
Bumbiro AI: Building a Production-Grade RAG System for the Zimbabwe Constitution
BUMBIRO is a Shona word which means Constitution. Bumbiro AI is a retrieval-augmented legal intelligence system designed to answer questions about the Zimbabwe Constitution using grounded, source-backed responses. The system combines a Streamlit user interface, FastAPI backend services, ChromaDB vector retrieval, and large language model orchestration to provide explainable constitutional question answering. By separating document ingestion, retrieval, prompt construction, and response validation into modular components, Bumbiro AI improves accessibility to constitutional knowledge while reducing hallucinations commonly associated with general-purpose language models.
The primary dataset consists of official Zimbabwe Constitution documents collected from publicly available constitutional and legal reference sources, including government-published constitutional PDFs and verified civic legal repositories. Source documents were selected based on authenticity, completeness, and public accessibility to ensure reliable legal grounding.
The dataset contains constitutional text documents covering the full Zimbabwe Constitution, including chapters, sections, rights provisions, governance structures, legal procedures, and amendment clauses. During preprocessing, the documents were cleaned, normalized, split into semantically meaningful chunks, and embedded into a ChromaDB vector store for retrieval.
The Constitution is the supreme law of Zimbabwe, but for many people it remains difficult to access, navigate, and interpret efficiently.
Bumbiro was built to close that gap.
Its purpose is to make constitutional information:
This makes Bumbiro more than a simple LLM demo. It is a domain-specific AI system aimed at improving how users engage with civic and legal knowledge.
The methodology follows a production-oriented retrieval-augmented generation pipeline.
First, constitutional source documents are loaded, cleaned, chunked, and embedded into a ChromaDB vector store. At query time, a user submits a legal question through the Streamlit interface, which forwards the request to a FastAPI API layer.
The backend performs semantic retrieval over the constitutional vector database to fetch the most relevant legal sections. Retrieved context is assembled into a grounded prompt for the language model, which generates a response strictly based on the retrieved constitutional evidence.
To improve reliability, the system includes input guardrails, output validation, source formatting, and modular response processing layers. This ensures grounded reasoning, traceable constitutional sources, and explainable outputs.
Bumbiro AI is designed as a retrieval-augmented generation system focused on answering questions about the Zimbabwe Constitution in a grounded, explainable, and user-friendly way. The architecture separates the user interface, backend API, and core reasoning pipeline so that each layer has a clear responsibility and can be maintained independently.

Zimbabwe Constitution Documents
↓
Document Loading and Cleaning
↓
Chunking
↓
Embeddings
↓
Chroma Vector Store
↓
User Query
↓
Retriever
↓
Context Builder
↓
Prompt Builder
↓
LLM Generator
↓
Output Guardrails
↓
Answer + Sources
app/ingestion/pipeline.py
class IngestionPipeline: def __init__( self, loader, cleaner, chunker, vector_store ): self.loader = loader self.cleaner = cleaner self.chunker = chunker self.vector_store = vector_store def run(self): documents = self.loader.load() cleaned_docs = self.cleaner.clean(documents) chunks = self.chunker.chunk(cleaned_docs) self.vector_store.store(chunks) return len(chunks)
The ingestion pipeline modularizes document loading, cleaning, chunking, and vector storage into independently replaceable components, improving maintainability, testability, and retrieval quality in the Bumbiro AI RAG system.
git clone https://github.com/SimbaMunatsi/rag-production-system.git cd rag-production-system
python -m venv .venv
.venv\Scripts\activate
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Create a .env file in the project root:
OPENAI_API_KEY=your_api_key export LANGSMITH_API_KEY=your_langsmith_key export LANGSMITH_TRACING=true export LANGSMITH_PROJECT=rag-production-system export LANGSMITH_ENDPOINT=your_langsmith_endpoint CHROMA_DB_PATH=./data/embeddings
python -m scripts.ingest_data
uvicorn app.api.main:app --reload
Swagger UI:
http://localhost:8000/docs
streamlit run streamlit_app.py
App UI:
http://localhost:8501
You can test Bumbiro with questions such as:
Bumbiro AI integrates LangSmith-based observability to monitor and trace the full retrieval-augmented generation lifecycle.
Each user query is traced from Streamlit request submission through FastAPI orchestration, semantic retrieval, prompt construction, and final response generation. This traceability provides visibility into latency bottlenecks, retrieval misses, prompt quality, and hallucination risk.
The observability layer proved especially valuable during development when diagnosing vector store ingestion issues, empty retrieval contexts, and response inconsistencies. By instrumenting the pipeline with LangSmith, the system adopts production-grade debugging and monitoring practices common in enterprise AI applications.

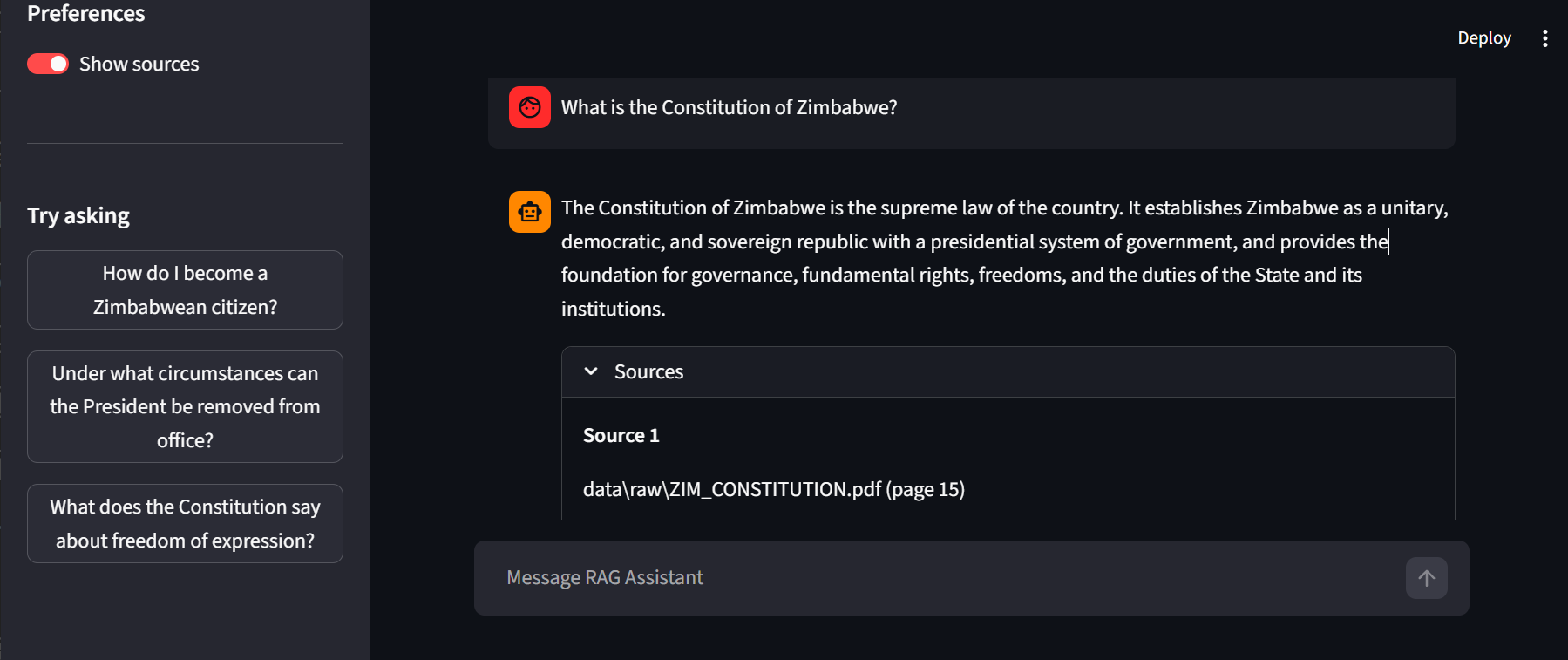
The resulting system successfully answers constitutional questions with grounded, source-backed outputs. Compared to a generic LLM baseline, Bumbiro AI provides significantly more trustworthy responses because every answer is supported by retrieved constitutional sections.
The modular architecture improved maintainability, testing, and debugging across ingestion, retrieval, and response generation stages. In practical demonstrations, the system was able to answer civic and legal questions with high contextual relevance while clearly surfacing supporting sources.
The answer is grounded in the knowledge base
Evaluation Tooling
Bumbiro uses: Pytest, RAGAS and DeepEval. The evaluation pipeline focuses on:
faithfulness , context precision , context recall, hallucination detection.
This matters because an LLM system can appear fluent while still being wrong. Bumbiro is built to measure more than UI behavior.
The current system is limited to the constitutional corpus that has been ingested into the vector database. It does not yet include statutory instruments, parliamentary acts, case law, or legal precedent databases. As a result, responses are strongest for constitutional questions and may not fully address broader legal matters outside the constitutional scope.
Additionally, retrieval quality depends on chunking strategy, embedding performance, and source document completeness. Ambiguous legal questions may still require expert human interpretation.
Bumbiro AI highlights the growing role of retrieval-augmented generation in regulated and trust-sensitive domains such as legal technology, civic-tech, compliance systems, and public sector AI. The project demonstrates how grounded LLM systems can improve accessibility to complex legal knowledge while preserving explainability, source transparency, and user trust.
Future improvements include multilingual support for local Zimbabwean languages, stronger legal citation formatting, improved retrieval evaluation benchmarks, and memory-aware multi-turn legal conversations. Further work may extend Bumbiro AI into parliamentary acts, statutory instruments, and broader civic knowledge systems across Africa.
The system is optimized for low-latency semantic retrieval and response generation on a local development environment. Core requirements include Python 3.11+, FastAPI, Streamlit, ChromaDB, embedding model dependencies, and sufficient memory for vector persistence.
Performance is primarily influenced by embedding model speed, vector store size, chunk granularity, and the response latency of the underlying language model provider.
Bumbiro AI is distributed under the MIT License. Users are permitted to use, modify, distribute, and extend the system for research, educational, and commercial prototyping purposes, subject to the terms of the repository license.
Bumbiro AI is publicly accessible through its GitHub repository, with demonstration access provided via YouTube walkthroughs and publication documentation. The current version is available for educational, research, portfolio, and civic-tech demonstration purposes.
Creator: Victor Simbarashe Munatsi
Github
LinkedIn
vsmunatsi@gmail.com