Introduction
The world of artificial intelligence (AI) is rapidly evolving and one of the most used techniques in AI, specifically natural language processing (NLP), nowadays is Retrieval Augmented Generation (RAG). The word retrieve means to get some information from a data source, augment means to expand or increase something, and generate means to create something new. Retrieval Augmented Generation (RAG) is a technique through which a user communicates with a specialized knowledge base utilizing the power of LLMs and gets accurate and contextually relevant information. RAG augments LLM data with private or domain-specific data, enabling the generation of more accurate and relevant responses. There are three main components of a RAG system - data ingestion, retrieval, and synthesis. In this article, we'll discuss the importance and components of a RAG system in detail and use that knowledge to build an end to end RAG application for a real-world use case - resume analysis - utilizing the powerful capabilities of large language models (LLMs) and LangChain — a Python framework to build robust RAG applications.
Importance of RAG
In the age of information, thousands of resources are available on any given topic. Large language models have made our lives much easier in terms of information retrieval as they have been pre-trained on billions of parameters. We can ask LLMs any question, and they provide relevant information structured in the required format.
One major issue with LLMs is hallucination, where they fabricate answers to questions they don’t know, often presenting these fabrications as factual without indicating their uncertainty. This becomes a big question mark on the authenticity of the information being retrieved. Secondly, LLMs are pretrained on very large datasets and this training takes a lot of time, so they don’t have access to latest or real-time information. While some LLMs provide real-time information, the retrieved content can be inaccurate and filled with irrelevant details. Moreover, the responses aren’t verified as they lack access to domain-specific knowledge or personal data. LLMs are powerful in understanding the context of user queries, but they require new data to be attached to them that they don’t already have access to.
One way to solve these problems is to fine tune a particular LLM on our specific data but this process has a huge training cost associated with it. The other way is to use retrieval augmented generation (RAG) in which relevant information from our knowledge base is retrieved based on our query and then sent to an LLM to analyze and generate a response. Using RAG utilizes the capabilities of LLMs to craft a context augmented response for us. We attach external data to an LLM which then gives answers to our queries from that data. This approach gives us more control, allowing us to restrict the LLM to generate answers solely from our own data rather than from its pre-trained information.
High Level Components of RAG
RAG is a combination of retrieval-based and generation-based methods. It first retrieves relevant documents from a knowledge base and then uses that information to generate a response. Following are the high level components of RAG:
- Prompt
- Data Source | Knowledge Base
- Retriever
- Generator | LLM
- Response

Basic RAG Workflow
Here's an overview of a basic RAG workflow:
- Data is ingested into the system.
- The user sends a prompt to the system.
- The retriever identifies and retrieves relevant documents according to the prompt.
- LLM generates accurate and relevant response using the prompt and retrieved information.

Advantages of RAG
- Customized Information — RAG enables access to the latest and domain specific information in a well-structured format.
- Accurate and Relevant Information — RAG ensures that the retrieved information is accurate, relevant, and useful.
- Context-Augmented Information — RAG generates meaningful responses based on the prompt and retrieved information.
Applications of RAG
Every individual has a unique knowledge source from which they may need to extract relevant information at different times. For a student, it’s the syllabus and curriculum. For a doctor, it’s patient medical histories. For a lawyer, it’s case records and related information. For a bank manager, it could be the bank’s policies. The strength of RAG lies in its ability to take a user’s natural language query and return precise, relevant information from a knowledge source — presented in a way that is easily understood by even non-technical users. Additionally, RAG systems support multilingual environments, offering customized responses in the user’s language. They can also be multimodal, integrating images, speech, and videos alongside text to provide comprehensive answers.
There are numerous applications of RAG already being used in the industry. Chatbots and AI assistants are few of them. Here is a list of some real-world applications which can be built using RAG:
- Customer support chatbots
- Conversational agents | Virtual assistants
- Document summarizers
- Personalized recommendation systems
- Educational tools | AI Tutors
- Legal Advisors
- Medical Diagnosis Assistants
Implementation of RAG using LangChain
LangChain is a widely used Python framework that helps build state-of-the-art LLM applications. It facilitates the implementation of robust RAG systems by providing reusable components. This makes it easy to integrate and customize different RAG components according to application needs. LangChain documentation provides an extensive explanation of each RAG component in detail. It has built-in tools for document transformation, connection to various data sources, and chaining multiple operations.
RAG Pipeline
- Ingestion — Process and attach an external data source to the system.
- Retrieval — Correctly retrieve the information related to the prompt entered by a user.
- Synthesis — Process the retrieved response, refine it, and present it in a readable format.

Data Ingestion
Data ingestion is the process of loading external documents and storing them in a vector database for retrieval. These documents can be in various formats, such as PDF, DOC, TXT, HTML, and more. The ingestion process includes the following steps:
- Load — Loading the data into documents
- Split — Splitting the data into smaller, manageable chunks
- Embed — Creating document embeddings
- Store — Storing the embeddings in a vector database

RAG systems are extremely beneficial because they enhance the capabilities of LLMs by providing real-time and factual information to the user in natural language utilizing the powerful capabilities of pre-trained LLMs. A reliable external data source is vital for the success of a RAG based system, making data ingestion the first step in building these systems. Data is ingested through an external data source into a RAG system to make it available for smart and efficient retrieval and synthesis. A robust RAG system depends on a well-constructed ingestion pipeline, as it retrieves responses based on the context of the external data. The higher the quality of the ingestion process, the more accurate the results.
Let's look at each of the data ingestion steps in detail.
1. Data Loading
Data loading involves extracting data from a source and converting it into a suitable format for use in a RAG application.
Loaders
LangChain offers a comprehensive set of loaders that facilitate data ingestion and preprocessing from various sources, converting it into documents for further processing. Data is loaded into a Document object, which consists of the text content and its associated metadata.
- Loaders can handle multiple sources, including text files, PDFs, word documents, web pages, and more.
- They also perform essential preprocessing tasks such as tokenization, normalization, and format conversion, ensuring the data is ready for LLMs.
- Loaders are customizable to manage specific data formats and seamlessly integrate with other LangChain components.
Examples: Data Loading using LangChain
- Load a TEXT document (.txt)
from langchain_community.document_loaders import TextLoader file_path = "data/my_document.txt" # Path of the document to be loaded loader = TextLoader(file_path) # Initialize the text loader documents = loader.load() # Load the text document
- Load a PDF document (.pdf)
from langchain_community.document_loaders import PyPDFLoader file_path = "data/my_document.pdf" # Path of the document to be loaded loader = PyPDFLoader(file_path) # Initialize the pdf loader documents = loader.load() # Load the pdf document
- Load a WORD document (.docx)
from langchain_community.document_loaders import Docx2txtLoader file_path = "data/my_document.docx" # Path of the document to be loaded loader = Docx2txtLoader(file_path) # Initialize the word document loader documents = loader.load() # Load the word document
- Load a WEB page (.html)
from langchain_community.document_loaders import WebBaseLoader web_path = "https://www.example.com" # Path of the web page to be loaded loader = WebBaseLoader(web_path) # Initialize the web page loader documents = loader.load() # Load the web page
The choice of a loader depends on the nature of the data, as each loader has unique characteristics, and returns information differently. It’s essential to explore various loaders to understand their offerings and determine how to best utilize them when building AI products with RAG.
Metadata — Importance and Usage
Metadata essentially refers to data about data. When loaders extract content, they also provide metadata such as the data source or page numbers, which can be highly useful. For instance, if you’re building an application where users need to retrieve information along with its source or page location, metadata offers all the necessary details, simplifying information verification. These features can significantly enhance your application, and the metadata can even be edited to introduce additional value-added features.
2. Data Splitting/Chunking
When performing preprocessing for RAG, it’s crucial to consider the nature of the data, the type of RAG system being built, and its limitations. After loading documents, we’ll often need to transform them to fit our application’s requirements. For example, if we have a book with more than 1000 pages, we cannot pass the entire content to an LLM due to its limited context window. This is where chunking or splitting the data into smaller, manageable parts becomes essential.
There are three key reasons for splitting data:
- Manageability: Breaking the data into smaller parts ensures it fits within the LLM’s context window, making it easier to handle.
- Embedding model compatibility: Embedding models have limits on the amount of data they can process at a time, so chunking ensures that the data aligns with the model’s capacity.
- Efficient retrieval: When a user sends a query, they only need specific information, which is often found in smaller chunks. By retrieving only relevant chunks, we avoid processing the entire corpus for a single query.
Chunking can be done at different levels — sentences, paragraphs, or chapters — depending on the problem and type of data. Think of an LLM like a young child learning to read. When teaching children how to read, we first break words into characters and then combine them to form words. Similarly, we break the text into smaller chunks to enhance the LLM’s understanding and response generation.
Splitters
LangChain provides a variety of built-in document transformers that simplify tasks like splitting, combining, filtering, and manipulating documents. Splitters are tools used to divide large text documents into smaller, semantically meaningful chunks. These chunks can then be processed individually for various NLP tasks, ensuring they stay within the size constraints of the model.
With an unlimited number of users, each sending prompts differently, the system must semantically relate the information in the text to provide accurate responses. Text splitters can be customized based on how the text is divided and the chunk size, helping ensure relevant answers while minimizing computation cost. This is important because the more data we send to an LLM, the higher will be the computation cost.
Splitters maintain the context and integrity of the text, making it easier to manage and analyze. During splitting, the chunk size must be carefully decided. For instance, if a page contains three interrelated paragraphs, dividing them into separate chunks would break the context. To address this, we use overlapping, where each chunk includes information from both the previous and next chunks, preserving context. However, if each paragraph introduces distinct topics, minimal or no overlapping may be needed, and the system will still generate a high-quality response.
Determining the maximum chunk size depends on the limitations of the model to which the chunks will be passed, particularly the embedding model in use. Each embedding model, available on platforms like Hugging Face, has specific input and output token limits. It is crucial to consider these limits when deciding on chunk size to ensure that no valuable information is lost.
Types of Splitters
Here are some of the text splitters used for different purposes:
- Recursive Splitter: This widely-used splitter adopts a hierarchical approach, initially splitting text at larger, natural breakpoints (e.g., paragraphs). It recursively processes chunks to fit size constraints while preserving context as much as possible.
- HTML Splitter: Designed for HTML content, this splitter divides text based on HTML tags and structure. It is ideal for processing web pages and HTML documents, maintaining the integrity of HTML elements.
- Markdown Splitter: This splitter handles markdown-formatted text by splitting based on markdown syntax, such as headers and lists. It is useful for processing markdown documents and notes while preserving the structure of markdown elements.
- Code Splitter: Tailored for source code, this splitter divides text based on code structures like functions and classes. It maintains logical integrity, making it suitable for processing and analyzing code snippets in various programming languages.
- Token Splitter: This splitter segments text based on token count, ensuring each chunk contains a specified number of tokens. It is useful for models with token-based input limits and can handle various tokenization schemes, including subword, character, and word tokenization.
- Character Splitter: Splitting text based on character count, this splitter offers a straightforward approach when character-based limits are crucial. It can be combined with other splitters for finer control.
- Semantic Chunker: An experimental feature of LangChain, the semantic chunker creates chunks based on semantic similarity. It generates document embeddings, compares them, and combines similar embeddings into chunks. It uses thresholds like percentile and standard deviation to determine similarity and does not require specifying chunk size. This splitter first divides text into sentences and then combines those with similar semantic meaning, preserving the context and meaning of each chunk.
Examples: Data Splitting using LangChain
- CharacterTextSplitter
from langchain_text_splitters import CharacterTextSplitter # Initialize the character text splitter text_splitter = CharacterTextSplitter( separator="", chunk_size=100, chunk_overlap=20 ) # Split the documents into chunks chunks = [] for doc in documents: texts = text_splitter.split_text(doc.page_content) chunks.extend(texts)
- RecursiveCharacterTextSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitter # Initialize the recursive character text splitter text_splitter = RecursiveCharacterTextSplitter( separators="", chunk_size=100, chunk_overlap=20 ) # Split the documents into chunks chunks = [] for doc in documents: texts = text_splitter.split_text(doc.page_content) chunks.extend(texts)
- Semantic Chunker
from langchain_experimental.text_splitter import SemanticChunker from langchain_huggingface import HuggingFaceEmbeddings # Use a smaller, faster HuggingFace model for embeddings embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") # Initialize the semantic chunker text_splitter = SemanticChunker(embeddings, breakpoint_threshold_type='percentile') # Split the documents into chunks chunks = [] for doc in documents: texts = text_splitter.split_text(doc.page_content) chunks.extend(texts)
3. Embeddings
All artificial intelligence is fundamentally mathematics. Machines don’t understand text; they process numbers. To bridge this gap, we must convert textual data into numerical form, a process known as vector embeddings. These embeddings are stored in a vector store or vector database for efficient retrieval.
Embeddings are dense vector representations that capture the semantic meaning of words, phrases, or sentences. Words with similar meanings have closer numerical representations, while words with different meanings have more distinct vectors. Importantly, embeddings aren’t single numbers but multi-dimensional vectors, representing the nuanced relationships between words. LLMs learn these representations, making words with smaller mathematical differences more semantically related.
Embeddings are calculated using embedding models, which are typically built from the encoder part of a transformer model. While large language models (LLMs) are developed from the decoder part, the encoder is responsible for learning meaningful representations of data, and the decoder generates new content based on these learned representations.
In machine learning, embeddings are widely used for tasks like classification, where words with similar embeddings can be grouped into one class. They are also applied in anomaly detection, identifying outliers with vastly different embeddings, and in clustering, where related items are grouped based on their vector similarities.
We can choose between open-source embedding models from Hugging Face or paid models from OpenAI. While OpenAI’s models come with usage fees, infrastructure cost of using open-source models is our own responsibility. Some models may require GPUs, so selecting the right model depends on our system’s requirements and budget.
Examples: Embeddings using LangChain
- HuggingFace Embeddings
from langchain_huggingface.embeddings import HuggingFaceEmbeddings # Initialize the Hugging Face embedding model embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2") # Create embeddings of text chunks for i, chunk in enumerate(chunks): print("Text chunk ", i) print("--------------") print(chunk, "\n") query_result = embeddings.embed_query(chunk) print("Embeddings", "\n", query_result, "\n\n")
4. Data Storage — Vector Stores
A vector is a mathematical representation used to store data in a computer, a concept known as representation learning. To store these representations efficiently, vector stores are employed. They are highly optimized databases designed for storing and querying high-dimensional vector data, making them essential in AI, especially in applications like recommendation systems and retrieval-augmented generation (RAG).
Vector embeddings are stored in specialized databases known as vector stores, which differ significantly from traditional or relational databases. In traditional databases, data is organized in rows and columns, similar to an Excel sheet. However, storing unstructured data like images, speech, or text in this format is inefficient, making vector stores a better choice.
Let’s explore the difference with an example. Exact search (e.g., looking for a specific product by its exact ID or name in an online store) is handled by traditional relational databases (RDBMS). Suggestions or recommendations (e.g., finding products with similar features, style, or price range when you don’t know the exact item) rely on vector stores, which compare items based on their vector embeddings to provide relevant recommendations. Therefore, conventional databases retrieve exact matches, while vector stores focus on similarity-based retrieval.
Vector stores are primarily used in machine learning and data retrieval applications where the goal is to find semantically similar information. Following are some of their use cases:
- Retrieval in RAG-based systems.
- Recommendation systems through similarity search.
- Anomaly detection by identifying unusual or unknown queries.
- Vector search for NLP applications like document retrieval.
- Image and video retrieval.
Structure of a Vector Store
A vector store consists of the following essential elements:
- Vectors/Embeddings: These are mathematical representations of images, audio, or text and form the core component of a vector store.
- Metadata: Additional information about the vector such as: time, date, and location for images, or author, publication year, and topic for books.
- Original data: While not always necessary, in RAG applications it can be useful to store the original text or data in the vector store.
- Unique ID: Each row in the vector store is identified by a unique ID generated by the system.
Popular Vector Stores
Following are some of the commonly used vector stores:
- Pinecone
- FAISS
- Qdrant
- Chroma
Key Features of Vector Stores
The strength of a vector store lies in its
- High-speed similarity search, and
- Scalability and integration with machine learning pipelines.
How Do Vector Stores Work?
When querying a vector store, two main operations are commonly used:
- Cosine Similarity: Used for recommendations, such as finding similar products. The input (e.g., a product description) is converted into a vector, and the vector store applies cosine similarity to identify the top k similar vectors. The metadata then helps retrieve relevant information, like product details. E-commerce websites and social media platforms use similar recommendation systems.
- Dot Product: Another common method for comparing vectors.
Types of Vector Stores
- Cloud-based, Fully Managed Services — These are hosted on the cloud, requiring only an API key for access. You don’t have to manage the infrastructure, making them easy to set up and scale. However, they come with associated cloud service costs. Examples include Pinecone and Qdrant.
- Locally Managed Vector Databases — If you prefer to keep sensitive data off the cloud or have specific client requirements for local RAG systems, this is a suitable option. You will need to manage storage, scalability, and resource allocation yourself. Examples include FAISS and Chroma.
Key Benefits of Vector Stores
- Efficient Data Storage: Vector stores are optimized for high-dimensional vector data.
- Fast Retrieval: They are designed for quick similarity searches and responses.
- Improved Semantic Understanding: Embedding models store vectors based on their semantic relationships, ensuring meaningful representation of data.
Choosing between vector stores depends on your specific needs, resources, and project requirements. When pushing data into a vector store, you have the flexibility to structure and customize its metadata based on the specific needs of your application. You can even add additional fields to enrich the metadata, making your system more efficient and tailored to your use case.
It’s essential to consider optimization techniques to ensure your system performs well. Factors like token cost, the number of chunks created, the vectors stored in the vector store, the top n documents retrieved from the store, and the chunks sent to the LLM in a RAG system all play a critical role.
Additionally, always ensure that keys, such as API keys and credentials, are securely stored in secret files to protect your system from potential security risks. Failing to do so could compromise the entire system setup.
Examples: Data Storage using LangChain
LangChain integrates seamlessly with vector stores, allowing us to build powerful language-based applications that use vector embeddings for enhanced retrieval and processing.
- Store Data using FAISS
from langchain_community.vectorstores import FAISS from langchain_huggingface.embeddings import HuggingFaceEmbeddings # Initialize the Hugging Face embedding model embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2") # Store embeddings into the vector store vector_store = FAISS.from_documents( documents=chunks, embedding=embeddings )
Data Retrieval
Data retrieval is the process of finding and extracting relevant information or documents from a vector store based on user prompt. A user asks questions from the specialized knowledge source to get the most relevant answers, so the vector store needs to be used programmatically for the retrieval process.
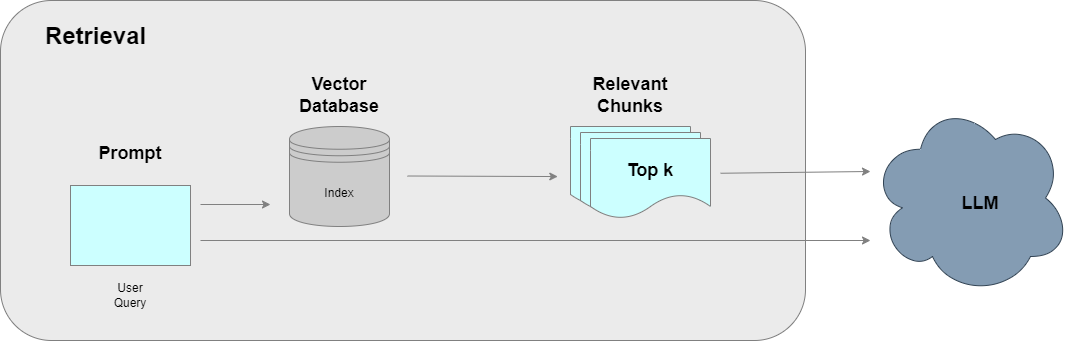
Types of Retrievers
There are many different types of retrievers in LangChain including:
- Vector store-backed retriever — It uses a vector store as a retriever to retrieve documents using search methods like similarity search, MMR, etc.
- MultiQuery retriever — It addresses the shortcomings of distance based retrieval by generating multiple queries from a prompt and retrieving relevant chunks by taking union across all queries. It captures different perspectives of a complex prompt and produces better results.
- Contextual compression retriever — It reduces the cost of LLM calls by compressing or shortening the documents having relevant information or dropping the irrelevant documents altogether to generate a good quality response.
- Custom retriever — We can design our own retriever by extending the BaseRetriever in LangChain to retrieve information from an external knowledge source.
- Ensemble retriever — It ensembles the results of multiple retrievers for better performance and more robust results.
Some other retrievers are:
- SVM retriever —It matches the most relevant documents by distinguishing them from irrelevant ones.
- TF/IDF retriever — It focuses on the words which are most repeated or most diverse in our system for document retrieval.
These retrievers are important when you are expected to get keywords from a user instead of a query.
The Process of Retrieval
When a user asks a question, it is converted into a vector. This vector then goes to the vector store through a retriever interface. The vector store finds n number of vectors similar to the query vector. To match the user’s question to similar vectors, there are various methods, some of which are:
- Dot product
- Cosine similarity
- MMR — Maximum marginal relevance
Why do we want to match these vectors for similarity? Basically we want to find out which vectors in the stored content match with the question asked by the user as only those similar vectors would be useful for us to generate a response through LLM. So we actually fetch the data relevant to the question from the vector store.
Vector Store as a Retriever
The simplest form of information retrieval is to use a vector store as a retriever. A vector store-backed retriever uses a vector store to retrieve documents. It is a lightweight wrapper around the vector store class to make it conform to the retriever interface. It uses similarity search to retrieve information in the form of relevant chunks based on distance between vectors. So we retrieve only the required information from a source in order to give response to a user instead of retrieving all the information.
A vector store contains:
- Vector,
- Text associated with the vector, and
- Metadata
The vectors are stored in the vector store in a meaningful representation through an embedding model. Our ultimate goal is to connect our data to an LLM. To interact with the LLM, we need to retrieve data from the vector store and then send it to the LLM along with our query or prompt to get the desired response in a structured format. That’s why we retrieve semantically similar chunks based on the query. The query is converted into vectors and meaningful comparisons are made to retrieve the similar vectors. Using vector store retrievers is ideal when handling large amounts of embedded data because they allow efficient access to relevant chunks.
Semantic Similarity
When data is retrieved, we only get its associated text chunk along with metadata and not the original vector because we only need those text chunks to be used in our application for further processing. Vectors are used for mathematical operations which cannot be performed on text. This concept is referred to as semantic search. Semantic search goes beyond keyword search (which relies on the occurrence of specific words in the search input) to find contextually relevant data based on the conceptual similarity of the input string. The vector store retriever uses similarity search by default.
Maximum Marginal Relevance (MMR)
Maximum marginal relevance (MMR) is a method used to avoid redundancy while retrieving relevant items to a query.
To process repeated information is a waste of cost and time. We want to filter out repeated information from relevant information. MMR finds closest chunks and removes or discards the chunks with repeated information. Instead of merely retrieving the most similar items, MMR ensures a balance between relevancy and diversity in the items retrieved. It reduces redundancy by selecting the most diverse set of relevant information. This is particularly important when balancing coverage and efficiency in information retrieval.
Whether to use MMR or not depends on the application you are building. For example, if a lawyer wants to retrieve all relevant cases from different regions for a particular scenario, MMR won’t be useful because he requires to have all the information. If limited information is required, you may use MMR. So this is case specific. Whenever you need diversity in response, you’ll need to use MMR.
To choose the appropriate retriever, you need to know:
- What type of data do you have?
- Who is the end user of your application?
Example: Data Retrieval using LangChain
- Vector Store as Retriever
Similarity Search Retrieval
# Retrieve relevant information using similarity search retriever = vector_store.as_retriever() # uses similarity search by default docs = retriever.invoke("Ask any question from the document here")
- Maximum Marginal Relevance (MMR) Retrieval
# Retrieve relevant information using maximum marginal relevance retrieval retriever = vector_store.as_retriever(search_type="mmr") # uses mmr as search type docs = retriever.invoke("Ask any question from the document here")
- Similarity Score Threshold Retrieval
# Retrieve relevant information using similarity score threshold retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5} ) docs = retriever.invoke("Ask any question from the document here")
- Specifying Top k Documents
# Retrieve top k relevant documents retriever = vector_store.as_retriever(search_kwargs={"k": 3}) docs = retriever.invoke("Ask any question from the document here")
Use of Large Language Models (LLMs) in RAG
Large language models (LLMs) are highly complex neural networks trained on vast amounts of text data and typically consist of billions of parameters, enabling them to understand human language at an advanced level. They are capable of generating high quality text and inference. There are a lot of variants of LLMs which can be used in a RAG based application. Some of them include:
- GPT (Generative Pre-trained Transformer) by OpenAI
- Claude by Anthropic
- Llama by Meta
- Gemini by Google, and many more.
Each LLM has a predefined context window, which refers to the number of tokens it can process simultaneously. Using these LLMs has a usage cost associated with each of them. Additionally, multimodal LLMs are gaining popularity due to their capability to process and generate text, speech, images, and video content.
Each large language model varies in its reasoning capabilities, particularly in mathematical reasoning and generating nuanced responses. While some tasks require the advanced reasoning of larger LLMs, mini models are often sufficient for specific tasks, especially where we don’t rely on the internal knowledge of the LLM — such as in RAG-based systems. In these cases, mini models can be more cost-effective and focused on refining responses rather than using a model’s full knowledge base.
Understanding the capacity, reasoning power, and cost implications of each LLM ensures that the right model is chosen for the right use case, balancing power with efficiency. Therefore, specialized LLMs optimize cost and performance in practical applications.
The quality of response generated through a RAG system highly depends on the correctness of the retrieved information as this retrieved information along with the user prompt is passed to the LLM for response generation. Ultimately, the success of a RAG system lies in its ability to retrieve the most relevant information effectively. Careful selection of retrieval methods and LLM models tailored to the task ensures optimal performance and cost efficiency.
Synthesis
Synthesis is the final component of a RAG pipeline where a response is generated for the user through an LLM. The user prompt and relevant chunks retrieved from a vector database during data retrieval are passed to the LLM which then generates a context augmented response that answers the question asked by the user. The response can be structured in any required format.
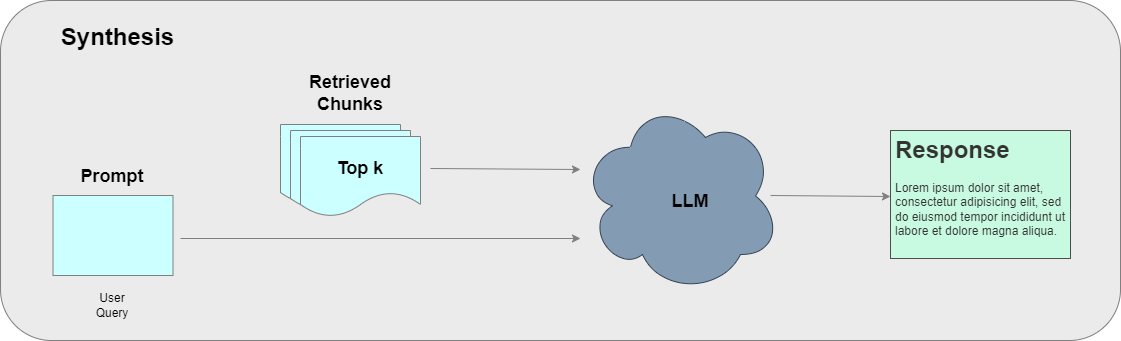
To make our RAG applications controllable and customizable, we use the concept of chains which enable us to connect different components of a RAG-based system.
What are Chains?
Chains refer to a sequence of calls to combine multiple components of a RAG-based application. Let’s say we want to develop an AI-powered chatbot. We’ll need to develop a conversation chain for this purpose.
LangChain — a Python framework to build LLM-powered applications — provides us the facility to use chains. There are many different types of chains available in LangChain. Let’s explore the components and elements of different chains, how they work, and how we can use them in our applications. The most common way to use chains is through LCEL (LangChain Expression Language).
What is LCEL?
LCEL (LangChain Expression Language) is a standard way in LangChain that allows for the creation and execution of custom chains. It helps in the integration of different components and provides streaming, asynchronous support, and parallel execution. The chains can be easily modified or extended. Additionally, LangChain implements a Runnable protocol for interaction between components.
Runnable
Every LCEL object implements the Runnable interface. Runnables are used to build custom chains.
There are three common methods to call the Runnable interface:
- stream — Streams chunks of a response.
- invoke — Calls the chain on an input.
- batch — Calls the chain for multiple inputs.
If you have a single query, you can simply invoke the chain and you’ll get the response. If you have a list of inputs, you’ll use batch call and it will give you the responses in a list. The stream method is used to display the response in chunks so that you can view the response while it’s being generated.
Runnable Lambda
Runnable Lambda converts a Python callable into a Runnable.
from langchain_core.runnables import RunnableLambda # Define a RunnableLambda that takes a string as input, # reverses it, and then repeats the reversed string twice. runnable = RunnableLambda(lambda s: (s[::-1]) * 2) # Invoke the runnable with the string "hello" result = runnable.invoke("hello") print(result) # Output: "olleholleh"
Runnable Sequence
A Runnable sequence is a composition of multiple Runnables invoked sequentially, where the output of one serves as the input to the next. It can be instantiated directly or by using the | operator. Whenever you need to invoke a chain, you make its Runnable interface and the Runnable sequence executes all the steps of that chain in a sequence.
Implementation using the | operator:
from langchain_core.runnables import RunnableLambda # Define a sequence of RunnableLambda instances that process a string # Step 1: Remove leading and trailing whitespace # Step 2: Convert the string to uppercase # Step 3: Replace spaces with underscores # Step 4: Add "Processed:" prefix to the string sequence = RunnableLambda(lambda s: s.strip()) | \ RunnableLambda(lambda s: s.upper()) | \ RunnableLambda(lambda s: s.replace(" ", "_")) | \ RunnableLambda(lambda s: f"Processed: {s}") # Invoke the sequence with the input string " hello world " result = sequence.invoke(" hello world ") print(result) # Output: "Processed: HELLO_WORLD"
Alternative implementation by directly calling the RunnableSequence:
from langchain_core.runnables import RunnableLambda, RunnableSequence # Define individual RunnableLambda steps for processing a string strip = RunnableLambda(lambda s: s.strip()) # Step 1: Remove leading and trailing whitespaces uppercase = RunnableLambda(lambda s: s.upper()) # Step 2: Convert the string to uppercase replace = RunnableLambda(lambda s: s.replace(" ", "_")) # Step 3: Replace spaces with underscores prefix = RunnableLambda(lambda s: f"Processed: {s}") # Step 4: Add "Processed:" prefix to the string # Create a RunnableSequence that combines all the individual steps sequence = RunnableSequence(strip, uppercase, replace, prefix) # Invoke the sequence with the input string " hello world " result = sequence.invoke(" hello world ") print(result) # Output: "Processed: HELLO_WORLD"
Runnable Parallel
A Runnable parallel is a composition that invokes multiple Runnables concurrently, providing the same input to each.
from langchain_core.runnables import RunnableLambda, RunnableParallel # Define individual RunnableLambda functions for different string operations reverse = RunnableLambda(lambda s: s[::-1]) # Function to reverse the input string uppercase = RunnableLambda(lambda s: s.upper()) # Function to convert the string to uppercase length = RunnableLambda(lambda s: len(s)) # Function to calculate the length of the string # Create a RunnableParallel with a mapping (dictionary) of operations parallel = RunnableParallel({ "reverse": reverse, "uppercase": uppercase, "length": length }) # Invoke the parallel sequence with the input string "hello" result = parallel.invoke("hello") print(result) # Output: {'reverse': 'olleh', 'uppercase': 'HELLO', 'length': 5}
Runnable parallel can only be used when input of the next chain is not dependent on the output of the previous one, therefore, you can use this only if the inputs are independent of each other.
Runnable Passthrough
A Runnable passthrough allows to pass through the inputs unchanged.
from langchain_core.runnables import RunnablePassthrough # Define a RunnablePassthrough that passes the input unchanged passthrough = RunnablePassthrough() # Invoke the passthrough result = passthrough.invoke("hello world") print(result) # Output: "hello world"
Prompt Templates
Prompt templates enable us to dynamically incorporate user prompts into our RAG system. We have to send the retrieved context along with the prompt to an LLM in order to retrieve information through a RAG system, therefore we use prompt templates for this purpose. Let’s look at a few of them.
Basic Prompt Template
A simple template that allows for dynamic input replacement within a predefined string.
from langchain_core.prompts import PromptTemplate # Define a template for the prompt that includes a placeholder for the country template = "What is the capital of {country}?" # Create a PromptTemplate instance with the defined template prompt_template = PromptTemplate(template=template) # Format the template by replacing the placeholder with the specified country ("Pakistan") prompt = prompt_template.format(country="Pakistan") print(prompt) # Output: What is the capital of Pakistan?
Few-Shot Prompt Template
A template designed to provide a few examples to guide the model’s responses, enhancing its understanding of the desired output.
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate # Define a list of example queries and their corresponding answers examples = [ {"query": "How can I improve my time management skills?", "answer": "Start by prioritizing your tasks using the Eisenhower Matrix to distinguish between what's urgent and important."}, {"query": "What are some effective strategies for setting goals?", "answer": "Use the SMART criteria: make your goals Specific, Measurable, Achievable, Relevant, and Time-bound."} ] # Create a PromptTemplate for formatting the examples example_template = PromptTemplate( input_variables=["query", "answer"], # Define the input variables for the template template="User: {query}\nAI: {answer}" # Template structure for each example ) # Create a FewShotPromptTemplate using the examples and example_template few_shot_prompt = FewShotPromptTemplate( examples=examples, example_prompt=example_template, prefix="Here are some examples of questions and answers:", suffix="User: {query}\nAI: {answer}\n", input_variables=["query"], example_separator="\n\n" ) # Format the few-shot prompt with a new user query and corresponding answer prompt = few_shot_prompt.format(query="How do I stay motivated during long projects?", answer="Break down the project into smaller milestones and celebrate each achievement.") print(prompt)
Chat Prompt Template
A specialized template for chat models that formats a sequence of messages allowing for distinct roles (e.g., human, AI).
from langchain_core.prompts import ChatPromptTemplate # Define a ChatPromptTemplate from a list of message tuples. # The first element in each tuple represents the speaker ("human" or "ai"), # and the second element is the message template. chat_template = ChatPromptTemplate.from_messages([ ("human", "Can you tell me about {author}?"), # Human asks about the author ("ai", "{author} is a renowned author known for {notable_work}.") # AI responds with author details ]) # Format the chat prompt with specific values for the placeholders # Replaces {author} with "Jane Austen" and {notable_work} with "Pride and Prejudice" messages = chat_template.format_messages(author="Jane Austen", notable_work="Pride and Prejudice") print(messages)
Output Parsers
An output parser is a component that processes outputs from AI models, transforming them into a desired format or structure. Different output parsers can be used to get the response in a required format such as a string, a dictionary, or JSON format.
StrOutputParser
from langchain_core.output_parsers import StrOutputParser # Initialize the parser parser = StrOutputParser() # Define a string output from an AI explaining a concept ai_response = """ Machine learning is a subset of artificial intelligence that focuses on enabling systems to learn from data patterns and make decisions without being explicitly programmed. It is widely used in applications like recommendation systems, image recognition, and natural language processing. """ # Use the parser to process the AI response parsed_output = parser.invoke(ai_response) print(parsed_output)
JsonOutputParser
from langchain_core.output_parsers import JsonOutputParser # Initialize the JSON parser parser = JsonOutputParser() # Simulated AI response in JSON format (string) ai_response = """ { "name": "John Doe", "age": 30, "occupation": "Software Engineer", "skills": ["Python", "Machine Learning", "Data Analysis"] } """ # Parse the JSON response parsed_output = parser.invoke(ai_response) # Print the parsed output as a dictionary print(parsed_output) # Access specific fields from the parsed JSON output print(f"Name: {parsed_output['name']}") print(f"Skills: {', '.join(parsed_output['skills'])}")
Types of Chains
There are four common types of chains:
- Question/Answering (Q/A) Chain
- Question/Answering (Q/A) Retrieval Chain
- Conversational Chain
- Conversational Retrieval Chain
The selection of a chain depends on the requirements of the RAG system being built. Let’s explore each of these chains in detail.
1. Question/Answering (Q/A) Chain
A Q/A chain is used to do direct question answering with an LLM. The model answers directly using its internal knowledge.
# Q/A Chain from langchain_core.prompts import PromptTemplate from langchain_groq import ChatGroq # Define a prompt template for formatting the question prompt_template = "Q: {question}\n" prompt = PromptTemplate(template=prompt_template, input_variables=["question"]) # Instantiate the ChatGroq LLM with the specified model llm = ChatGroq(model="mixtral-8x7b-32768") # Combine the prompt and LLM into a chain where the prompt output is passed to the LLM qa_chain = prompt | llm # This creates a chain that takes the formatted question and passes it to the model # Invoke the chain with a specific question response = qa_chain.invoke("What is the capital of Japan?") # Print the content of the response print(response.content)
2. Question/Answering (Q/A) Retrieval Chain
A Q/A retrieval chain is used to add context to an LLM response. It retrieves relevant documents from a knowledge base (e.g. personal documents, research papers) and generates an answer.
# Q/A Retrieval Chain from langchain_groq import ChatGroq from langchain.chains import create_retrieval_chain from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate # Initialize the ChatGroq LLM with the specific model llm = ChatGroq(model="mixtral-8x7b-32768") # Define the system prompt that instructs the LLM how to answer questions based on retrieved context system_prompt = ( "You are an assistant for question-answering tasks. " "Use the following pieces of retrieved context to answer " "the question. If you don't know the answer, say that you " "don't know. Use three sentences maximum and keep the " "answer concise." "\n\n" "{context}" # Placeholder for the retrieved context ) # Create a chat prompt template with a system message and human message prompt = ChatPromptTemplate.from_messages( [ ("system", system_prompt), # System message contains instructions and context ("human", "{input}"), # Human message includes the user's input question ] ) # Create a document chain that combines the LLM with the prompt question_answer_chain = create_stuff_documents_chain(llm, prompt) # Combine the retrieval chain with the question-answering chain # The retrieval chain retrieves relevant documents and feeds them into the question-answering chain retrieval_chain = create_retrieval_chain(retriever, question_answer_chain) # Invoke the chain with a question, and the retriever will provide context for the LLM to generate an answer response = retrieval_chain.invoke({"input": "Ask the question from the user here"}) print(response['answer'])
3. Conversational Chain
A conversational chain is used to add chat history to simple question answering. It maintains context from previous interactions without document retrieval.
# Conversational Chain from langchain_core.chat_history import InMemoryChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistory from langchain_groq import ChatGroq # Create an external store (a dictionary) for maintaining chat history across multiple sessions store = {} # Function to get or create chat history for a specific session based on session_id def get_session_history(session_id: str) -> InMemoryChatMessageHistory: # If the session_id doesn't exist in the store, create a new InMemoryChatMessageHistory if session_id not in store: store[session_id] = InMemoryChatMessageHistory() # Return the chat history associated with the given session_id return store[session_id] # Initialize the ChatGroq model llm = ChatGroq(model="mixtral-8x7b-32768") # Create a chain that can handle message history, linking it with the LLM and session history retrieval chain = RunnableWithMessageHistory(llm, get_session_history) # First conversation with AI in session "1" question_1 = "Hello, there?" response_1 = chain.invoke( question_1, config={"configurable": {"session_id": "1"}}, # Specify the session_id for tracking message history ) # Second conversation in the same session "1" question_2 = "What can you help me with today?" response_2 = chain.invoke( question_2, config={"configurable": {"session_id": "1"}}, # Continue in the same session "1" ) # Third conversation in the same session "1" question_3 = "Can you explain the concept of AI in one sentence?" response_3 = chain.invoke( question_3, config={"configurable": {"session_id": "1"}}, # Continue in session "1" ) # Print the responses to see the conversation flow print("Human:", question_1) print("AI: ", response_1.content, "\n") print("Human:", question_2) print("AI: ", response_2.content, "\n") print("Human:", question_3) print("AI: ", response_3.content, "\n")
4. Conversational Retrieval Chain
A conversational retrieval chain is used to add chat history to a simple retrieval chain. It retrieves documents and maintains conversational context across multiple questions.
# Conversational Retrieval Chain from langchain.chains import create_history_aware_retriever, create_retrieval_chain from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_community.chat_message_histories import ChatMessageHistory from langchain_core.chat_history import BaseChatMessageHistory from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.runnables.history import RunnableWithMessageHistory from langchain_groq import ChatGroq # Initialize the large language model llm = ChatGroq(model="mixtral-8x7b-32768") ### Contextualize question ### # Define a system prompt to contextualize the user question by making it standalone contextualize_q_system_prompt = ( "Given a chat history and the latest user question " "which might reference context in the chat history, " "formulate a standalone question which can be understood " "without the chat history. Do NOT answer the question, " "just reformulate it if needed and otherwise return it as is." ) # Create a ChatPromptTemplate for contextualizing questions with chat history contextualize_q_prompt = ChatPromptTemplate.from_messages( [ ("system", contextualize_q_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ] ) # Create a history-aware retriever to handle chat history history_aware_retriever = create_history_aware_retriever( llm, retriever, contextualize_q_prompt ) ### Answer question ### # Define a system prompt to generate concise answers using retrieved context system_prompt = ( "You are an assistant for question-answering tasks. " "Use the following pieces of retrieved context to answer " "the question. If you don't know the answer, say that you " "don't know. Use three sentences maximum and keep the " "answer concise." "\n\n" "{context}" # Placeholder for retrieved context ) # Create a ChatPromptTemplate for the question-answering chain qa_prompt = ChatPromptTemplate.from_messages( [ ("system", system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ] ) # Create a document chain for handling question answering using the LLM and the QA prompt question_answer_chain = create_stuff_documents_chain(llm, qa_prompt) # Combine the history-aware retriever and the QA chain to create the retrieval chain retrieval_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain) ### Statefully manage chat history ### # Store for maintaining chat history across multiple sessions store = {} # Function to get or create chat history for a given session def get_session_history(session_id: str) -> BaseChatMessageHistory: # If no session history exists for the given session_id, create a new history if session_id not in store: store[session_id] = ChatMessageHistory() return store[session_id] # Create a conversational retrieval chain that manages chat history statefully conversational_retrieval_chain = RunnableWithMessageHistory( retrieval_chain, get_session_history, input_messages_key="input", history_messages_key="chat_history", output_messages_key="answer", ) # First conversation: question about the document question_1 = {"input": "What is the document about?"} response_1 = conversational_retrieval_chain.invoke( question_1, config={ "configurable": {"session_id": "abc123"} }, )["answer"] # Second conversation in the same session: asking to summarize the main points question_2 = {"input": "Summarize its main points?"} response_2 = conversational_retrieval_chain.invoke( question_2, config={"configurable": {"session_id": "abc123"}}, )["answer"] # Printing the responses to see the conversational retrieval flow print("Human:", question_1["input"]) print("AI: ", response_1, "\n") print("Human:", question_2["input"]) print("AI: ", response_2, "\n")
Resume Analyzer using RAG
Let’s say you are a recruiter or an HR Manager and you have a pool of CVs or resumes to analyze and see if they have the right skillset according to your job description. Now looking at each and every resume is a time consuming and tedious task. How about uploading a resume and your job description with the required skills and getting a detailed analysis about how much the resume matches a particular job description. Sounds interesting, Right!
Well, this can be easily automated through a RAG-based system where your external knowledge base would be the resume or CV you want to analyze. You can chat with it and ask different questions to see if it meets the requirements or not. This tool can help you quickly segregate matching resumes from the unmatched ones letting you focus on just the useful ones having the required skillset.
Let’s build this application step by step. We’ll be using Streamlit — an open source Python framework for interactive data apps — to develop the frontend and LangChain — a Python framework for LLM-powered applications — to develop the backend. Additionally, we’ll use Groq — a Generative AI solutions platform for fast inference — to connect with LLMs. Here’s a glimpse of what the application would look like.
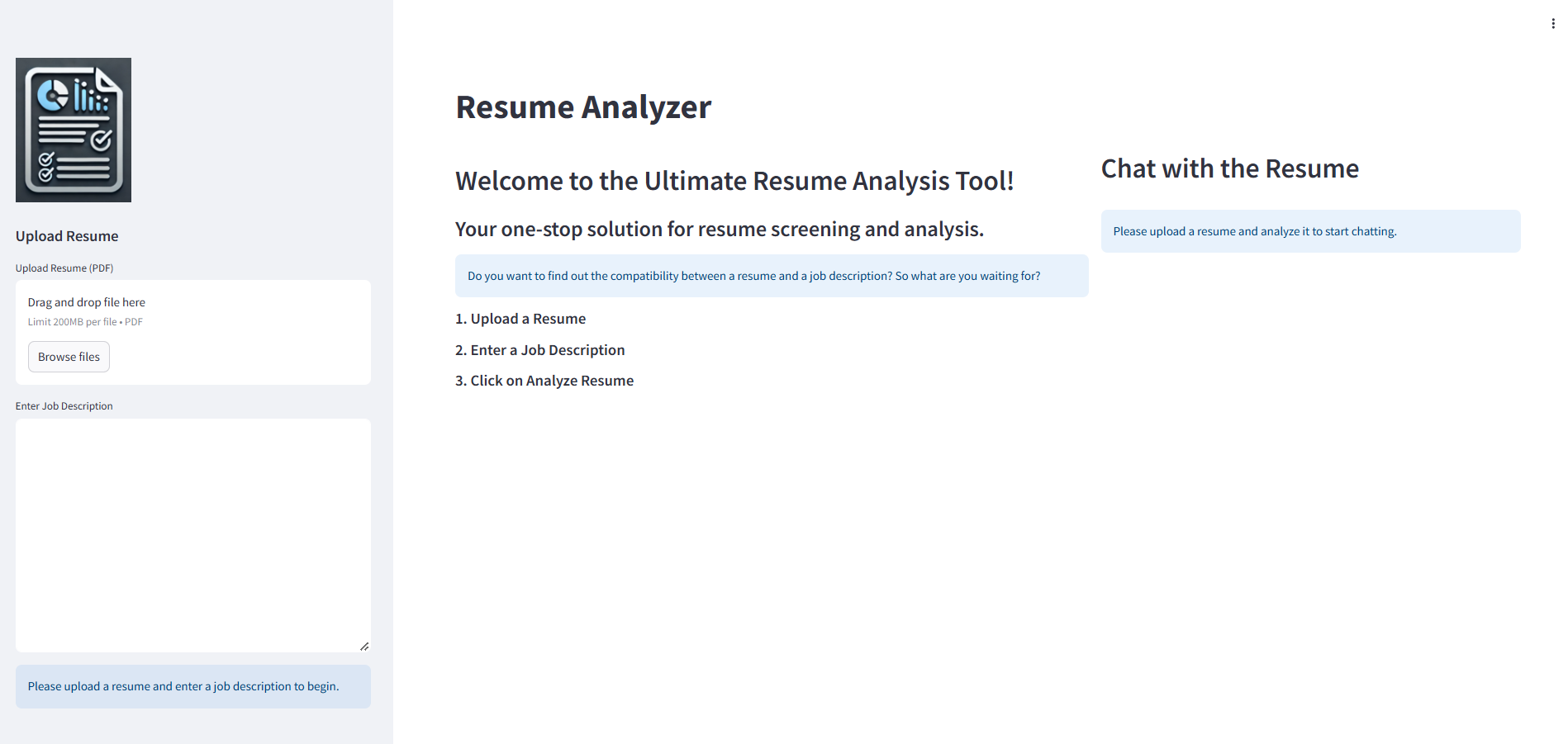
Installing necessary libraries
Install the following python libraries before building the application from the requirements.txt file.
- streamlit
- langchain_community
- langchain-huggingface
- langchain-groq
- pypdf
- faiss-cpu
- python-dotenv
Setting up the Environment Variables
Set up the Groq API key in a .env file.
GROQ_API_KEY="Your_API_Key"
Building the Frontend
- main_app.py
This is the main interface to upload the resume and job description and is displayed at the left side of the application. As soon as both the resume and job description have been uploaded, it will send the PDF file to the backend — Data Ingestion component of the RAG system — to load it, split it into text chunks, generate embeddings of text chunks, and store them into a vector store. After data ingestion, it will show a button to analyze the resume. When the user clicks on that button, the resume will be analyzed through the backend and the response will be displayed in the form of a detailed analysis.
import streamlit as st from backend.pdf_ingestion import load_split_pdf from backend.vector_store import create_vector_store from backend.analysis import analyze_resume import os import shutil # Main application including "Upload Resume" and "Resume Analysis" sections def render_main_app(): # Apply custom CSS to adjust the sidebar width st.markdown( """ <style> [data-testid="stSidebar"] { min-width: 25%; max-width: 25%; } </style> """, unsafe_allow_html=True ) # Moving the upload section to the sidebar with st.sidebar: st.header("Upload Resume") # Header for the upload section # File uploader for PDF resumes resume_file = st.file_uploader("Upload Resume (PDF)", type="pdf") # Text area for job description input job_description = st.text_area("Enter Job Description", height=300) if resume_file and job_description: # Check if both inputs are provided # Create a temporary directory if it doesn't exist temp_dir = "temp" os.makedirs(temp_dir, exist_ok=True) # Save the uploaded file to the temporary directory with open(os.path.join(temp_dir, resume_file.name), "wb") as f: f.write(resume_file.getbuffer()) # Load and split the PDF file into documents and chunks resume_file_path = os.path.join("temp", resume_file.name) resume_docs, resume_chunks = load_split_pdf(resume_file_path) # Create a vector store from the resume chunks vector_store = create_vector_store(resume_chunks) st.session_state.vector_store = vector_store # Store vector store in session state # Remove the temporary directory and its contents shutil.rmtree(temp_dir) # Button to begin resume analysis if st.button("Analyze Resume", help="Click to analyze the resume"): # Combine all document contents into one text string for analysis full_resume = " ".join([doc.page_content for doc in resume_docs]) # Analyze the resume analysis = analyze_resume(full_resume, job_description) # Store analysis in session state st.session_state.analysis = analysis else: st.info("Please upload a resume and enter a job description to begin.") # Display the analysis result if it exists in session state if "analysis" in st.session_state: st.header("Resume-Job Compatibility Analysis") st.write(st.session_state.analysis) else: st.header("Welcome to the Ultimate Resume Analysis Tool!") st.subheader("Your one-stop solution for resume screening and analysis.") st.info("Do you want to find out the compatibility between a resume and a job description? So what are you waiting for?") todo = ["Upload a Resume", "Enter a Job Description", "Click on Analyze Resume"] st.markdown("\n".join([f"##### {i+1}. {item}" for i, item in enumerate(todo)]))
GitHub - main_app.py
- chat_interface.py
This is the interface to chat with the uploaded resume and is displayed at the right side of the application. It uses the Data Retrieval and Synthesis components of a RAG system to have an interactive conversation with the resume. The user can ask different questions related to the resume and get context augmented response through the RAG system. The conversation between the user and the application is maintained through a conversational retrieval chain.
GitHub - chat_interface.py
Building the Backend
- pdf_ingestion.py
This is the function to load and split a PDF file using PyPDFLoader to load the file and RecursiveCharacterTextSplitter to split it into chunks. It returns both the documents and text chunks.
GitHub - pdf_ingestion.py
- vector_store.py
This function uses Hugging Face embeddings to store the text embeddings into a vector store. We are using FAISS (Facebook AI Similarity Search) as the vector store here.
GitHub - vector_store.py
- analysis.py
This function analyzes the resume using the LLM mixtral-8x7b-32768 from Groq API and full resume text as the context. The response is generated through a simple Q/A chain. The prompt template used here is extremely important because it defines the structure of the response in much detail. Here we can use the magic of prompt engineering to generate the response of our choice.
GitHub - analysis.py
Main Application
- app.py
This is the main entry point to the application. It renders the user interface to interact with the Resume Analyzer.
GitHub - app.py
Deployment
The application we have built is a basic version of a resume analysis tool just to get an understanding of how a RAG application works. It can be deployed on any cloud platform such as Hugging Face or Streamlit where you can easily interact with it. You can experiment with its different features — adding new functionalities or trying to modify the existing ones.
Resume Analyzer - Hugging Face
Conclusion
Retrieval augmented generation (RAG) is the most widely used technique in NLP applications. It augments latest and domain specific information to LLMs and utilizes their powerful capabilities to generate relevant, coherent, and useful responses. LangChain provides robust tools for building RAG applications. Many industry applications, especially customized chatbots, are built using RAG. Retrieval augmented generation makes it possible to interact with any external knowledge source in your own natural language. Its main components include data ingestion, retrieval, and synthesis. There can be hundreds of applications of RAG that can make our lives easier. A resume analysis tool is one such application that can be really helpful when there are hundreds of CVs to go through and you have very little time. A recruiter can get benefit from this amazing technology making his day to day tasks simple and effective. Even a job applicant can use this tool to see if his resume is the right fit for a particular job description.