Extending the evidence–practice gap solution from RAG retrieval into coordinated clinical reasoning — using specialized AI agents to handle drug safety, risk stratification, and patient communication in parallel.
Phase I of this project — CardioSentinel_RAG — established a RAG-based guideline retrieval engine that transforms static cardiovascular guidelines into a queryable clinical knowledge system. It solved the first barrier of evidence-practice gap: getting the right evidence in front of the right person at the right time.
But retrieval alone is not enough.
A clinician querying a guideline engine still has to:
These are not retrieval problems. They are reasoning and coordination problems — and they call for a different architecture.
Phase I retrieved the evidence. Phase II coordinates evidence-informed workflows.
The three persistent barriers that motivated this phase:
Time pressure. A clinician must synthesize guideline recommendations, check drug safety, and assess risk simultaneously.
Medication safety at scale. A guideline recommendation is only safe in the context of what the patient is already taking.
Patient compliance. Evidence-based recommendations written in clinical language do not improve outcomes if patients cannot understand or act on them.
CardioSentinel MAS is a graph-orchestrated multi-agent clinical decision support system for cardiovascular disease management.
Where Phase I answers:
"What does the guideline say?"
Phase II answers:
"Given this specific patient, what is the safe, risk-stratified, actionable plan — explained at two levels: for the clinician, and for the patient?"
The purpose of CardioSentinel MAS is to demonstrate how a multi-agent clinical decision support architecture can coordinate evidence retrieval, risk assessment, medication safety checks, and patient communication into a single agentic system.
The project explores how modern orchestration frameworks, agentic state management, and human review systems can improve explainability, modularity, auditability, and safety in clinical decision support environments.
By the end of this phase, the system should be able to:
Retrieve guideline-grounded recommendations from the RAG layer
Quantify cardiovascular risk using structured patient factors
Detect major medication interactions and contraindications
Trigger clinician review for high-risk or unsafe workflows
Generate patient-friendly summaries of validated clinical plans
Maintain immutable workflow state and audit history
Combine all outputs into a unified structured report through graph-based orchestration
Continue functioning safely even when individual tools or agents fail
This is Phase II in the three-layer CardioSentinel ecosystem:
┌─────────────────────────┐ │ Guideline RAG Engine │ │ Evidence Retrieval │ └────────────┬────────────┘ │ ┌────────────▼────────────┐ │ LangGraph Orchestrator │ │ Multi-Agent Coordination│ └────────────┬────────────┘ │ ┌─────────────────────┼─────────────────────┐ │ │ │ ▼ ▼ ▼ Guideline Agent Risk Agent Medication Agent │ │ │ └──────────────┬──────┴──────────────┬─────┘ │ │ ▼ ▼ Human Review Layer (HITL) │ ▼ Patient Communication Agent │ ▼ Streamlit Clinical Interface
START ↓ INPUT VALIDATION ↓ GUIDELINE AGENT ↓ RISK AGENT ↓ [Risk ≥ Threshold?] ├── YES → HUMAN REVIEW └── NO ↓ MEDICATION AGENT ↓ [Safety Issues Detected?] ├── YES → HUMAN REVIEW └── NO ↓ PATIENT AGENT ↓ FINALIZE REPORT ↓ END

GuidelineRetrieverToolinsufficient_evidence, never fabricatesRiskScoreCalculator against the patient's age, blood pressure, LDL, and conditionsDrugInteractionTool: Checks every pair of inferred medications for known interactions. Severity-filtered — only major and contraindicated pairs block the pipeline.
ContraindicationChecker: Cross-references patient conditions against proposed medications.
All clinical knowledge lives in tools, not in agents. Agents are logic — tools are data. This separation means tools can be replaced with real data sources without touching agent code.
| Tool | What It Does Now |
|---|---|
GuidelineRetrieverTool | Returns hardcoded strings from a Python dict keyed by condition |
DrugInteractionTool | Checks a hardcoded dict of ~6 drug pairs |
ContraindicationChecker | Checks a hardcoded dict of ~8 condition–drug mappings |
RiskScoreCalculator | Additive point formula (not clinically validated) |
| Tool | Real Replacement |
|---|---|
GuidelineRetrieverTool | Phase I CardioCDSS RAG engine (ChromaDB + Neo4j + Cohere reranker) |
DrugInteractionTool | Lexicomp, DrFirst, or First Databank API (licensed) |
ContraindicationChecker | Same licensed API + RxNorm drug normalization layer |
RiskScoreCalculator | ACC/AHA Pooled Cohort Equations (Goff et al., JACC 2014) |
The tool interface contract (input/output schema) remains identical in both cases. Agents do not need to change.
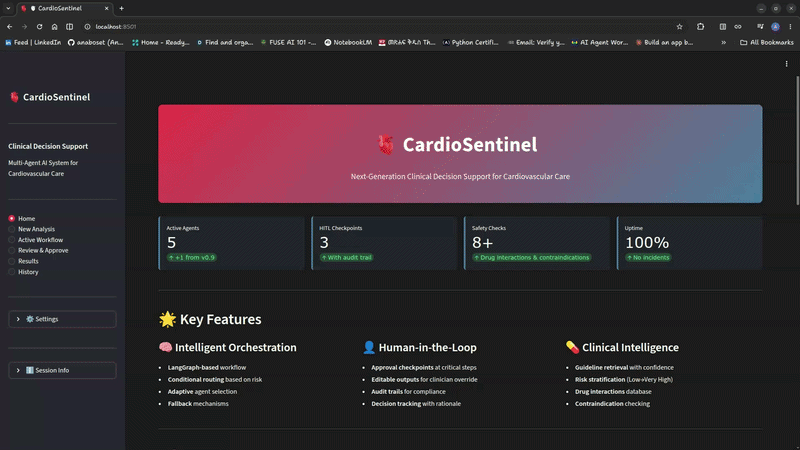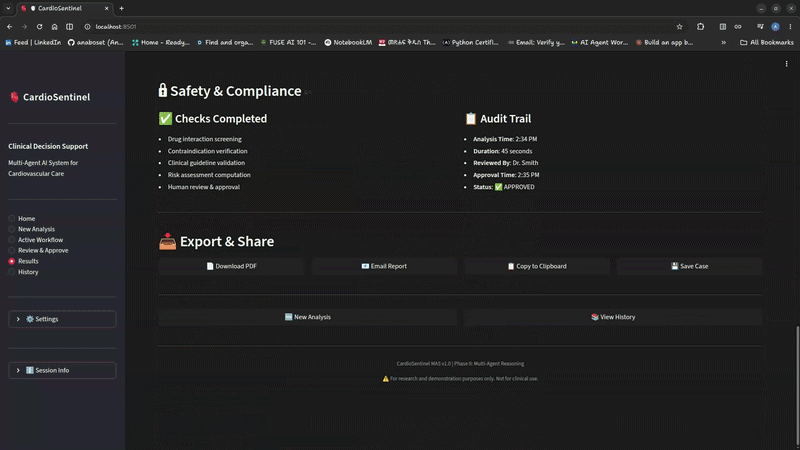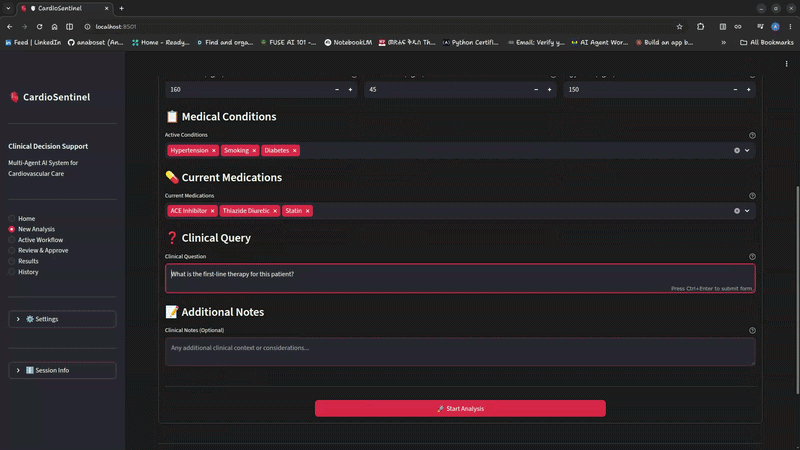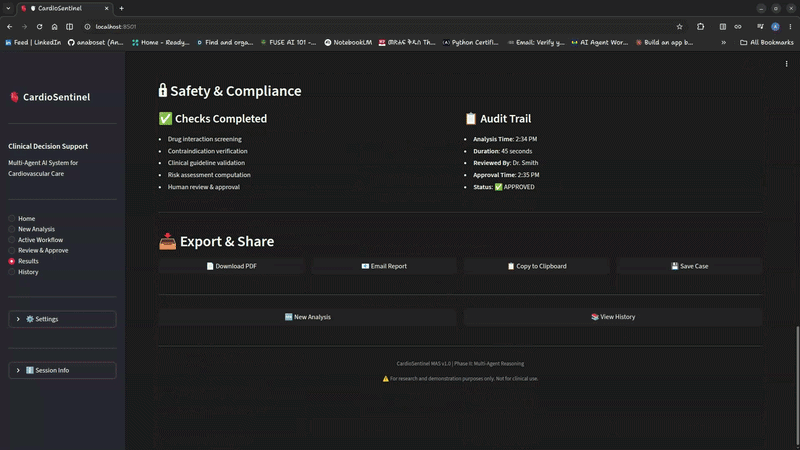
CardioSentinel MAS incorporates structured clinician approval checkpoints before clinically significant recommendations proceed downstream.

Triggered when:
Triggered when:
Triggered when:
| Decision | Action |
|---|---|
| Approve | Continue workflow execution |
| Modify | Edit intermediate state and re-run downstream agents |
| Reject | Halt workflow and return audit record |
All review decisions are recorded in an immutable audit trail with timestamps and rationale.
| Decision | Choice | Reason |
|---|---|---|
| Orchestration Framework | LangGraph | Enables conditional routing, workflow state tracking, and resumable execution |
| Human Oversight | Mandatory HITL checkpoints | Prevents unsupervised high-risk recommendations |
| Workflow State | Centralized immutable state | Ensures traceability and reproducibility |
| Failure Handling | Retry + graceful degradation | Maintains workflow continuity under partial failure |
| Auditability | Immutable audit trail | Supports explainability and reviewability |
| LLM Usage | Restricted to patient communication | Keeps clinical reasoning deterministic and tool-grounded |
cardiosentinel_mas/ │ ├── app.py ├── main_new.py ├── config.py │ ├── core/ │ ├── base.py │ ├── graph.py │ ├── node_definitions.py │ └── edge_routing.py │ ├── agents/ │ ├── guideline_agent.py │ ├── risk_agent.py │ ├── medication_agent.py │ └── patient_agent.py │ ├── tools/ │ ├── rag_tool.py │ ├── risk_tool.py │ ├── interaction_tool.py │ └── contraindication_tool.py │ ├── schemas/ │ ├── outputs.py │ └── state.py │ ├── hitl/ │ └── approval_manager.py │ ├── ui/ │ ├── app.py │ ├── components/ │ └── styles/ ├── pages/ │ ├── home.py │ ├── new_analysis.py │ ├── workflow.py │ ├── review.py │ ├── results.py │ └── history.py │ ├── tests/ │ ├── test_agents.py │ ├── test_tools.py │ ├── test_pipeline.py │ └── conftest.py │ ├── requirements.txt ├── .env.example └── .streamlit/config.toml
git clone https://github.com/anaboset/cardiosentinel-mas cd cardiosentinel-mas python -m venv venv source venv/bin/activate # Windows: venv\Scripts\activate pip install -r requirements.txt
cp .env.example .env # Set GROQ_API_KEY for PatientAgent # Set RAG_API_URL and RAG_API_KEY to connect Phase I
streamlit run app.py
pytest tests/ -v
patient = { "age": 65, "bp": "150/95", "ldl": 160, "conditions": ["hypertension", "smoker"], } query = "What is first-line therapy?"
Output:
============================================================
CLINICAL DECISION SUPPORT REPORT
============================================================
📋 QUERY: What is first-line therapy?
👤 PATIENT: Age 65, BP 150/95, LDL 160 mg/dL
Conditions: hypertension, smoker
⚠️ RISK STRATIFICATION
Classification: Very High (Score: 72/100)
• Age 65 (≥65 years)
• Stage 2 hypertension (SBP 150)
• High LDL (160 mg/dL)
• Active smoker
📚 GUIDELINE RECOMMENDATIONS (Confidence: high)
• Thiazide diuretics are recommended as first-line for uncomplicated hypertension.
• Target BP < 130/80 mmHg for high-risk patients (ACC/AHA 2023).
• Smoking cessation counseling is mandatory for all smokers.
• High-intensity statin therapy for LDL > 190 mg/dL or ASCVD risk > 20%.
Sources:
[ACC/AHA 2023 Hypertension Guidelines]
[USPSTF Tobacco Cessation Guidelines 2021]
💊 MEDICATION SAFETY: ✅ Safe to proceed
No interactions or contraindications flagged.
🤝 PATIENT COMMUNICATION
Your blood pressure and cholesterol are both elevated, which puts you at
high risk for a heart attack or stroke — but both are manageable with
medication and lifestyle changes.
Lifestyle Advice:
→ Quit smoking — this is the single highest-impact action you can take
→ Reduce salt intake to under 2g/day to help lower blood pressure
→ Walk 30 minutes daily, 5 days a week
→ Follow up in 4 weeks to check BP response to medication
Testing focused on validating both normal execution and failure handling across tools, agents, and the full workflow pipeline.
test_tools.py)Each tool was tested independently for expected outputs, edge cases, and safe handling of invalid or missing inputs.
test_agents.py)Agents were tested with mocked tools to isolate agent logic, validate structured outputs, and ensure graceful fallback behavior during failures.
test_pipeline.py)End-to-end workflow tests verified correct report generation, preservation of patient context, graceful degradation under tool/API failures, and accurate detection of unsafe clinical scenarios.
Evaluation focuses on clinically meaningful system behavior rather than chatbot-style metrics.
Assesses whether the orchestration layer triggers the correct agents and routing paths for different patient scenarios.
Measures the system’s ability to detect dangerous drug interactions and contraindications while minimizing missed safety risks.
Verifies that the system safely returns insufficient_evidence when evidence is unavailable instead of generating unsupported recommendations.
Evaluates whether workflow execution continues safely when individual tools or agents fail.
Targets end-to-end workflow execution under 5 seconds (excluding LLM calls), with minimal orchestration overhead.
Most healthcare AI systems focus on isolated capabilities such as chatbot question answering, guideline retrieval, or standalone risk prediction.
CardioSentinel MAS instead explores how these capabilities can be safely coordinated within a structured, graph-orchestrated clinical workflow under human supervision.
| Typical Healthcare AI | CardioSentinel MAS |
|---|---|
| Single general-purpose LLM | Multiple specialized agents |
| End-to-end text generation | Tool-grounded workflow pipeline |
| Implicit reasoning | Explicit graph orchestration |
| Limited oversight | Human-in-the-loop review checkpoints |
| Hallucination-prone outputs | Evidence-linked recommendations |
| Minimal failure handling | Graceful degradation architecture |
| Monolithic system design | Modular interchangeable components |
| Stateless responses | Centralized workflow state tracking |
| Safety checks optional | Mandatory medication safety layer |
| Minimal traceability | Immutable audit trail |
Several tools remain mocked. The drug interaction database, contraindication mappings, and risk scoring logic are simplified and not clinically validated.
The workflow has simulated HITL review. Although approval checkpoints exist architecturally, they are not integrated into real clinical governance systems or institutional workflows.
The Streamlit UI is a prototype interface. It demonstrates workflow interaction patterns but is not designed for production clinical deployment.
No real EHR integration exists. Patient data is still manually entered and not connected to FHIR-compliant systems.
Drug normalization is incomplete. Medication inference still relies on simplified mappings rather than production-grade RxNorm normalization pipelines.
LLM-generated patient communication remains unvalidated. Although clinician review checkpoints exist, generated summaries have not undergone formal readability or safety evaluation.
Security and compliance controls are incomplete. The system does not yet implement production-grade authentication, authorization, encryption, or regulatory compliance infrastructure.
This software is intended for research and architectural demonstration purposes only.
It is not a medical device and not intended for diagnosis, treatment, or clinical decision-making without qualified human oversight.
The tools are mocked. The drug interaction database is incomplete. The risk scoring is not clinically validated. No clinical expert was involved in the design of this system.
All clinical decisions must be made by licensed healthcare professionals. The author assumes no liability for clinical use of this system.