
One of the challenges while reading research papers is understanding complex concepts and terms used in these papers. Mostly researchers need to revisit what they have been studying in a particular research paper. Exploring each paper again and again is a tedious task and this is where AsktheScholar comes in. It is a multimodal RAG application to chat with research paper PDFs. This application leverages the benefits of retrieval augmented generation to generate context specific responses for questions related to specific research papers.
Retrieval Augmented Generation (RAG) is a technique through which a user communicates with a specialized knowledge base utilizing the power of LLMs and gets accurate and contextually relevant information. RAG augments LLM data with private or domain-specific data, enabling the generation of more accurate and relevant responses.
A retrieval augmented generation (RAG) system consists of three main components:
AsktheScholar makes the life of researchers easier by providing a platform to clear their ambiguities while reading and understanding research papers. It helps making the research process interesting and efficient. It also helps recall important aspects of a research paper through an interactive user interface.
Data ingestion is the process of loading external documents and storing them in a vector database for retrieval. These documents can be in various formats, such as PDF, DOC, TXT, HTML, and more. The ingestion process includes the following steps:
In order to test Ask the Scholar workflow, I have ingested two open-source research papers with 13 and 8 pages into the vector database making a total of 21 pages. To parse the PDFs, I have used the unstructured package which parses the PDF documents into various elements like Title, NarrativeText, Image, Table, and so on.
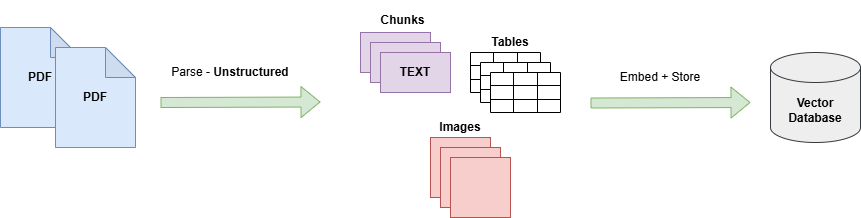
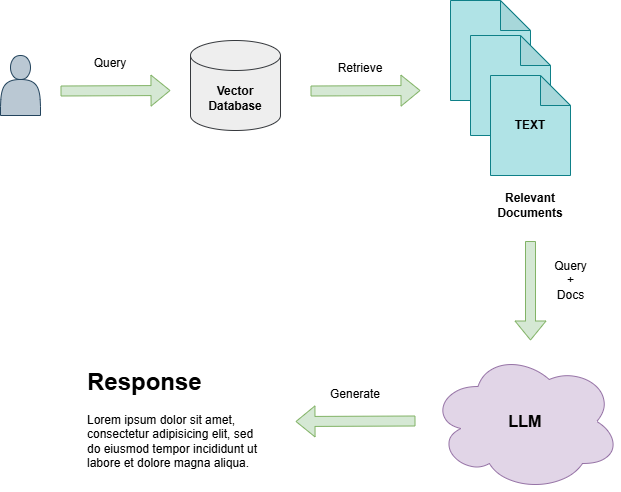
Data retrieval is the process of finding and extracting relevant information or documents from a vector store based on user prompt. A user asks questions from the specialized knowledge source to get the most relevant answers, so the vector store needs to be used programmatically for the retrieval process. It usually uses similarity search to find documents relevant to a specific query.
Synthesis is the final component of a RAG pipeline where a response is generated for the user through an LLM. The user prompt and relevant chunks retrieved from a vector database during data retrieval are passed to the LLM which then generates a context augmented response that answers the question asked by the user. The response can be structured in any required format through system prompt.
The first question is how to design this multimodal RAG application at the very beginning. Do we need to follow agentic architecture or something simpler?
Broadly - there are four levels of agentic architecture:
Level 1 - Simple LLM
Level 2 - LLMs with Tools
Level 3 - LLMs with Tools & Reasoning
Level 4 - Agent to Agent Interaction
You need to ask yourself the right questions before deciding on which level to choose. The first two levels may be considered as simple AI pipelines where the workflow is deterministic and the automation is predefined. As you move forward, levels 3 and 4 add a level of autonomy and self reflection with increasing complexity which convert these pipelines into autonomous agentic systems.
So if you have a question that the LLM may answer on its own based on its training, or may use external APIs or systems to answer domain-specific questions, you might consider staying at level 1 or 2 because your goals can be achieved through simple automated workflows. On the other hand, if you have complex queries which need planning and reflection before reaching at the final answer and may be gathering information from external resources and deciding on the go, then you must consider choosing level 3 or 4 based on the complexity of your task. Ideally for single, focused tasks, you should choose level 3 and if you have multiple diverse tasks to perform before reaching a sound conclusion, you must consider choosing level 4 with multiple vertical AI agents collaborating with each other.
In our case, Level 2 - LLM with Tools would suffice and most of the real world RAG systems fall under this level.
All installation and setup instructions are present at the Github repository mentioned in the References section.
The interface of the application looks like below:
This is the main entry point of the application for retrieval and synthesis.
import streamlit as st import requests import pandas as pd BACKEND_URL = "http://localhost:8000/ask" # FastAPI endpoint # Page Configuration st.set_page_config( page_icon="🎓", page_title="Ask the Scholar", initial_sidebar_state="auto", layout="wide") # Load external CSS with open("style.css") as f: st.markdown(f"<style>{f.read()}</style>", unsafe_allow_html=True) # Sidebar st.sidebar.header("🎓 Ask the Scholar") st.sidebar.markdown(""" **About** This is a multimodal RAG-based assistant that allows you to interact with research papers using natural language. """) st.sidebar.info(""" **Features** - Chat with research papers - Get relevant answers - Get multimodal responses - Interactive chat interface """) # Main title with an icon st.markdown( """ <div class="custom-header"'> <span>👨🏻🏫 Ask the Scholar</span><br> <span>A Multimodal RAG-based assistant to Chat with Research Papers</span> </div> """, unsafe_allow_html=True ) # Horizontal line st.markdown("<hr class='custom-hr'>", unsafe_allow_html=True) # Initialize Chat History if "chat_history" not in st.session_state: st.session_state.chat_history = [] # # Display Welcome Message # if st.session_state.welcome_message == True: # st.success(""" # **Welcome to Ask the Scholar!** # - I'll help you find answers in research papers. # - Just type your question below and I'll do my best to assist you. # """) # Chat History Display chat_container = st.container() with chat_container: for chat in st.session_state.chat_history: with st.chat_message("user", avatar="👤"): st.markdown(f"<div class='user-msg'>{chat['user']}</div>", unsafe_allow_html=True) with st.chat_message("assistant", avatar="👨🏻🏫"): # st.markdown(f"<div class='assistant-msg'>{chat['assistant']}</div>", unsafe_allow_html=True) st.markdown(chat['assistant']) # User Input user_input = st.chat_input("Ask a question...") if user_input: with st.chat_message("user", avatar="👤"): st.markdown(f"<div class='user-msg'>{user_input}</div>", unsafe_allow_html=True) with st.spinner("Retrieving information..."): try: response = requests.post(BACKEND_URL, json={"query": user_input}) response.raise_for_status() result_data = response.json() result = result_data.get("response", "") images = result_data.get("images", []) tables = result_data.get("tables", []) except Exception: result = "❌ Error: Something went wrong." images, tables = [], [] with st.chat_message("assistant", avatar="👨🏻🏫"): # st.markdown(f"<div class='assistant-msg'>{result}</div>", unsafe_allow_html=True) st.markdown(result) try: if images: st.markdown("**🔍 Relevant Images:**") for img_path in images: st.image(img_path, use_column_width=True) if tables: st.markdown("**📊 Relevant Tables:**") for table_path in tables: try: df = pd.read_csv(table_path) st.dataframe(df) except Exception as e: st.warning(f"Could not display table {table_path}: {e}") except Exception: st.error("Could not display results. Please try again.") # Update session history st.session_state.chat_history.append({ "user": user_input, "assistant": result })
This is the script for ingesting the PDF documents into the Chroma vector store after passing it through various intermediate steps like loading, parsing, chunking, and embedding.
import os from unstructured.partition.pdf import partition_pdf from langchain.schema import Document from PIL import Image import base64, io import pandas as pd from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import Chroma from transformers import AutoModel from typing import List import logging from io import StringIO from itertools import zip_longest # Configure logging def configure_logging(): # Create logs directory if it doesn't exist os.makedirs("logs", exist_ok=True) # Create a logger specifically for your ingestion pipeline ingestion_logger = logging.getLogger("ingestion") ingestion_logger.setLevel(logging.INFO) # Set desired level # Prevent logs from propagating to the root logger ingestion_logger.propagate = False # Create a file handler for this logger file_handler = logging.FileHandler("logs/ingestion.log") file_handler.setLevel(logging.INFO) # Add console output too console_handler = logging.StreamHandler() console_handler.setLevel(logging.INFO) # Define custom log format formatter = logging.Formatter( "%(asctime)s [%(levelname)s] %(message)s" ) file_handler.setFormatter(formatter) console_handler.setFormatter(formatter) # Attach the handler to your logger ingestion_logger.addHandler(file_handler) ingestion_logger.addHandler(console_handler) return ingestion_logger class JinaCLIPLangchainWrapper: def __init__(self, model, truncate_dim=512): self.model = model self.truncate_dim = truncate_dim def embed_documents(self, texts: List[str]) -> List[List[float]]: embeddings = self.model.encode_text(texts, truncate_dim=self.truncate_dim) return embeddings.tolist() # Ensure it returns a list of lists def embed_image(self, uris: List[str]) -> List[List[float]]: # images can be file paths, PIL.Image.Image, or dataURIs embeddings = self.model.encode_image(uris, truncate_dim=self.truncate_dim) return embeddings.tolist() def embed_query(self, text: str) -> List[float]: embedding = self.model.encode_text([text], truncate_dim=self.truncate_dim)[0] return embedding.tolist() # Ensure it returns a list class Ingestion: def __init__(self): self.documents = [] self.images = [] self.image_elements = [] self.tables = [] self.table_texts = [] self.captions = [] # Initialize the embedding model try: raw_model = AutoModel.from_pretrained('jinaai/jina-clip-v2', trust_remote_code=True) except Exception as e: raise Exception(f"Failed to load JinaCLIP model: {e}") self.embedding_model = JinaCLIPLangchainWrapper(raw_model) self.embeddings = [] # Initialize text embeddings self.image_embeddings = [] # Initialize image embeddings self.table_embeddings = [] # Initialize the vector store self.vector_store = Chroma( collection_name="documents", embedding_function=self.embedding_model, persist_directory="./chroma_db", # Where to save data locally ) # Configure logging self.ingestion_logger = configure_logging() def load(self, path: str, output_file: str = "document_content.txt"): """ Load and parse a PDF file into structured elements (text, tables, images). Saves extracted tables as CSV and images as image files. Populates self.documents, self.tables, self.images. """ # Parse the PDF file into structured elements (text, tables, images) using unstructured elements = partition_pdf( filename=path, strategy="hi_res", extract_images_in_pdf=True, infer_table_structure=True, skip_infer_table_types=False, extract_image_block_types=["Image"], extract_image_block_to_payload=True # Embed Base64 image in metadata ) self.ingestion_logger.info(f"[load] Loaded {len(elements)} documents from {path}") images = [el for el in elements if el.category == "Image"] self.image_elements = images # Store raw image elements for later use tables = [el for el in elements if el.category == "Table"] self.captions = [el for el in elements if el.category == "FigureCaption"] # create tables, images, and content directories if they don't exist os.makedirs("tables", exist_ok=True) os.makedirs("images", exist_ok=True) os.makedirs("content", exist_ok=True) documents = [] for i, el in enumerate(elements): if el in images: b64 = getattr(el.metadata, "image_base64", None) mime = getattr(el.metadata, "image_mime_type", None) # Decode and save the image from base64 if b64: try: img = Image.open(io.BytesIO(base64.b64decode(b64))) img.save(f"images/{i+1}.{mime.split('/')[-1]}") except Exception as e: self.ingestion_logger.warning(f"[load] Could not save image {el.element_id}: {e}") else: self.ingestion_logger.error(f"[load] ❗ No image_base64 in metadata for element {el.element_id}") elif el in tables: html = getattr(el.metadata, "text_as_html", None) if not html: self.ingestion_logger.warning(f"[load] ⚠️ Skipping element {el.element_id}: no HTML representation.") continue try: df = pd.read_html(StringIO(html))[0] df.to_csv(f"tables/Table_{i+1}.csv", index=False) except ValueError as e: self.ingestion_logger.error(f"[load] ❌ Failed to parse HTML for {el.element_id}: {e}") # Add the table to documents content = getattr(el, "text", "") metadata = el.metadata.to_dict() if hasattr(el, "metadata") else {} metadata["category"] = el.category documents.append(Document(page_content=content, metadata=metadata)) else: content = getattr(el, "text", "") metadata = el.metadata.to_dict() if hasattr(el, "metadata") else {} metadata["category"] = el.category documents.append(Document(page_content=content, metadata=metadata)) # initialize self.images as a list of image file paths stored in images folder pdf_images = [ f"images/{img}" for img in os.listdir("images") if img.endswith(('.png', '.jpg', '.jpeg', '.gif')) ] self.images.extend(pdf_images) # Store image file paths for later use # initialize self.tables as a list of table file paths stored in tables folder pdf_tables = [ f"tables/{tbl}" for tbl in os.listdir("tables") if tbl.endswith(".csv") ] self.tables.extend(pdf_tables) # Store table file paths for later use table_texts = [] for table_path in self.tables: try: df = pd.read_csv(table_path) table_texts.append(df.to_string(index=False)) except Exception as e: self.ingestion_logger.error(f"[load] ⚠️ Failed to load table {table_path}: {e}") self.table_texts.extend(table_texts) # Store table texts for later use pdf_basename = os.path.basename(path) # e.g., "File_1.pdf" pdf_name = os.path.splitext(pdf_basename)[0] # now just the name without extension file_path = os.path.join("content", pdf_name + "_" + output_file) self.ingestion_logger.info(f"[load] Saving content to {file_path}") with open(file_path, "w", encoding="utf-8") as f: f.write(f"[load] Loaded {len(documents)} documents from {path}\n\n") for doc in documents: f.write("Metadata:\n" + doc.metadata.__str__() + "\n") f.write("Content:\n" + doc.page_content + "\n") f.write("\n" + "="*80 + "\n\n") self.documents.extend(documents) # Add all documents to the main list def load_dir(self, directory: str): for filename in os.listdir(directory): if filename.endswith(".pdf"): path = os.path.join(directory, filename) self.load(path) def chunk(self, chunk_size=1000, chunk_overlap=200): splitter = RecursiveCharacterTextSplitter( separators=["\n\n", "\n", " ", ""], chunk_size=chunk_size, chunk_overlap=chunk_overlap, length_function=len, is_separator_regex=False ) simplified_docs = [] for doc in self.documents: metadata = doc.metadata # Select only simple, relevant fields simple_metadata = { k: metadata[k] for k in ["filetype", "page_number", "file_directory", "filename", "category"] if k in metadata } chunks = splitter.create_documents( texts=[doc.page_content], metadatas=[simple_metadata] # Now included safely ) simplified_docs.extend(chunks) self.documents = simplified_docs self.ingestion_logger.info(f"[chunk] Split all documents into {len(self.documents)} chunks") def embed(self): # Encode text and images self.ingestion_logger.info("[embed] Generating embeddings for documents...") texts = [doc.page_content for doc in self.documents] text_embeddings = self.embedding_model.embed_documents(texts) self.ingestion_logger.info("[embed] Generating embeddings for images...") image_embeddings = self.embedding_model.embed_images(self.images) self.ingestion_logger.info("[embed] Generating embeddings for tables...") table_embeddings = self.embedding_model.embed_documents(self.table_texts) self.table_embeddings = table_embeddings self.embeddings = text_embeddings # Store text embeddings self.image_embeddings = image_embeddings # Store image embeddings self.table_embeddings = table_embeddings # Store table embeddings self.ingestion_logger.info(f"[embed] Generated {len(text_embeddings)} text embeddings") self.ingestion_logger.info(f"[embed] Generated {len(image_embeddings)} image embeddings") self.ingestion_logger.info(f"[embed] Generated {len(table_embeddings)} table embeddings") def store(self): docs = self.documents self.ingestion_logger.info(f"[store] Storing {len(docs)} chunks with embeddings into Chroma") # Insert documents into Chroma vector store self.vector_store.add_documents( documents=docs ) self.ingestion_logger.info(f"[store] Stored {len(docs)} vectors into Chroma vector store") if len(self.images) > 0: self.ingestion_logger.info(f"[store] Storing {len(self.images)} images into Chroma") captions = [] for img in self.image_elements: # Find closest caption (e.g., same page & element before it) caption_text = next( (cap.text for cap in self.captions if cap.metadata.page_number == img.metadata.page_number), "" ) captions.append(caption_text) pairs = zip_longest(self.images, captions, fillvalue="") image_metadatas = [] image_ids = [] for i, (img_path, caption) in enumerate(pairs): if img_path is None: continue # No image to store md = { "category": "Image", "source": img_path, "image_index": i, "caption": caption } image_metadatas.append(md) image_ids.append(f"img_{i}") self.vector_store.add_images( uris=[md["source"] for md in image_metadatas], metadatas=image_metadatas, ids=image_ids ) def main(): ing = Ingestion() ing.load_dir("../../data") ing.chunk(chunk_size=1000, chunk_overlap=200) # ing.embed() ing.store() if __name__ == "__main__": main()
This is the retriever pipeline which uses similarity search to retrieve relevant documents from the vector store based on user query.
from langchain_community.vectorstores import Chroma from ingest import JinaCLIPLangchainWrapper from transformers import AutoModel from logger import logger from dotenv import load_dotenv load_dotenv() class Retrieval: def __init__(self, persist_directory="./chroma_db"): raw_model = AutoModel.from_pretrained("jinaai/jina-clip-v2", trust_remote_code=True) self.embedding_model = JinaCLIPLangchainWrapper(raw_model) self.vector_store = Chroma( collection_name="documents", embedding_function=self.embedding_model, persist_directory=persist_directory ) def retrieve(self, query: str, k: int = 5): """Retrieve relevant documents based on the query.""" logger.info(f"[Retrieve] Retrieving documents for query: {query}") results = self.vector_store.similarity_search(query, k=k) if not results: logger.warning("[Retrieve] No relevant documents found.") return results def get_vector_store(self): return self.vector_store
This is the synthesis pipeline which generates response through LLM by sending it the user query and retrieved documents. It also handles the conversational chain using LangChain.
from langchain_groq import ChatGroq from langchain.chains import ConversationalRetrievalChain from langchain.memory import ConversationBufferMemory from langchain_core.prompts import PromptTemplate from retrieve import Retrieval from logger import logger import os from utils import load_yaml_config from prompt_builder import build_prompt_from_config from paths import APP_CONFIG_FPATH, PROMPT_CONFIG_FPATH class Synthesis: def __init__(self, groq_api_key: str): # Load application configurations app_config = load_yaml_config(APP_CONFIG_FPATH) llm = app_config["llm"] self.llm = ChatGroq(api_key=groq_api_key, model_name=llm) self.memory = ConversationBufferMemory( memory_key="chat_history", return_messages=True ) # These are initialized later self.chain = None self.retriever = None self.retrieved_docs = [] def configure_prompt_settings(self, relevant_docs: list, retrieval: Retrieval): # Load prompt configurations prompt_config = load_yaml_config(PROMPT_CONFIG_FPATH) rag_assistant_prompt = prompt_config["rag_assistant_prompt"] self.retriever = retrieval.get_vector_store().as_retriever() self.retrieved_docs = relevant_docs # Custom system prompt configured_prompt = build_prompt_from_config( config=rag_assistant_prompt, input_data=relevant_docs if relevant_docs else "", ) # Remove '{' and '}' from configured prompt - required for LangChain to not confuse it with input variables configured_prompt = configured_prompt.replace("{", "").replace("}", "") base_template = """ Instructions: {instructions} Context: {context} Chat History: {chat_history} Question: {question} Answer: """ prompt_template = PromptTemplate( template=base_template, input_variables=["context", "chat_history", "question", "instructions"] ) custom_prompt = prompt_template.partial(instructions=configured_prompt) # Log the custom prompt for debugging logger.info(f"[Synthesis] Custom prompt: {custom_prompt}") self.chain = ConversationalRetrievalChain.from_llm( llm=self.llm, retriever=self.retriever, memory=self.memory, combine_docs_chain_kwargs={"prompt": custom_prompt}, verbose=True ) def get_llm_response(self, query: str) -> tuple[str, list[str], list[str]]: """Get the LLM response for a given query.""" logger.info(f"[Synthesis] Getting LLM response for query: {query}") result = self.chain.invoke({"question": query}) answer = result["answer"] image_paths = [] table_paths = [] for doc in self.retrieved_docs: metadata = doc.metadata if metadata.get("category") == "Image": image_paths.append(f"/images/{os.path.basename(metadata['filename'])}") elif metadata.get("category") == "Table": filename = metadata.get("filename") if filename: table_paths.append(f"/tables/{filename}") return answer, image_paths, table_paths
Here is a demonstration of using AsktheScholar by asking questions from previously ingested research papers.
Three main challenges I faced while developing this application were:
I have tried to solve the first challenge to some extent. The images and tables are being stored into the vector store along with their metadata but their retrieval is still a challenge.
The main cause of the latency issue was due to initialization of retriever and synthesizer classes along with every user request. By globally initializing these classes once in the main application resolved this issue.
The application did not remember previous chat context despite initializing ConversationBufferMemory. The issue was resolved by initializing the chat memory once in the beginning and not with every synthesis request.
Developing this project has solidified my foundation in implementing RAG-based applications.
Retrieval augmented generation is the most widely used technique in Agentic AI applications. It augments latest and domain specific information to LLMs and utilizes their powerful capabilities to generate relevant, coherent, and useful responses. LangChain provides robust tools for building RAG applications. Many industry applications, especially customized chatbots, are built using RAG. AsktheScholar is a practical application of RAG helping resaerchers in any field question and understand research papers in an interesting and efficient manner.