This project implements a beginner-friendly, reproducible Retrieval-Augmented Generation (RAG) assistant built entirely in Jupyter Notebook.
The assistant ingests plain-text documents, splits them into overlapping chunks, computes sentence-level embeddings with sentence-transformers (all-MiniLM-L6-v2), stores vectors in a local ChromaDB collection, and answers natural language queries using a compact local LLM (google/flan-t5-small).
Key outcomes:
Sources: for traceability.rag_notebook.ipynb, data/*.txt (knowledge base), output_demo.txt (sample Q&A log), and requirements.txt.This submission demonstrates how an entry-level developer can build a traceable, testable RAG assistant and package it for evaluation in the AAIDC Module 1 review cycle.!

rag_proj/
├── rag_notebook.ipynb # Main notebook (ingest → embed → retrieve → generate)
├── data/ # Text documents used as knowledge base (publication*.txt)
├── output_demo.txt # Demo Q&A log (generated by the notebook)
├── README.md
├── requirements.txt
└── .gitignore
.txt files placed in data/.Embeddings and vector store
Retrieval + Answer generation
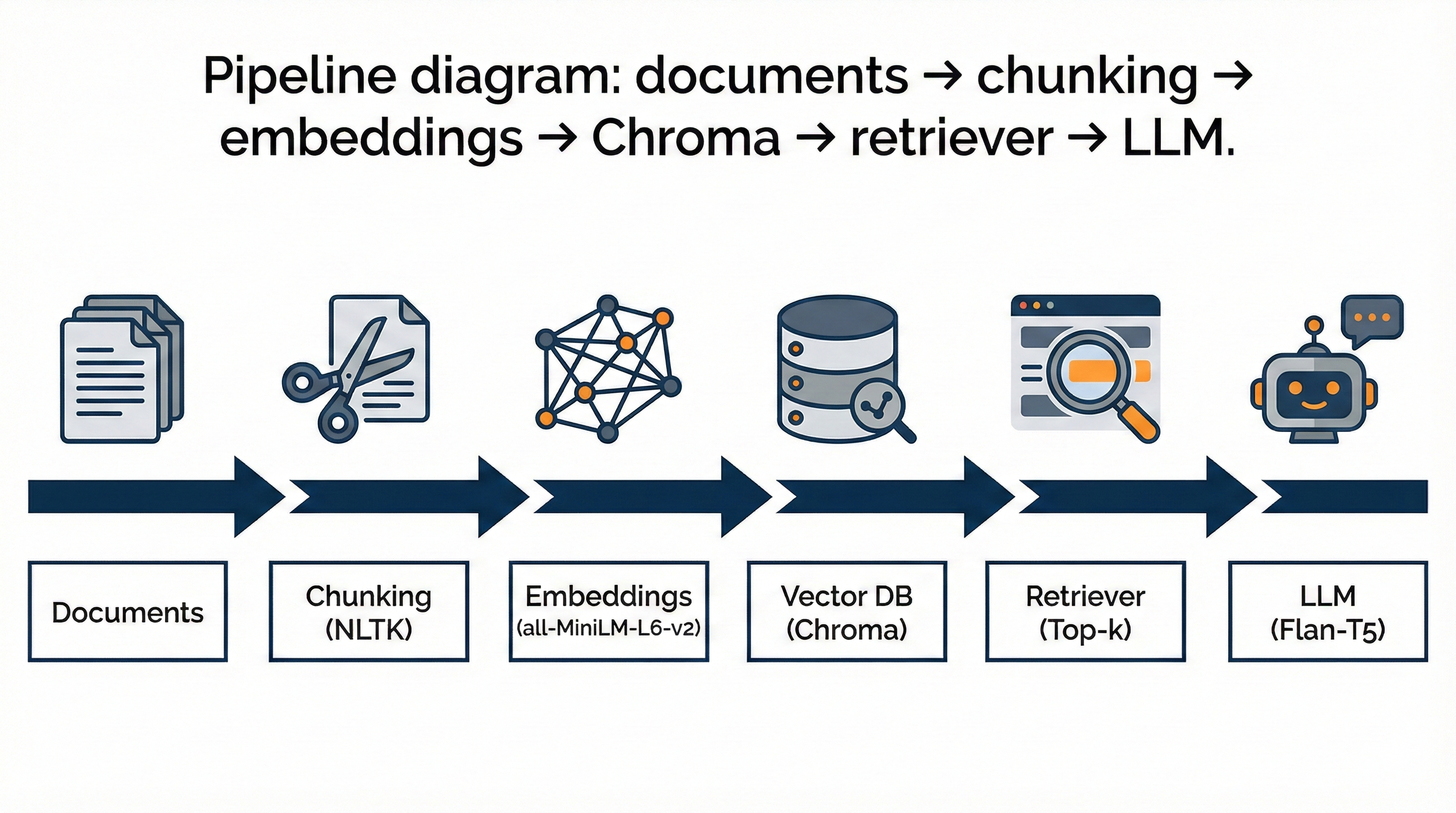
.txt files placed in data/.Chunking code (snippet used in notebook):
from nltk.tokenize import sent_tokenize def chunk_text(text, max_words=300, overlap_words=50): sents = sent_tokenize(text) chunks, cur, cur_count = [], [], 0 for sent in sents: w = len(sent.split()) if cur_count + w <= max_words or not cur: cur.append(sent); cur_count += w else: chunks.append(" ".join(cur)) overlap = " ".join(" ".join(cur).split()[-overlap_words:]) if overlap_words>0 else "" cur = [overlap] if overlap else [] cur.append(sent); cur_count = len(" ".join(cur).split()) if cur: chunks.append(" ".join(cur)) return chunks <!-- RT_DIVIDER --> # Results Demo Q&A (selected excerpts) The full demo log is in rag_proj/output_demo.txt. Example outputs captured during the demo: Q: What is this publication about? A: This publication explains how to build a Retrieval-Augmented Generation (RAG) assistant using local embeddings and ChromaDB, covering chunking, embeddings, retrieval, and answer generation. Sources: publication1.txt Q: Which tools are recommended in the documents? A: The documents list Chroma (vector DB), sentence-transformers (embeddings), and Flan-T5 (local generation). Sources: publication2.txt Q: What limitation is mentioned? A: The demo notes that the dataset is small and that retrieval accuracy depends on chunking and embedding quality. Sources: publication1.txt
