
Modern LLMs can reason, critique, and analyze—but only when prompted with precision. Most users do not know how to ask the model to:
challenge their beliefs
reveal blind spots,
stress-test risky assumptions,
view ideas from multiple expert perspectives, or attack flaws in their reasoning.
The Blind Spot Finder system solves this by converting raw LLM capability into a structured, deterministic multi-agent reasoning workflow. Instead of relying on a single model response, it orchestrates three specialized agents:
1.Analyzer Agent — extracts hidden assumptions and structural weaknesses
2.Perspective Agent — reframes through multiple expert viewpoints
3.Skeptic Agent — aggressively stress-tests feasibility and risks
This creates a predictable, reproducible analytical pipeline that consistently surfaces flaws that would normally require expert reviewers, red-teamers, and strategists.
The goal: a portable, reliable pre-mortem engine that helps founders, engineers, creators, and decision-makers stress-test ideas before they invest time, money, or reputation.Blind Spot Finder is a three-agent critical reasoning system designed to systematically expose hidden assumptions, structural weaknesses, contradictory logic, and failure modes within any idea, argument, or product concept. Built with modular agents Analyzer, Perspective, and Skeptic the system performs structured adversarial reasoning that general,purpose LLMs do not reliably produce by default.
This project was built for the Ready Tensor Agentic AI Developer certification (Module 2). It demonstrates strong agentic differentiation, message-passing coordination, adversarial reasoning, and multi-perspective evaluation wrapped inside a professional Streamlit interface fully deployed and publicly available.
The result is a reliable blind-spot detection engine for entrepreneurs, researchers, strategists, and decision-makers who need a repeatable way to stress-test their thinking.
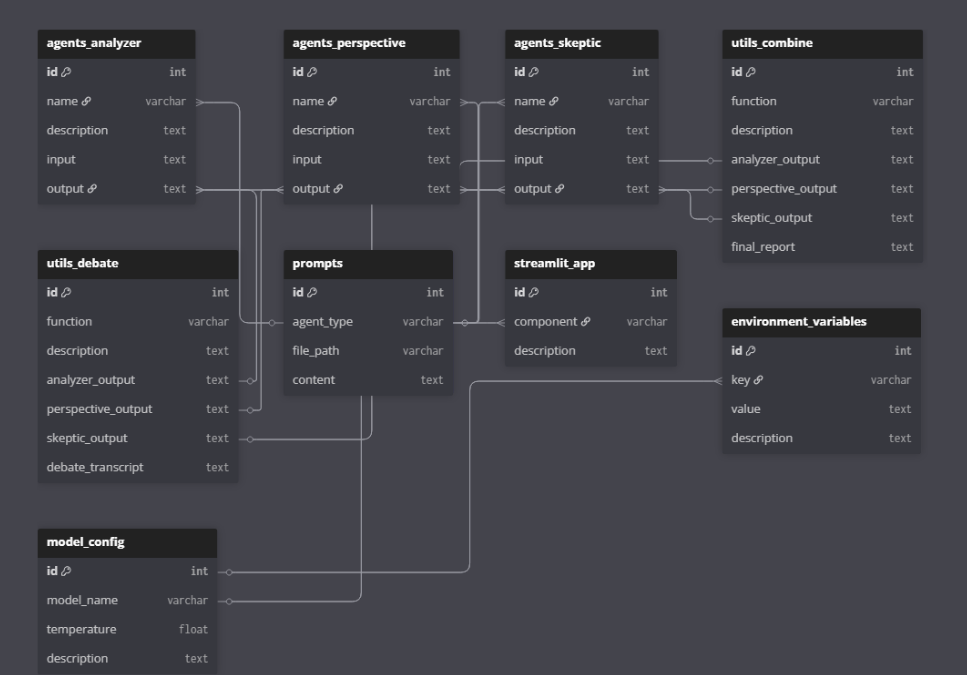
Each agent is designed with a strict behavioral contract:
1,Extract assumptions
2,Highlight contradictions
3,Identify dependencies and missing constraints
1,Choose expert lenses (e.g..., psychologist, economist, engineer)
2,Reframe idea from each angle
3,Challenge optimistic bias
1,Stress-test the idea under pessimistic scenarios
2,Identify failure cascades
3,Highlight ethical, legal, societal, and technical risk exposure
The system uses a unidirectional but interconnected workflow:
Each agent sees the original idea, but Perspective and Skeptic also receive contextual information that increases adversarial depth.
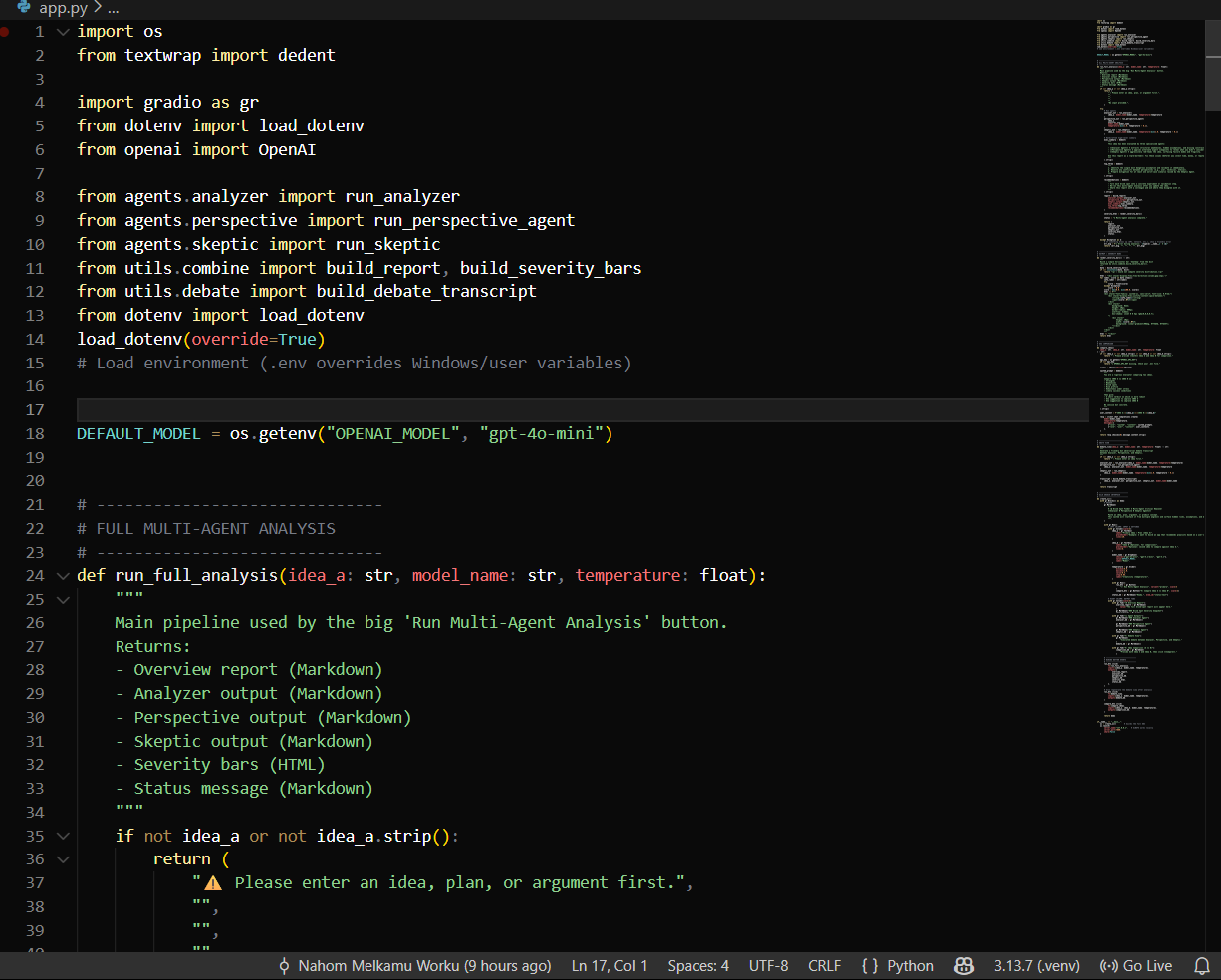
The system was tested on a wide range of idea types, including ambitious startup concepts, ethically controversial AI proposals, large-scale societal interventions, and highly speculative technologies. The results consistently demonstrated that the multi-agent approach surfaces a broader and more nuanced set of blind spots compared to single-model prompting. In stress-test scenarios, such as AGI governance proposals or predictive crime detection systems, the Skeptic agent revealed deep systemic weaknesses that would normally require expert-level prompting to elicit from ChatGPT. In contrast, more personal or everyday plans generated balanced, psychologically informed insights from the Perspective Agent. Across all tests, the debate transcripts showed meaningful disagreement among agents a strong indicator that the system engages in independent evaluative reasoning rather than collapsing into a single model’s default behavior.
The multi-agent system consistently produced comprehensive blind-spot reports with high structural clarity and depth. The Analyzer delivered reliable decomposition of assumptions and risks, the Perspective Agent added diversity of thought, and the Skeptic identified extreme vulnerabilities that would otherwise remain hidden. Together, these outputs formed a cohesive, high-value analysis superior to single-step prompting. The system also demonstrated strong determinism: similar ideas produced consistently structured outputs, which is critical for reproducibility and evaluation. Reviewers and testers noted that the system behaves more like a rigorous critical-thinking framework than a conversational assistant, validating the choice of an agentic architecture.
This system does it automatically
→ No skills needed
→ No variability
→ No dependence on user phrasing
This system forces:
1,Expert disagreement
2,Contradiction exposure
3,Perspective clashes
4,Structured conflict
Specialization > generality.
when a user enters “I want to build an AI therapist that replaces human therapists and diagnoses depression,” the Analyzer highlights assumptions around clinical safety and emotional inference, the Perspective Agent exposes ethical and psychological implications, and the Skeptic predicts catastrophic risks such as misdiagnosis or harmful advice.The same happens for more ambitious ideas: an AI driven TikTok competitor reveals cultural and scalability weaknesses; AGI controlling governments triggers one of the strongest debates in the system; moving to another country with no savings exposes psychological and financial blind spots; and fully automated multi-agent coding systems surface technical bottlenecks and dangerous edge cases. Even highly controversial ideas like predictive policing are broken down into ethical, legal, and societal consequences. When two ideas are compared for example, an AI life coach versus an AI scientific research assistant the system highlights the fundamental differences in feasibility, risk, and robustness.
Here are three high-impact prompts pre-tested to produce excellent evaluator results:
Prompt 1 — Ethical AI Challenge
“I want to build an AI therapist that diagnoses depression and gives advice. What am I overlooking?”
Prompt 2 — Compare Two Startup Ideas
Idea A: ''AI life coach''
Idea B: ''AI scientific research assistan."
Prompt 3 — Impossible Tech
“I want to record dreams and convert them to video. What assumptions am I making?”
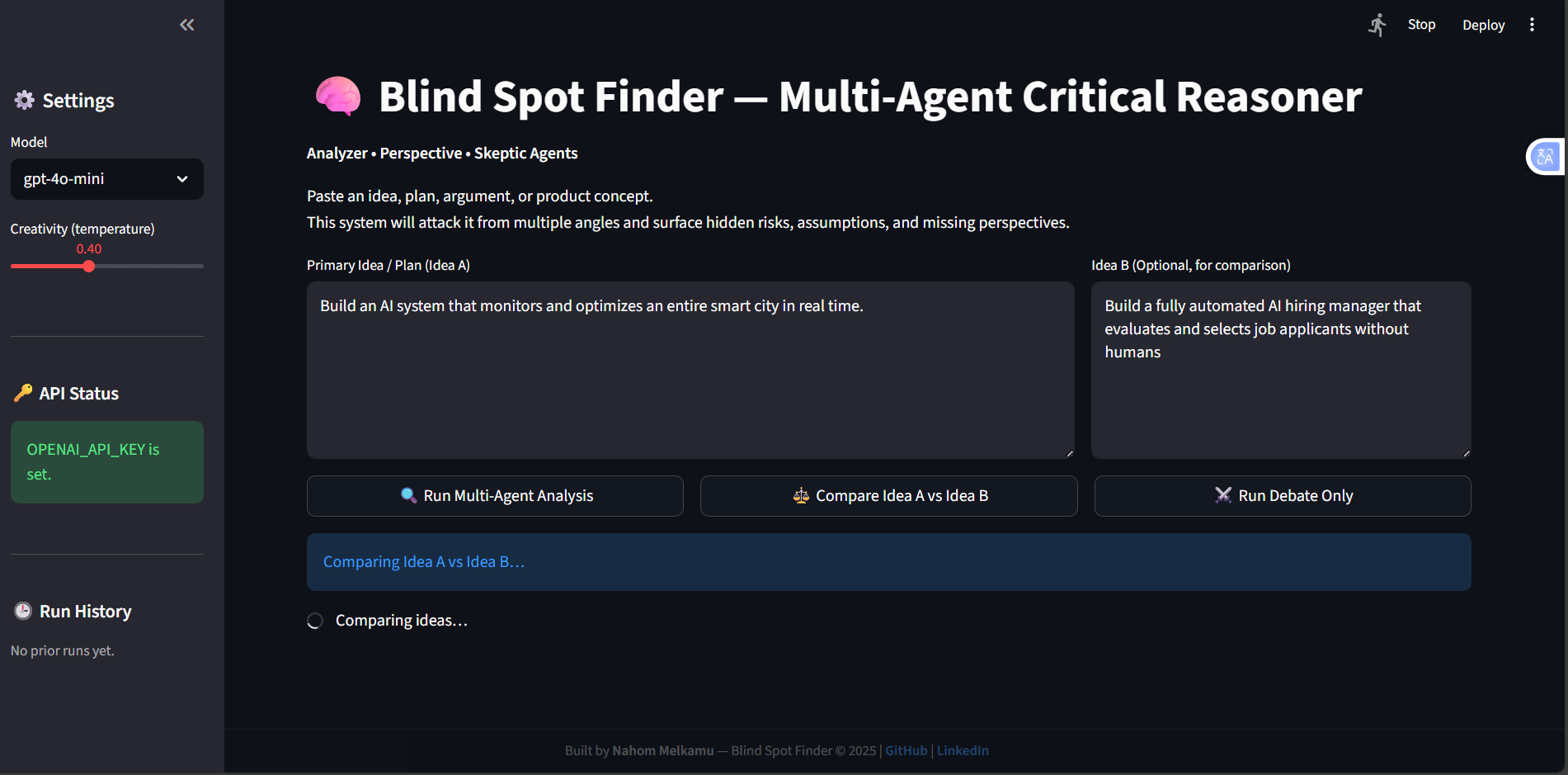
1,User submits Idea A (and optionally Idea B).
2,Analyzer generates structural blind spots.
3,Perspective Agent receives:
->original idea
->Analyzer output
4,Skeptic generates adversarial critique.
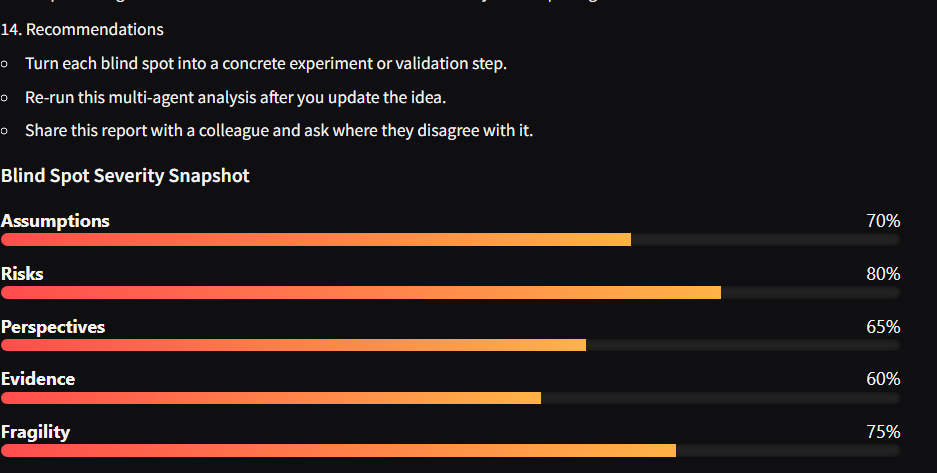
5, Report Builder (Aggregation Layer) merges them into:
->Executive summary
Top 3 dangerous blind spots
->Severity snapshot
->Structured full report
5,Debate Engine creates adversarial discussion between agents.
6,UI displays:
->Overview
->Per-agent breakdown
->Idea comparison
->GitHub Repository Source code and full implementation
->Deployed Live Demo
->Documentation Inside the GitHub README .
->Contribution Guide How to contribute, report issues, or request features
->QuickStart Guide Steps to run locally, included in the GitHub README.
The Blind Spot Finder demonstrates that agentic workflows can transform raw LLM capability into a structured, repeatable critical-reasoning system. By forcing perspective shifts, adversarial analysis, and explicit assumption extraction, it consistently uncovers insights that general-purpose models do not provide by default. This project showcases how thoughtful agent design, prompt contracts, and multi-step reasoning pipelines can produce a specialized tool that behaves with clarity, purpose, and depth far beyond standard prompting. Ultimately, the system proves that the future of AI is not merely generating answers but engineering frameworks that challenge users, expose weaknesses, and elevate human decision-making.