AskPDF is a Retrieval-Augmented Generation (RAG) chatbot that transforms the way users interact with long and complex PDF documents. By combining LangChain with Google Gemini, it allows users to upload PDFs and ask natural language questions, receiving answers that are not only accurate but also sourced from the original document.
In today’s digital world, PDFs are one of the most common formats for sharing knowledge—whether academic research papers, technical manuals, legal contracts, or policy documents. While convenient, these documents often span dozens or even hundreds of pages, making it difficult for readers to extract specific insights efficiently. Searching manually through lengthy reports is not only time-consuming but also increases the likelihood of overlooking critical information.
AskPDF addresses this challenge by offering an intelligent assistant that enables conversational interaction with PDFs. Instead of scanning line by line, users can simply ask questions and receive context-aware answers backed by document citations. This ensures that the output remains reliable and transparent compared to generic AI chatbots that often hallucinate or provide unsupported claims.
The main objective of AskPDF is to help students, researchers, and professionals save time, reduce cognitive load, and improve comprehension. For students, it means faster understanding of course readings and research materials. For professionals, it provides immediate access to important details hidden in technical manuals, contracts, or policies. Ultimately, the system transforms static PDFs into dynamic knowledge resources.
The design of AskPDF places equal emphasis on accuracy, safety, and user trust. To achieve this, several guardrails have been built into the system. The assistant avoids generating unsupported or speculative responses by restricting answers strictly to retrieved content from the uploaded PDF. Every response is grounded in the actual text and includes source citations for transparency.
File handling also prioritizes security. The system enforces a maximum file size limit to reduce risk of misuse or overload. Moreover, personal or sensitive documents are not stored without explicit user consent, ensuring data privacy and responsible deployment. Together, these measures strike a balance between functionality and ethical use of AI technology.
AskPDF is built on a modern stack designed for both performance and scalability. The frontend is developed in Next.js with Tailwind CSS for a clean user interface. The backend runs on FastAPI (Python), integrating seamlessly with LangChain and Gemini as the AI engine. Documents are transformed into embeddings using Gemini or optionally OpenAI, and stored in FAISS, a high-performance vector database.
For document processing, tools like PyMuPDF and PyPDFLoader handle PDF ingestion. Deployment is cloud-ready, with Vercel powering the frontend and Render or Railway used for backend services. Together, these technologies enable a smooth and reliable end-to-end user experience.
Users can upload PDF files, ask natural questions, and receive Gemini-powered answers that cite the relevant parts of the document. The system supports retrieval-augmented generation, combining chunking, embeddings, and FAISS-based vector search to ensure precise matching. Unlike simple keyword search, AskPDF retrieves the most relevant text passages and delivers responses enriched with context.
The inclusion of source tracking provides an added layer of trust, as users can verify where an answer originates in the PDF. This feature is particularly valuable for academic and professional use cases where accuracy and verifiability are essential.
The methodology behind AskPDF follows a structured pipeline that combines document processing, vector-based retrieval, and large language model reasoning. This ensures that user queries are always answered with precision and grounded in the original PDF content.
The process begins with PDF ingestion, where the uploaded file is parsed, and its text content is extracted using tools such as PyMuPDF or PyPDFLoader. Since raw text from PDFs can be lengthy and unstructured, it is divided into smaller, overlapping chunks using LangChain’s RecursiveCharacterTextSplitter. This step ensures that each segment of text retains sufficient context while remaining manageable for downstream processing.
Next, each chunk is transformed into a high-dimensional embedding vector using Gemini (or optionally OpenAI). These vectors are stored in FAISS, a specialized vector database optimized for fast similarity search. When a user submits a question, the retriever identifies the most relevant chunks by comparing semantic similarity between the query and the stored embeddings.
The retrieved chunks are then combined with the user’s query and passed to Google Gemini, which generates a context-aware response. Importantly, the system is designed to ground answers in the retrieved passages, ensuring that responses remain faithful to the original source material. Citations are provided alongside each answer to maintain transparency and allow users to verify the information.
This methodology not only reduces the risk of hallucinations but also provides a seamless way for users to interact with long and complex PDFs, transforming static documents into interactive, knowledge-rich resources.
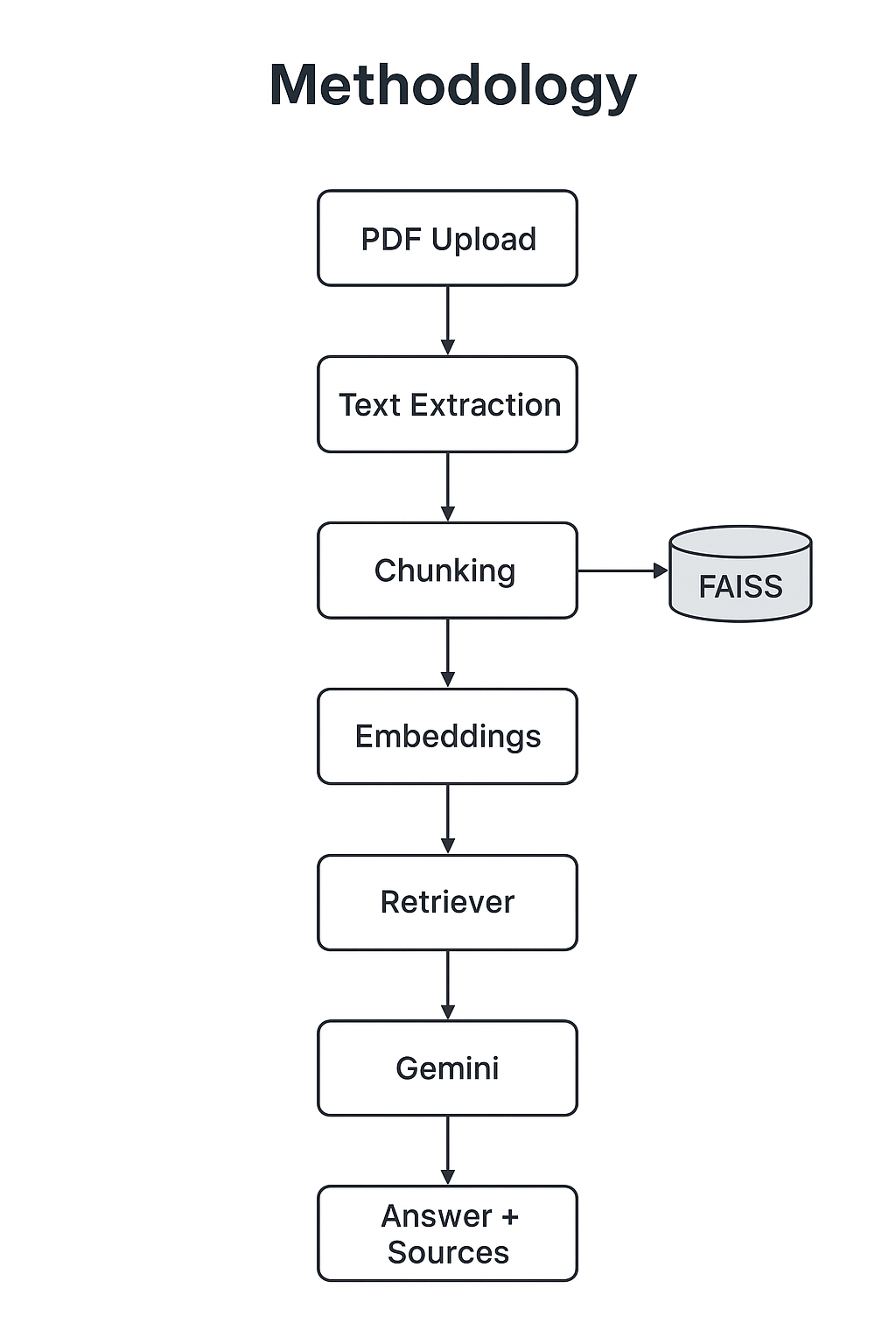
When a PDF is uploaded, the backend processes it in several steps. First, the text is extracted and divided into smaller chunks using LangChain’s RecursiveCharacterTextSplitter. Each chunk is then embedded into a vector representation and stored in FAISS for efficient retrieval.
When a user poses a question, the retriever selects the most relevant chunks from the vector database. These are combined with the user’s query and passed to Gemini, which generates a context-aware response. Importantly, the answer is grounded in the retrieved text, with references provided so users can trace the source material.
To run AskPDF locally, first obtain a Gemini API key from Google Makersuite. Set your API key as an environment variable:
# Linux / macOS export GOOGLE_API_KEY=your_api_key_here # Windows (PowerShell) setx GOOGLE_API_KEY "your_api_key_here"
Backend(Python)
cd backend python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate pip install -r requirements.txt uvicorn main:app --reload
Frontend (Next.js)
cd frontend npm install npm run dev
The live demo of AskPDF is available here:
👉 https://ask-pdf-two.vercel.app/
AskPDF demonstrates how Retrieval-Augmented Generation can transform the way people interact with lengthy and complex PDF documents. By combining reliable document retrieval with the reasoning capabilities of Google Gemini, the system ensures that users receive accurate, transparent, and source-backed answers. This approach not only saves time but also enhances comprehension for students, researchers, and professionals who rely on dense information sources. The project highlights the potential of RAG-based systems to bridge the gap between static documents and interactive knowledge assistants.
Looking ahead, there are several opportunities to strengthen and extend AskPDF. Future iterations could incorporate support for multiple file formats beyond PDFs, such as Word documents or web pages. Expanding the system’s scope to include domain-specific knowledge bases would further improve its utility across academic, legal, and enterprise contexts. Another direction is the integration of advanced evaluation metrics to measure retrieval accuracy and response quality, ensuring continuous improvement. Finally, stronger personalization and multi-document querying capabilities could make the assistant even more versatile, enabling richer insights across diverse information sources.
Through these enhancements, AskPDF can evolve into a robust, general-purpose assistant for navigating complex information landscapes while maintaining its commitment to accuracy, safety, and transparency.
This project is open-source.
https://github.com/Muhammad-Hashir-55/rag-chatbot