
The LangGraph‑Orchestrated Research Assistant is a Streamlit‑based web application designed for side‑by‑side comparison of scientific publications drawn from the Ready Tensor dataset. Leveraging LangChain, LangGraph agents, and the OpenAI API, the system automates:
The assistant leverages cutting-edge technologies to create a robust and scalable solution. LangChain and LangGraph together provide an orchestration framework for a multi-agent RAG pipeline, supporting document ingestion, intelligent querying, agent routing, and structured output generation. OpenAI embeddings and Chroma vector storage enable fast semantic retrieval, while ReAct-style external enrichment ensures access to up-to-date information.
The system is grounded in five primary architectural goals:
project_1_publications.json into clean, structured .txt files.Built around a LangGraph state machine that routes queries to multiple specialized agents:
Streamlit provides a responsive user interface:
Orchestration diagrams:
.mmd files for doc embeddingEnvironment configuration managed through .env file:
OPENAI_API_KEY, TAVILY_API_KEY safely handled.gitignore ensures secrets, logs, and large outputs are excluded from version control
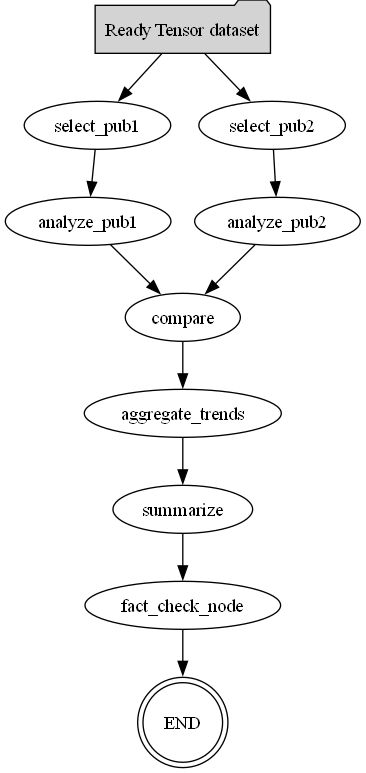
The flowchart below illustrates the system's LangGraph-driven orchestration logic:
.json of publications → individual .txt filespaths.py centralizes directory structure for cross‑platform useInteractive Streamlit UI:
Flowchart Outputs:
Export Formats: HTML / JSON of comparison results for downstream use
Agentic_AI_Developer_Certification_Project2/
├── src/
│ ├── app.py # Main Streamlit App UI (entry point for the web interface)
│ ├── explorer.py # Core logic for publication analysis using LangGraph and LLMs
│ ├── generate_flowchart_graphviz.py # Generates a Graphviz PNG diagram of the LangGraph orchestration flow
│ ├── generate_flowchart_mermaid.py # Generates a Mermaid diagram of the LangGraph orchestration flow
│ ├── loader.py # Converts JSON into individual .txt files from the Sample Ready Tensor dataset
│ ├── paths.py # Centralized path definitions
│ ├── utils.py # Helper functions for path and string handling
├── .env.example # Example environment file storing secret API keys
├── data/
│ ├── project_1_publications.json # Sample Ready Tensor dataset
│ └── sample_publications/ # Directory containing input publication `.txt` files
│ └── <publication .txt> # ↳ Each text file represents a single publication
├── requirements.txt # Dependency list for pip install (Streamlit, LangChain, etc.)
├── README.md # Project documentation explaining setup and usage
├── .gitignore # Specifies files/folders to be ignored by Git
├── LICENCE # Project license file
├── outputs/
│ ├── <comparison publ1 vs publ2 .html> # ↳ HTML output of comparisons
│ └── <comparison publ1 vs publ2 .json> # ↳ JSON output of comparisons
├── docs/
│ ├── publication_flowchart.png # ↳ Graphviz diagram (PNG)
│ ├── langgraph_flowchart.mmd # ↳ Mermaid diagram (MMD)
│ └── Untitled diagram _ Mermaid Chart-2025-07-09-115351.png # ↳ Mermaid diagram (PNG)
├── examples_screens/
│ └── <screenshot .jpeg> # ↳ UI usage screenshots
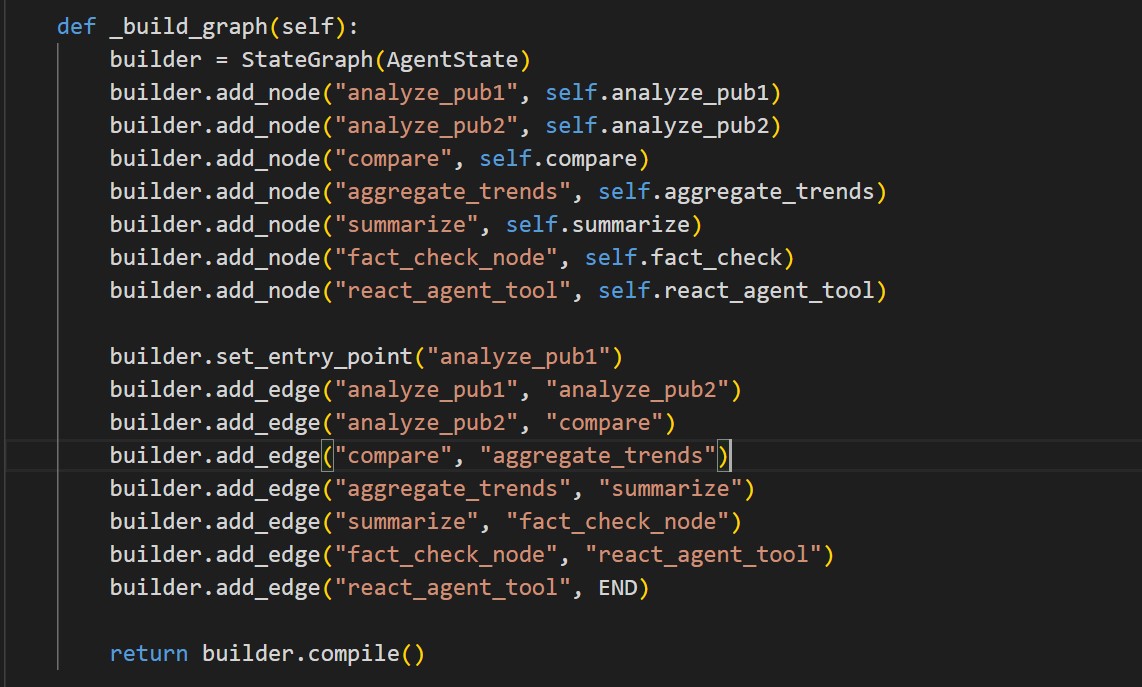
graph.add_node("compare", self.compare)graph.add_edge("compare", "aggregate_trends")AgentState is a TypedDict that carries information (e.g., comparison, trends) across the workflowAs each node (agent) completes, it receives the current state, updates fields (like
pub1_profileorsummary), and returns the updated state to the next node enabling sequential logic. The sharedAgentStatetyped dict underpins this continuity.
The following code snippet shows how graph is constructed:
Before running the application, make sure your environment is properly configured with the following:
Python 3.10+
Environment Variables:
OPENAI_API_KEY (OpenAI)TAVILY_API_KEY (Tavily for external searches)Clone & Checkout
git clone https://github.com/micag2025/Agentic_AI_Developer_Certification_Project2 cd Agentic-AI-Developer-Certification-Project2 git checkout main
Virtual Environment (recommended)
python3 -m venv .venv source .venv/bin/activate # macOS/Linux .\.venv\Scripts\activate # Windows
Install Dependencies
pip install -r requirements.txt
Configure Environment
Copy .env.example → .env and populate:
OPENAI_API_KEY=your_openai_key TAVILY_API_KEY=your_tavily_key
Ensure Data
Confirm data/project_1_publications.json is present.
Launch Streamlit
streamlit run src/app.py
Open in Browser
Navigate to http://localhost:8501 to access the Research Assistant.

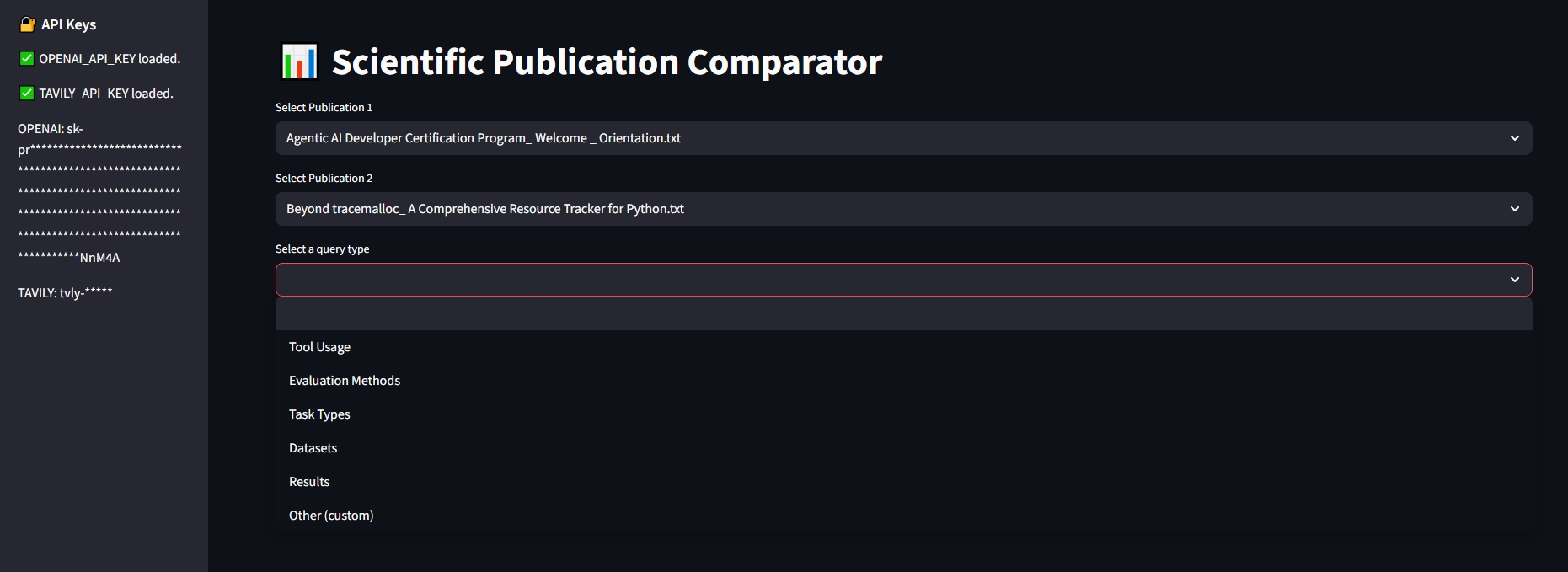
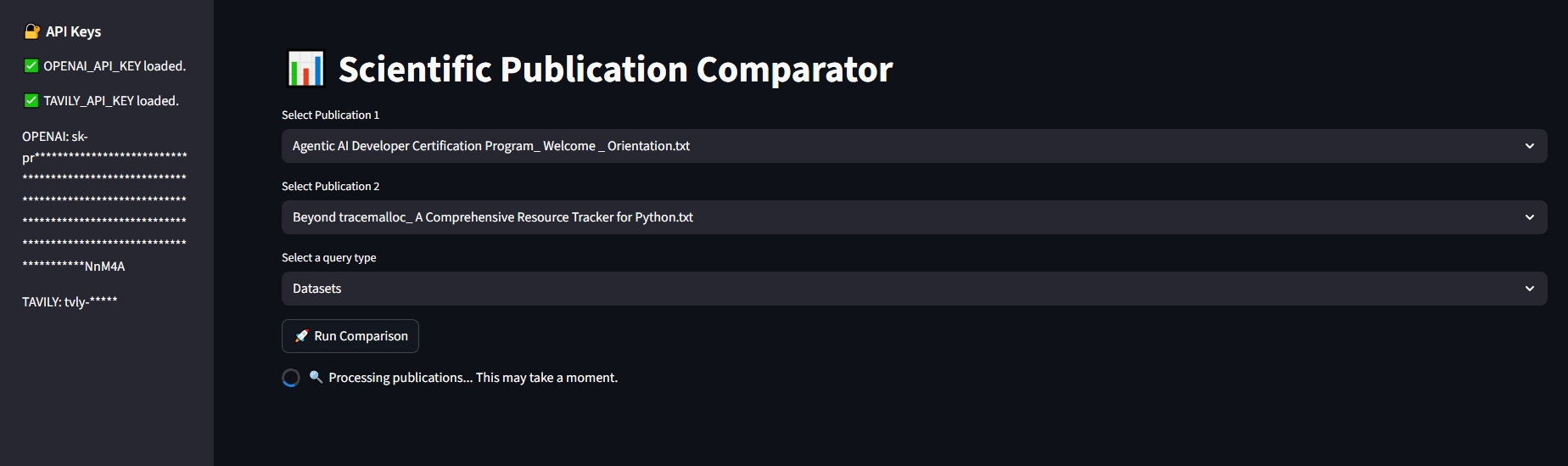
View Results
Side‑by‑side comparison table of extracted profiles

Fact‑checking annotations
Here's where the fact-checking node validates the results against the source documents.
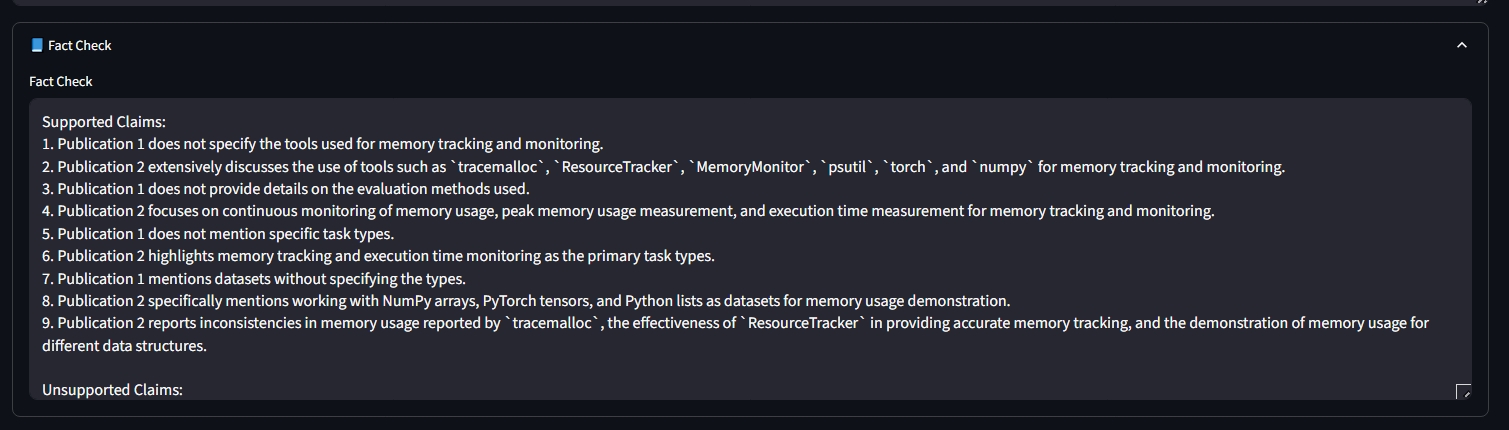
Enrichment insights sourced from external web search

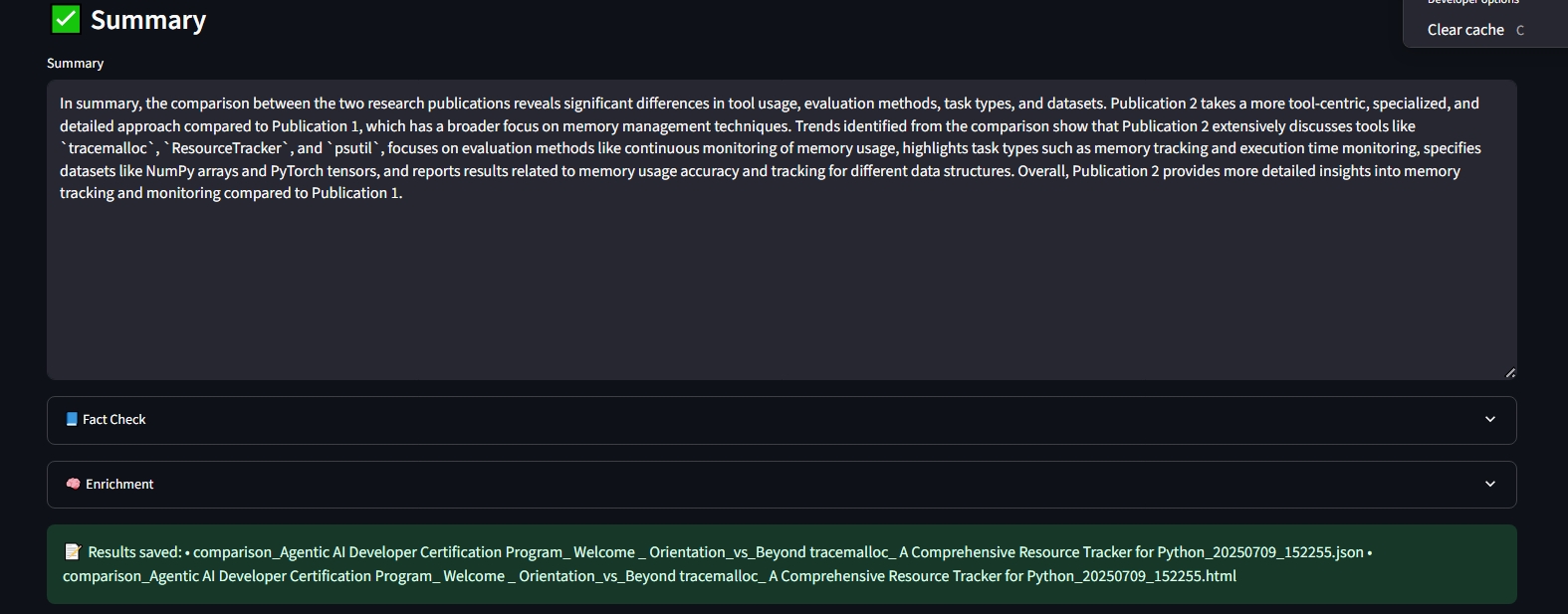
Overall final output
Finally, we get a structured response ready for user presentation off of the workflow.
We welcome enhancements and issue reports:
git checkout -b feature-name)Please adhere to existing code style and update documentation as needed.
We welcome contributors to propose and build enhancements to this system. Some of the upcoming or potential future features include:
Prompt Engineering Enhancements: Design more precise and instructive prompts using structured formats, few-shot examples, and task-specific templates to improve agent performance.
Multi-Query Support: Enable users to submit multiple queries simultaneously (e.g., "Tool Usage", "Task Types") for more efficient comparative analysis.
Expanded Agent Toolkit & Visualizations: Integrate additional agent tools (e.g., citation extractors, figure summarizers) and visual representations (charts, relationship graphs) to provide deeper analytical insights.
Advanced UI/UX Overhaul: Build a more responsive and intuitive user interface with enhanced interactivity, visualization panels, and accessibility features.
LLM Fine-Tuning Integration: Incorporate fine-tuned or domain-adapted LLMs for improved accuracy in extraction, summarization, and reasoning tasks.
Feedback & Evaluation Mechanisms: Implement user rating and feedback forms for each response to continuously fine-tune performance and relevance.
Contributors are encouraged to fork the repository, submit pull requests, or open discussions for feature suggestions and design proposals. For bug reports or feature requests, open an issue. For general questions or share your thoughts, start a comment.
Licensed under the MIT License.
This work is part of the Agentic AI Developer Certification program by Ready Tensor. Special thanks to the Ready Tensor developer community for guidance and feedback.
