
This work provides a comprehensive implementation of Contrastive Language-Image Pretraining (CLIP) from the ground up. CLIP, introduced by OpenAI, jointly trains image and text encoders using contrastive learning to align visual and textual representations in a shared embedding space. This tutorial details the architectural design, including the use of transformer-based models for text encoding and convolutional neural networks for image encoding, as well as the application of contrastive loss for training. The resulting implementation offers a clear, reproducible methodology for understanding and constructing CLIP models, facilitating further exploration of multi-modal learning techniques.
Contrastive Language-Image Pretraining (CLIP) is a pioneering multi-modal model introduced by OpenAI that bridges the gap between visual and textual understanding. By jointly training an image encoder and a text encoder, CLIP learns to align these two modalities in a shared embedding space, enabling it to perform tasks such as zero-shot image classification, image search by textual queries, and text generation based on visual content. This alignment is achieved through contrastive learning, where the model is trained to associate corresponding image-text pairs while distinguishing them from unrelated pairs.
The key innovation of CLIP lies in its ability to generalize across a wide range of visual and textual inputs without requiring task-specific fine-tuning. This is particularly useful in open-ended scenarios where the model is expected to handle diverse, unseen data. Traditional models often require large labeled datasets and are constrained to specific tasks. In contrast, CLIP can be trained on uncurated, web-scale datasets containing image-text pairs, making it highly flexible and applicable in various domains, from content retrieval to creative generation.
The usefulness of CLIP extends beyond its impressive performance on standard vision tasks. It provides a scalable approach to multi-modal learning, where text can be leveraged to guide image understanding in more abstract ways, and vice versa. This makes it a powerful tool for applications in fields like computer vision, natural language processing, and even human-computer interaction, where cross-modal relationships are essential.
In this tutorial, the focus will be on implementing CLIP from scratch, offering insights into its architecture and training process. This implementation provides a hands-on exploration of the core principles of multi-modal contrastive learning, highlighting CLIP’s versatility and effectiveness in real-world applications.
CLIP employs a dual-encoder architecture that processes images and text separately but aligns their representations in a shared embedding space. The model consists of two key components: an image encoder and a text encoder. These encoders operate independently to produce embeddings for their respective inputs, which are then compared using a contrastive loss function to learn meaningful correspondences between images and their associated textual descriptions.
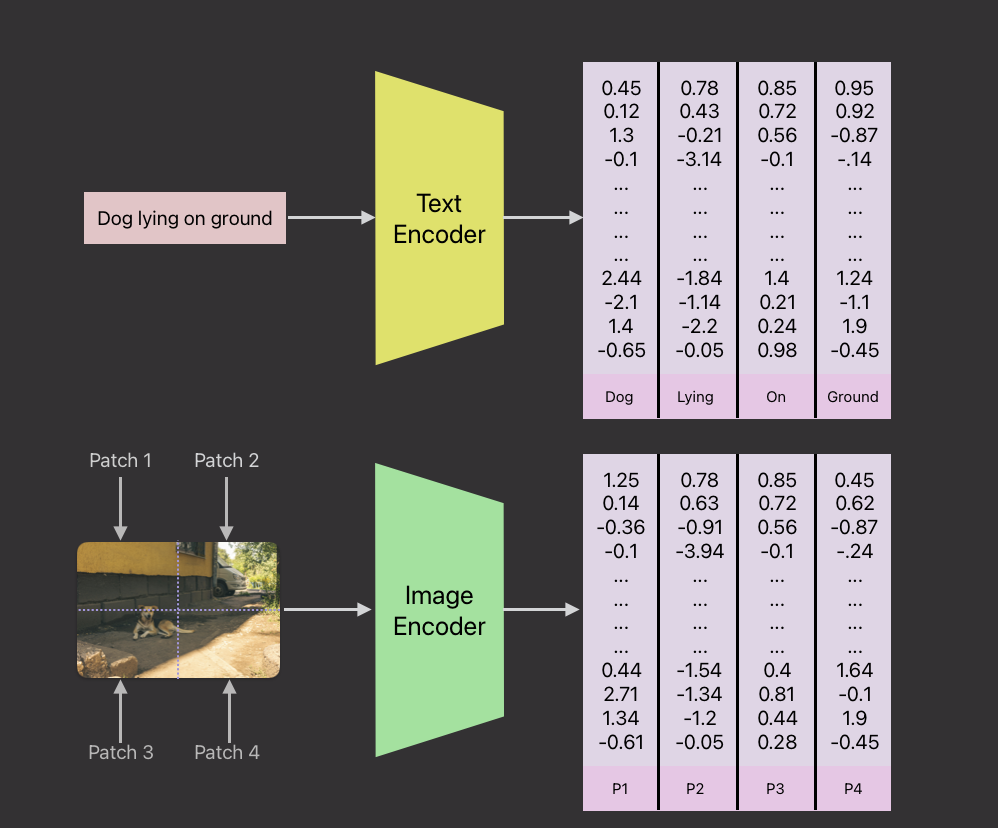
The image encoder in CLIP is responsible for converting images into high-dimensional embeddings that capture meaningful visual features. These embeddings are then aligned with text embeddings through a shared space, allowing the model to learn relationships between images and textual descriptions. The image encoder is flexible and can be built using different architectures, with ResNet and Vision Transformers (ViT) being the most commonly used.
Both of these architectures can be employed in CLIP to encode visual information effectively. The choice of image encoder depends on the complexity and scale of the task, as well as the type of image data being used. ResNet tends to work well for standard image recognition tasks, while ViT excels in capturing more abstract relationships within images.
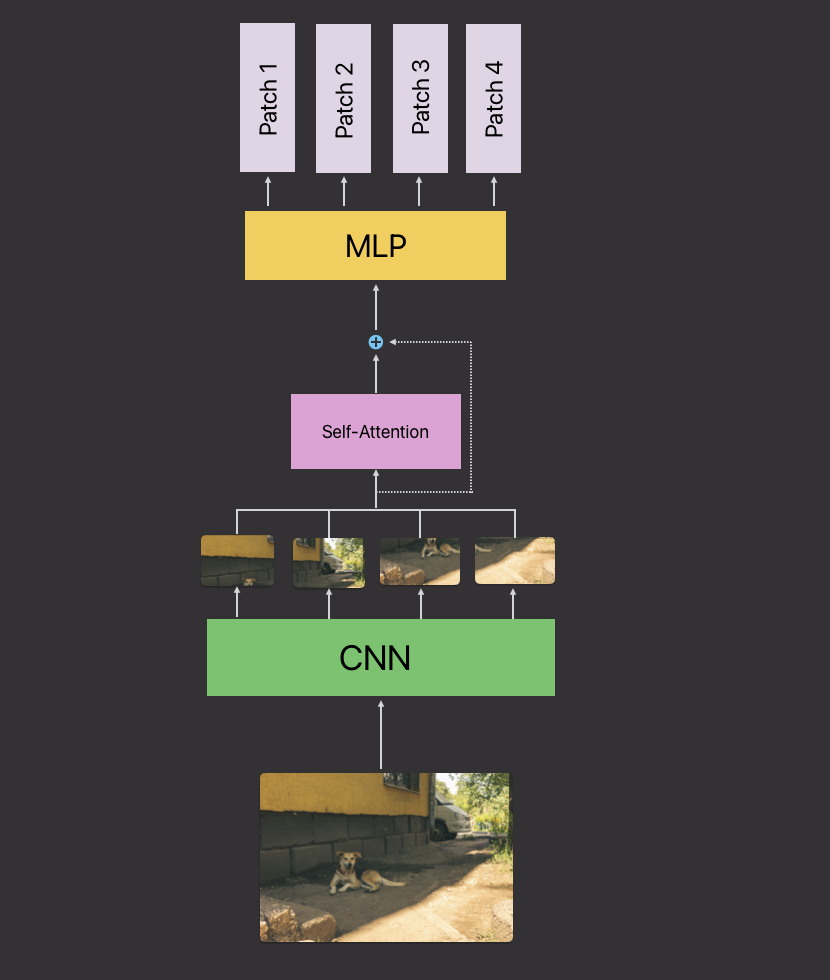
The image encoder in this implementation is inspired by the Vision Transformer (ViT) architecture, which processes images as sequences of patches, allowing it to capture relationships across different regions of an image efficiently.
Patch Embedding:
The first step in the image encoding process is to divide the input image into small, fixed-size patches (in this case, 16x16 pixels). Each patch is treated as an individual token, similar to words in a text sequence. These patches are then linearly projected into a higher-dimensional space (768 dimensions), effectively converting the image into a series of patch embeddings. This process ensures that the model can process and understand each part of the image separately.
Positional Embedding:
Since transformers are sequence models and do not inherently have any notion of spatial relationships, positional embeddings are added to each patch embedding. These positional embeddings provide information about the relative position of each patch in the original image, ensuring that the model can account for spatial arrangement while processing the image.
class ImageEmbeddings(nn.Module): def __init__( self, embed_dim: int = 768, patch_size: int = 16, image_size: int = 224, num_channels: int = 3, ): super(ImageEmbeddings, self).__init__() self.embed_dim = embed_dim self.patch_size = patch_size self.image_size = image_size self.num_channels = num_channels self.patch_embedding = nn.Conv2d( in_channels=self.num_channels, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size, padding="valid", ) self.num_patches = (self.image_size // self.patch_size) ** 2 self.position_embedding = nn.Embedding(self.num_patches, self.embed_dim) self.register_buffer( "position_ids", torch.arange(self.num_patches).expand((1, -1)), persistent=False, ) def forward(self, x: torch.Tensor) -> torch.Tensor: # x: (Batch size, Channels, Height, Width) -> (Batch size, Embed dim, Height, Width) x = self.patch_embedding(x) # x: (Batch size, Embed dim, Height, Width) -> (Batch size, Height * Width, Embed dim) x = x.flatten(2).transpose(1, 2) # Add position embeddings x = x + self.position_embedding(self.position_ids) return x
class Attention(nn.Module): def __init__( self, embed_dim: int = 768, num_heads: int = 12, qkv_bias: bool = False, attn_drop_rate: float = 0.0, proj_drop_rate: float = 0.0, ): super(Attention, self).__init__() assert ( embed_dim % num_heads == 0 ), "Embedding dimension must be divisible by number of heads" self.num_heads = num_heads head_dim = embed_dim // num_heads self.scale = head_dim**-0.5 self.wq = nn.Linear(embed_dim, embed_dim, bias=qkv_bias) self.wk = nn.Linear(embed_dim, embed_dim, bias=qkv_bias) self.wv = nn.Linear(embed_dim, embed_dim, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop_rate) self.wo = nn.Linear(embed_dim, embed_dim) self.proj_drop = nn.Dropout(proj_drop_rate) def forward(self, x: torch.Tensor) -> torch.Tensor: # x: (Batch size, Num patches, Embed dim) batch_size, n_patches, d_model = x.shape q = ( self.wq(x) .reshape(batch_size, n_patches, self.num_heads, d_model // self.num_heads) .transpose(1, 2) ) k = ( self.wk(x) .reshape(batch_size, n_patches, self.num_heads, d_model // self.num_heads) .transpose(1, 2) ) v = ( self.wv(x) .reshape(batch_size, n_patches, self.num_heads, d_model // self.num_heads) .transpose(1, 2) ) attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) x = (attn @ v).transpose(1, 2).reshape(batch_size, n_patches, d_model) x = self.wo(x) x = self.proj_drop(x) return x
class MLP(nn.Module): def __init__( self, in_features: int, hidden_features: int, drop_rate: float = 0.0, ): super(MLP, self).__init__() self.fc1 = nn.Linear(in_features, hidden_features) self.act = nn.GELU() self.fc2 = nn.Linear(hidden_features, in_features) self.drop = nn.Dropout(drop_rate) def forward(self, x: torch.Tensor) -> torch.Tensor: # x: (Batch size, Num patches, Embed dim) x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x
class ImageEncoderLayer(nn.Module): def __init__( self, embed_dim: int = 768, num_heads: int = 12, mlp_ratio: int = 4, qkv_bias: bool = False, drop_rate: float = 0.0, attn_drop_rate: float = 0.0, ): super(ImageEncoderLayer, self).__init__() self.norm1 = nn.LayerNorm(embed_dim, eps=1e-6) self.attn = Attention( embed_dim=embed_dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop_rate=attn_drop_rate, proj_drop_rate=drop_rate, ) self.norm2 = nn.LayerNorm(embed_dim) self.mlp = MLP( in_features=embed_dim, hidden_features=int(embed_dim * mlp_ratio), drop_rate=drop_rate, ) def forward(self, x: torch.Tensor) -> torch.Tensor: # x: (Batch size, Num patches, Embed dim) residual = x x = self.norm1(x) x = residual + self.attn(x) residual = x x = self.norm2(x) x = residual + self.mlp(x) return x
This architecture provides the flexibility to learn both fine-grained details and abstract patterns across images, making it effective for encoding visual information in multi-modal tasks like CLIP. The combination of patch embeddings, attention, and feed-forward networks allows the model to understand and represent images in a way that can be directly compared to text embeddings.
The text encoder in CLIP is responsible for converting input text into a fixed-dimensional embedding that can be aligned with image embeddings. CLIP can use various transformer-based models like BERT or GPT as its text encoder. These models tokenize the input text, turning each word or subword into an embedding vector that captures semantic meaning.
To handle word order, positional encodings are added to these token embeddings, ensuring the model understands the structure of the sentence. A multi-head self-attention mechanism then allows each token to attend to all others in the sequence, capturing both local and global dependencies in the text.
Finally, the output is refined through a feed-forward network, with layer normalization and residual connections applied to stabilize training and maintain information across layers. This architecture ensures the model generates high-quality embeddings that represent the meaning of the text, ready to be aligned with the corresponding image embeddings.
In this implementation, we chose GPT-2 as our text encoder:
configuration = GPT2Config( vocab_size=50257, n_positions=max_seq_length, n_embd=embed_dim, n_layer=num_layers, n_head=num_heads, ) self.text_encoder = GPT2Model(configuration)
Once the image and text inputs have been encoded separately by their respective encoders, CLIP projects both modalities into a shared embedding space. This process, known as data fusion, allows the model to align visual and textual representations so that they can be directly compared.
To achieve this, both the image and text embeddings are passed through a projection layer that maps them into the same dimensional space. By doing so, the model can compute similarities between images and text, enabling it to link corresponding image-text pairs and differentiate between unrelated ones. This shared space is crucial for tasks like zero-shot image classification and cross-modal retrieval, where the model must understand and relate visual and textual information in a unified way.
self.image_projection = nn.Linear(img_embed_dim, embed_dim) self.text_projection = nn.Linear(embed_dim, embed_dim)
CLIP’s training process relies on contrastive learning, which is designed to align image and text embeddings by maximizing the similarity between matched pairs while minimizing it for mismatched pairs. This is achieved through the use of a contrastive loss function, which encourages the model to bring together the embeddings of corresponding images and text in the shared space.
During training, the model is given a batch of image-text pairs. For each pair, the model computes similarities between the image embedding and all the text embeddings in the batch, as well as between the text embedding and all the image embeddings. The goal is to maximize the similarity for the correct image-text pair and minimize it for all incorrect pairs. This encourages the model to learn meaningful correspondences between images and descriptions, ensuring that related images and text are positioned closely in the embedding space, while unrelated pairs are pushed apart.
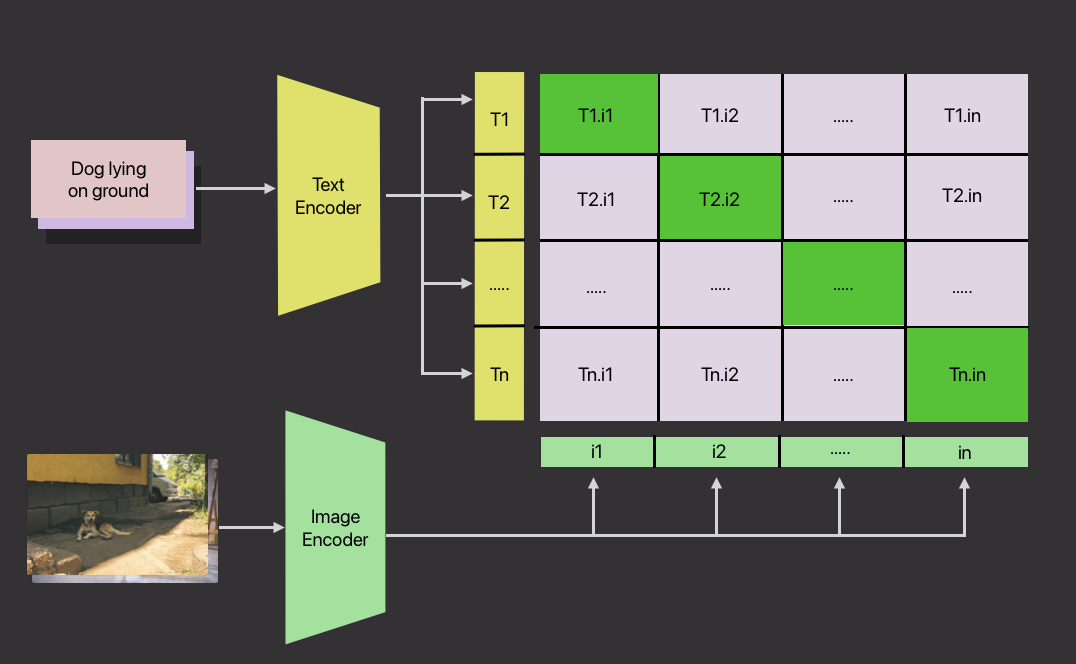
The contrastive loss can be implemented as follows:
def clip_loss(image_embeddings, text_embeddings): # Normalize embeddings image_embeddings = F.normalize(image_embeddings, dim=-1) text_embeddings = F.normalize(text_embeddings, dim=-1) # Compute logits by multiplying image and text embeddings (dot product) logits_per_image = image_embeddings @ text_embeddings.T logits_per_text = text_embeddings @ image_embeddings.T # Create targets (diagonal is positive pairs) num_samples = image_embeddings.shape[0] labels = torch.arange(num_samples, device=image_embeddings.device) # Compute cross-entropy loss for image-to-text and text-to-image directions loss_image_to_text = F.cross_entropy(logits_per_image, labels) loss_text_to_image = F.cross_entropy(logits_per_text, labels) # Final loss is the average of both directions loss = (loss_image_to_text + loss_text_to_image) / 2.0 return loss
One of the practical use cases for CLIP-like models is solving multiple-choice questions (MCQs) where the question is an image and the answer options are in text form. This setup highlights CLIP’s ability to bridge visual and textual data, aligning image features with corresponding text descriptions to select the most relevant answer.
To train the model for this type of task, we used the Attila1011/img_caption_EN_AppleFlair_Blip dataset from Hugging Face. This dataset contains pairs of images and corresponding captions, making it ideal for training models that require aligned image-text data, such as CLIP. By learning the associations between diverse visual inputs and their textual descriptions, the model can effectively map images to related text in a shared embedding space, a key component in contrastive learning frameworks.
The diverse nature of the images and captions in this dataset allows the model to generalize well across various visual scenes and their textual counterparts. This ensures that the model can capture a wide range of image-text relationships, which is critical for tasks involving open-ended or unseen data, such as solving MCQs where new image-based questions are presented.
After training on this dataset, the model was evaluated on a multiple-choice question (MCQ) dataset where it was tasked with selecting the correct text-based answer for each image. Below, we provide an example visualization, showing the images from the MCQ dataset, the model's answer choices, and its selected answer.

In this work, we provided a detailed walkthrough of implementing Contrastive Language-Image Pretraining (CLIP) from scratch, covering both the architectural design and the training process. By leveraging contrastive learning, the model effectively aligns image and text embeddings in a shared space, enabling it to generalize across various multi-modal tasks without the need for task-specific fine-tuning. We demonstrated the versatility of CLIP through its ability to handle both visual and textual information, and further evaluated its performance on a multiple-choice question (MCQ) dataset. This implementation highlights the powerful capabilities of CLIP in multi-modal learning, laying the foundation for future exploration in fields such as computer vision, natural language processing, and cross-modal retrieval.
Radford, Alec, et al. “Learning Transferable Visual Models From Natural Language Supervision.” International Conference on Machine Learning (ICML), 2021.
Attila1011/img_caption_EN_AppleFlair_Blip Dataset

