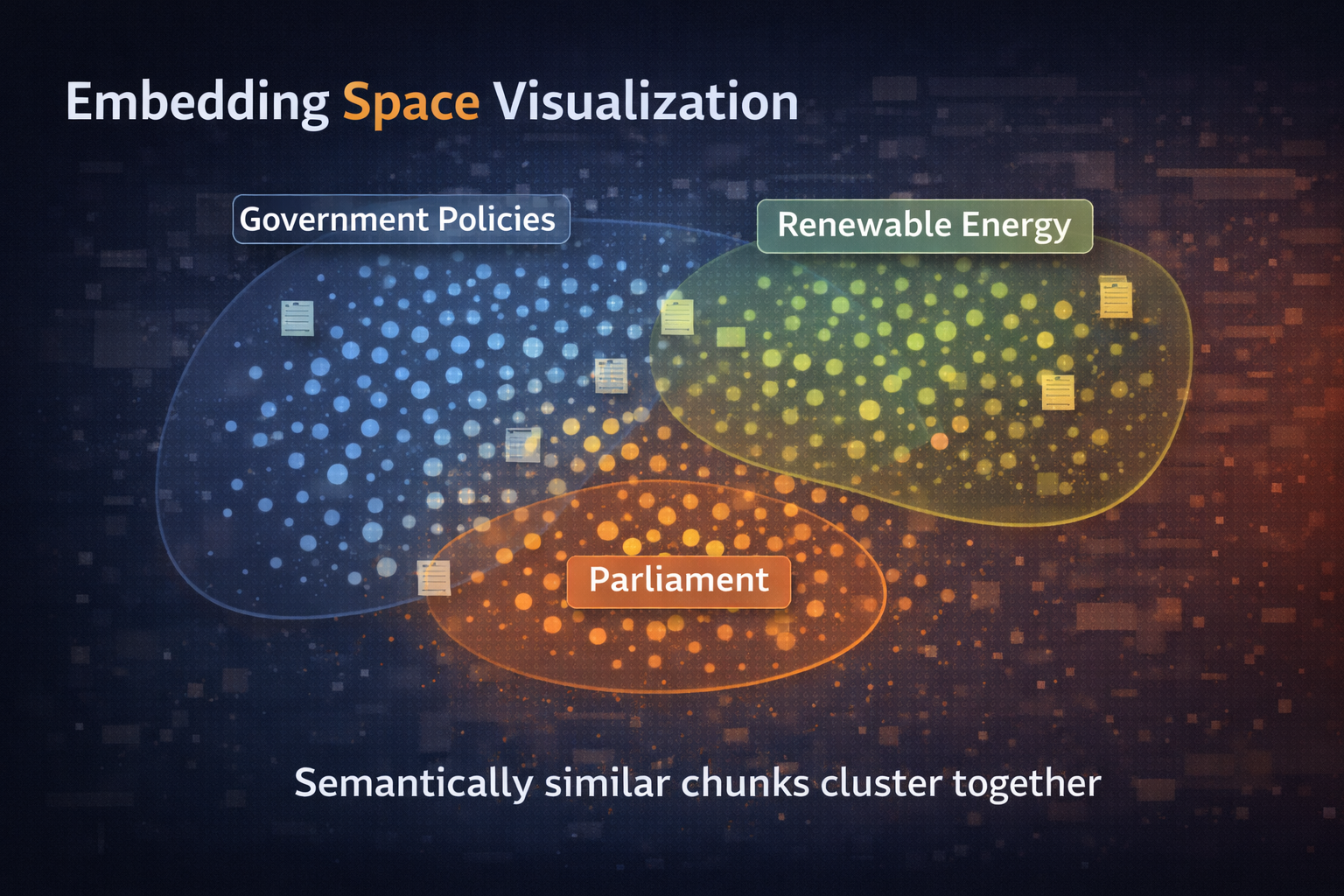
Embeddings capture semantic meaning by encoding words and phrases into high-dimensional vectors where similar meanings are represented by similar vectors. This enables the system to find relevant information even when queries use different vocabulary than the source documents, a capability that traditional keyword search cannot provide.
Embeddings are stored in a Chroma vector database, which provides efficient similarity search capabilities. The vector database acts as a semantic index, allowing rapid retrieval of relevant chunks based on their embeddings. Unlike traditional databases that search for exact matches, vector databases find the most similar vectors, enabling semantic search.
from langchain_chroma import Chroma vector_db = Chroma.from_documents( documents=chunks, embedding=embeddings, persist_directory="vector_db" )
The persist_directory parameter ensures that the vector database is saved to disk, eliminating the need to reprocess documents every time the system starts. This significantly improves startup time and enables the system to handle large document collections efficiently.
User queries are preprocessed before retrieval to improve consistency and accuracy. Query preprocessing normalizes input by removing extraneous whitespace, standardizing formatting, and preparing the query for embedding. While the current implementation is simple, this modular design allows for future enhancements such as query expansion or reformulation.
def preprocess_query(query: str) -> str: return query.strip()
This preprocessing step improves retrieval consistency by ensuring that minor formatting variations in user queries don't affect the embedding process, leading to more reliable retrieval results.
The system retrieves relevant chunks using semantic similarity search, which compares the query embedding against all chunk embeddings in the database. The retrieval process ranks chunks by their similarity to the query and returns the top K most similar chunks, where K is a configurable parameter.
RETRIEVAL_K = 4
The choice of K=4 balances between providing sufficient context for answer generation while avoiding overwhelming the language model with too much information. Retrieving too few chunks may miss important context, while retrieving too many may introduce noise that degrades answer quality.
retriever = vector_db.as_retriever( search_kwargs={"k": 4} )
The retrieved chunks are passed to a Large Language Model along with carefully crafted instructions. The prompt engineering ensures that the model generates answers strictly from the provided context, maintaining the system's commitment to grounded and verifiable responses.
prompt = """ Answer using ONLY the context below. <context> {context} </context> Question: {input} """
This prompt structure is critical for preventing hallucinations. By explicitly instructing the model to use only the provided context, the system ensures that answers are grounded in the actual policy documents rather than the model's general knowledge, which may be outdated or incorrect for specific policy details.
The system uses a centralized configuration file (config.py) that consolidates all tunable parameters in a single location. This design principle improves maintainability by allowing system behavior to be adjusted without modifying core logic. Researchers and practitioners can experiment with different configurations to optimize performance for their specific use cases.
EMBEDDING_MODEL = "sentence-transformers/all-MiniLM-L6-v2" CHUNK_SIZE = 500 CHUNK_OVERLAP = 50 RETRIEVAL_K = 4 VECTOR_DB_DIR = "vector_db"
This centralized configuration provides several important benefits. Easy tuning allows rapid experimentation with different parameter values without searching through code. Maintainability is enhanced because all system parameters are documented in one location. Reproducibility is ensured because the configuration file serves as a complete record of system settings, enabling others to replicate experiments exactly.
The system includes two complementary evaluation approaches to ensure high-quality retrieval performance. Evaluation is essential for understanding system behavior, identifying weaknesses, and guiding improvements.
Retrieval quality is evaluated using a dedicated evaluation script that tests the system's ability to find relevant information:
python evaluate.py
The evaluation process systematically tests retrieval with predefined queries that represent typical user information needs:
queries = [ "What environmental initiatives were launched in 2024?" ] for query in queries: docs = retriever.invoke(query) print("Retrieved chunks:", len(docs))
Example output demonstrates the system's retrieval behavior:
Retrieved chunks: 4
Top chunk preview:
The Ministry launched several environmental initiatives...
This basic evaluation provides immediate feedback on whether the retrieval system is finding relevant information and helps identify queries that may require system tuning.
The evaluation framework extends beyond basic retrieval testing to examine how different chunking strategies affect retrieval performance. Chunk overlap refers to the shared text between consecutive document chunks, and proper overlap is crucial for preventing information loss at chunk boundaries.
Consider a concrete example: without overlap, a sentence like "The budget was 15 million rupees for environmental restoration" might be split across two chunks. The first chunk might end with "The budget was" while the second chunk starts with "15 million rupees for environmental restoration." When a user asks about the budget for environmental restoration, neither chunk contains the complete information, potentially causing retrieval to fail or return incomplete context.
The evaluation framework enables systematic testing of different chunking configurations:
def evaluate_overlap_strategy(chunk_size, overlap, test_queries): """ Test retrieval accuracy with different overlap settings """ text_splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=overlap ) chunks = text_splitter.split_documents(documents) vector_db = Chroma.from_documents(documents=chunks, embedding=embedding_model, persist_directory=DB_PATH) retriever = vector_db.as_retriever(search_kwargs={"k": 4}) results = [] for query in test_queries: docs = retriever.invoke(query) results.append({ "query": query, "retrieved_chunks": len(docs), "preview": docs[0].page_content[:100] if docs else "No results" }) return results
The comparison process tests multiple overlap configurations to identify optimal settings:
# Define test queries that represent common information needs test_queries = [ "What was the budget allocation for 2024?", "Which environmental schemes were launched?", "How many projects were sanctioned?" ] # Test different overlap configurations ranging from no overlap to substantial overlap strategies = [ {"chunk_size": 500, "overlap": 0}, # No overlap - baseline {"chunk_size": 500, "overlap": 50}, # 10% overlap (current default) {"chunk_size": 500, "overlap": 100}, # 20% overlap - moderate {"chunk_size": 500, "overlap": 150}, # 30% overlap - high ] for strategy in strategies: print(f"\n=== Testing: Chunk Size={strategy['chunk_size']}, Overlap={strategy['overlap']} ===") results = evaluate_overlap_strategy( chunk_size=strategy['chunk_size'], overlap=strategy['overlap'], test_queries=test_queries ) for result in results: print(f"Query: {result['query']}") print(f"Retrieved: {result['retrieved_chunks']} chunks") print(f"Preview: {result['preview']}\n")
Example output comparison illustrates how overlap affects retrieval:
=== Testing: Chunk Size=500, Overlap=0 ===
Query: What was the budget allocation for 2024?
Retrieved: 3 chunks
Preview: The Ministry allocated funds across...
=== Testing: Chunk Size=500, Overlap=50 ===
Query: What was the budget allocation for 2024?
Retrieved: 4 chunks
Preview: allocated funds across various environmental programs. The budget for 2024...
=== Testing: Chunk Size=500, Overlap=100 ===
Query: What was the budget allocation for 2024?
Retrieved: 4 chunks
Preview: environmental programs. The budget for 2024 included 15 million rupees...
This systematic evaluation approach enables data-driven optimization of the retrieval system. Users can test different overlap sizes to find the optimal configuration for their specific documents and query patterns. The evaluation helps identify information loss at chunk boundaries by revealing cases where important facts are split across chunks. By comparing retrieval accuracy across strategies, practitioners can make informed decisions about chunking parameters based on empirical evidence rather than intuition.
The evaluation also allows optimization of system performance based on document characteristics, as different types of documents may benefit from different chunking strategies. Technical documents with dense information may require higher overlap, while narrative documents may work well with lower overlap.
In this project, an overlap of 50 characters was selected as a balanced configuration between retrieval accuracy and computational efficiency. This choice represents approximately 10% overlap, which provides sufficient context preservation while maintaining reasonable storage requirements. However, users are encouraged to experiment with different values to improve retrieval quality for their specific documents, as optimal settings may vary depending on document structure, language, and typical query patterns.
Begin by cloning the repository from GitHub to your local machine:
git clone https://github.com/nisg-phys/RAG-BOT-MEMORY.git cd RAG-BOT-MEMORY
Create an isolated Python environment to avoid dependency conflicts with other projects:
python -m venv .venv source .venv/bin/activate
The virtual environment ensures that all dependencies are installed in isolation, preventing version conflicts and making the installation reproducible.
Install all required Python packages using the provided requirements file:
pip install -r requirements.txt
This command installs LangChain, Streamlit, Chroma, and all other necessary dependencies with their correct versions.
Copy the example environment file and configure your API keys:
cp example.env .env
Edit the .env file to add your API keys for the LLM provider you wish to use (Groq, OpenRouter, or Hugging Face).
Place your policy documents inside the data/ folder. The system will automatically discover and process all supported files in this directory. You can add PDFs, text files, or any other supported document format.
Process the documents and create the vector database by running:
python vectordb.py
This step loads all documents from the data folder, splits them into chunks, generates embeddings, and stores them in the vector database. This process needs to be run only once unless you add new documents.
Launch the interactive chatbot interface:
streamlit run main.py
This command starts a local web server and opens the chatbot interface in your default browser. You can now ask questions about the policy documents.
The chatbot provides a conversational interface for querying policy documents. When you ask a question such as "What environmental achievements were reported in 2024?", the system retrieves relevant sections from the documents and generates a grounded answer based on that context.
When the system cannot find relevant information to answer a question, it refuses gracefully with a message like "I am not an expert in that." This refusal mechanism is crucial for maintaining trust, as it prevents the system from hallucinating answers when information is unavailable in the source documents.
The system leverages a carefully selected set of technologies that work together to enable reliable document-based question answering. Python serves as the primary programming language, providing a rich ecosystem of libraries for natural language processing and machine learning. LangChain and Streamlit form the core frameworks, with LangChain orchestrating the RAG pipeline and Streamlit providing the user interface. Chroma serves as the vector database, enabling efficient semantic search over document embeddings. The sentence-transformers/all-MiniLM-L6-v2 model generates embeddings that capture semantic meaning, while multiple LLM providers (Groq, OpenRouter, and Hugging Face) offer flexibility in choosing the language model backend.
| Component | Technology |
|---|---|
| Language | Python |
| Frameworks | LangChain, Streamlit |
| Vector Database | Chroma |
| Embedding Model | sentence-transformers/all-MiniLM-L6-v2 |
| LLM Providers | Groq, OpenRouter, Hugging Face |
The system incorporates several key features that work together to ensure reliable and trustworthy question answering. Grounded question answering ensures that all responses are based on retrieved document content rather than general knowledge. Hallucination prevention through strict prompt engineering keeps the model from fabricating information. Query preprocessing normalizes user input to improve retrieval consistency. Configurable retrieval allows tuning of parameters to optimize performance for specific use cases. The evaluation framework enables systematic testing and improvement of retrieval quality. Finally, the modular architecture facilitates easy extension and customization of system components.
While Policy-RAG-BOT provides significant improvements over traditional search methods, it does have important limitations that users should understand. The system works only with documents that have been ingested into the vector database, meaning it cannot answer questions about documents it hasn't processed. It cannot access live external data or retrieve information from websites or databases in real-time. The retrieval quality depends fundamentally on document quality; poorly written, incomplete, or ambiguous source documents will result in poor retrieval and answer quality. Additionally, the system's performance is constrained by the capabilities of the underlying language model and embedding model, which may struggle with highly specialized technical language or domain-specific terminology not well-represented in their training data.
Several planned improvements will enhance the system's capabilities and reliability. Hybrid retrieval methods will combine semantic search with keyword-based search to improve coverage and precision. Query rewriting will automatically reformulate user questions to improve retrieval success rates. Source citation will explicitly link answers to specific document sections, making verification easier. Multi-document support will enable the system to synthesize information across multiple policy documents. Improved evaluation metrics will provide more comprehensive assessment of retrieval and answer quality, including measures of relevance, completeness, and accuracy.
Policy-RAG-BOT demonstrates how Retrieval-Augmented Generation can fundamentally improve access to government policy documents by making them searchable through natural language questions. By combining document retrieval with language models, the system produces grounded, reliable, and transparent answers that users can trust and verify.
This approach improves accessibility by eliminating the need for users to manually search through long documents, and improves trust by ensuring that answers are grounded in official sources rather than potentially hallucinated information. The methodology can be extended to many domains beyond government policy, including law, healthcare, research, education, and any field where reliable access to document-based knowledge is critical. As retrieval-augmented generation techniques continue to evolve, systems like Policy-RAG-BOT will play an increasingly important role in democratizing access to complex information.