
⬅️ Previous - LLM Fine-Tuning Options
When you're building a chatbot, a RAG pipeline, or fine-tuning your own model — one question always comes first: Which LLM should you use?
In most projects, you can experiment with a few shortlisted models and compare their results. But fine-tuning is different. It’s expensive, time-consuming, and hard to undo. You can’t just “try five and see what happens.”
That’s why choosing the right base model is one of the most strategic decisions in any LLM workflow. Start with a model that already performs well on tasks like yours, fits your infrastructure, and has a license that matches your use case.
This lesson teaches you how to read benchmarks and leaderboards the right way — cutting through hype, interpreting results in context, and finding models that will actually work for your specific goals.
Your goal isn’t to chase the top-ranked model — it’s to choose the one that wins for your task, your constraints, and your system.
Whether you’re fine-tuning or just using an existing LLM through APIs, every project starts with a key decision: Which model should you use?
Open Hugging Face and search for “7B instruct models.” You’ll see dozens of results: Llama, Mistral, Qwen, Phi, and more. All roughly the same size, all instruction-tuned — but not all equal.
The answer isn’t “pick the one at the top of the leaderboard.” The right choice depends on two things:
Fine-tuning amplifies existing capabilities — it doesn’t create new ones. A model weak at reasoning or coding won’t magically become great at it just because you fine-tuned it. This lesson gives you a systematic two-step process for choosing models wisely:
(1) filter by infrastructure constraints, then
(2) use benchmarks to find models proven strong in your task domain.
When selecting an LLM for any project, follow this structure:
1. Check your infrastructure to decide parameter count
Assess your GPU memory and computing setup. That determines what model sizes are viable.
This step eliminates models that simply won’t fit your hardware — no matter how good they look on paper.
2. Use benchmarks to identify top performers for your task
Once you know your viable size range, compare models within it using benchmarks.
This two-step process ensures you’re not chasing hype or wasting compute — just making data-driven choices.
Model size is measured in parameters (1B, 7B, 13B, 70B). Your hardware dictates what’s realistic:
| Model Size | Inference Memory Needed | Works On |
|---|---|---|
| 1B–3B | ~3–10 GB | Consumer GPU (12–16GB), mobile devices |
| 7B–8B | ~18–20 GB | Professional GPU (24GB) |
| 13B–20B | ~32–36 GB | Enterprise GPU (40GB) or 2×24GB setup |
| 30B–70B | ~75–190 GB | Multi-GPU A100 setup |
Key insight: If you have a single 24GB GPU, 7B–13B models are your ceiling. That 70B model topping leaderboards? It’s irrelevant unless you have multi-GPU infrastructure.
Context length also matters:
RAG systems with 8–16k token contexts add 30–40% to memory needs. Long-document processing (32k+) can double them.
Quick rule of thumb:
(GPU memory × 0.75) ÷ context multiplier ÷ 2 = max model size in billions
Example: For a 24GB GPU with medium context (8k tokens):
(24 × 0.75) ÷ 1.3 ÷ 2 ≈ 7B
Golden rule: Start with the smallest model that meets your performance needs. A well-tuned 7B model often beats a poorly configured 70B one.
Now that you know your feasible size range, you can pick the model. Benchmarks are your map.
Key principle: Fine-tuning refines existing skills — it doesn’t invent new ones.
Choose models already strong in your target domain:
Benchmarks help you:
Let’s unpack how benchmarks and leaderboards actually work.
“Gemini just beat GPT-4 on MMLU!”
“LLaMA 3 tops Chatbot Arena!”
Headlines like these dominate the AI news cycle. But what do they really mean?
Benchmarks shape perception and guide engineering decisions. But they can mislead if taken at face value. This section explains how to interpret them and how to use them effectively.
At its core, a benchmark is a test. Models are given the same set of questions or tasks, their outputs are scored against reference answers, and results are compared.
But not all benchmarks are equal.
Some are static tests (e.g., MMLU, GSM8K) measuring reasoning or factuality.
Others rely on human preference — where evaluators judge which response feels more accurate or natural.
Each benchmark captures only part of a model’s ability. That’s why reading them in context matters.
Benchmarks come in many forms — reasoning, coding, math, truthfulness, safety, and more. New ones keep emerging for long context, tool use, and multimodal tasks.
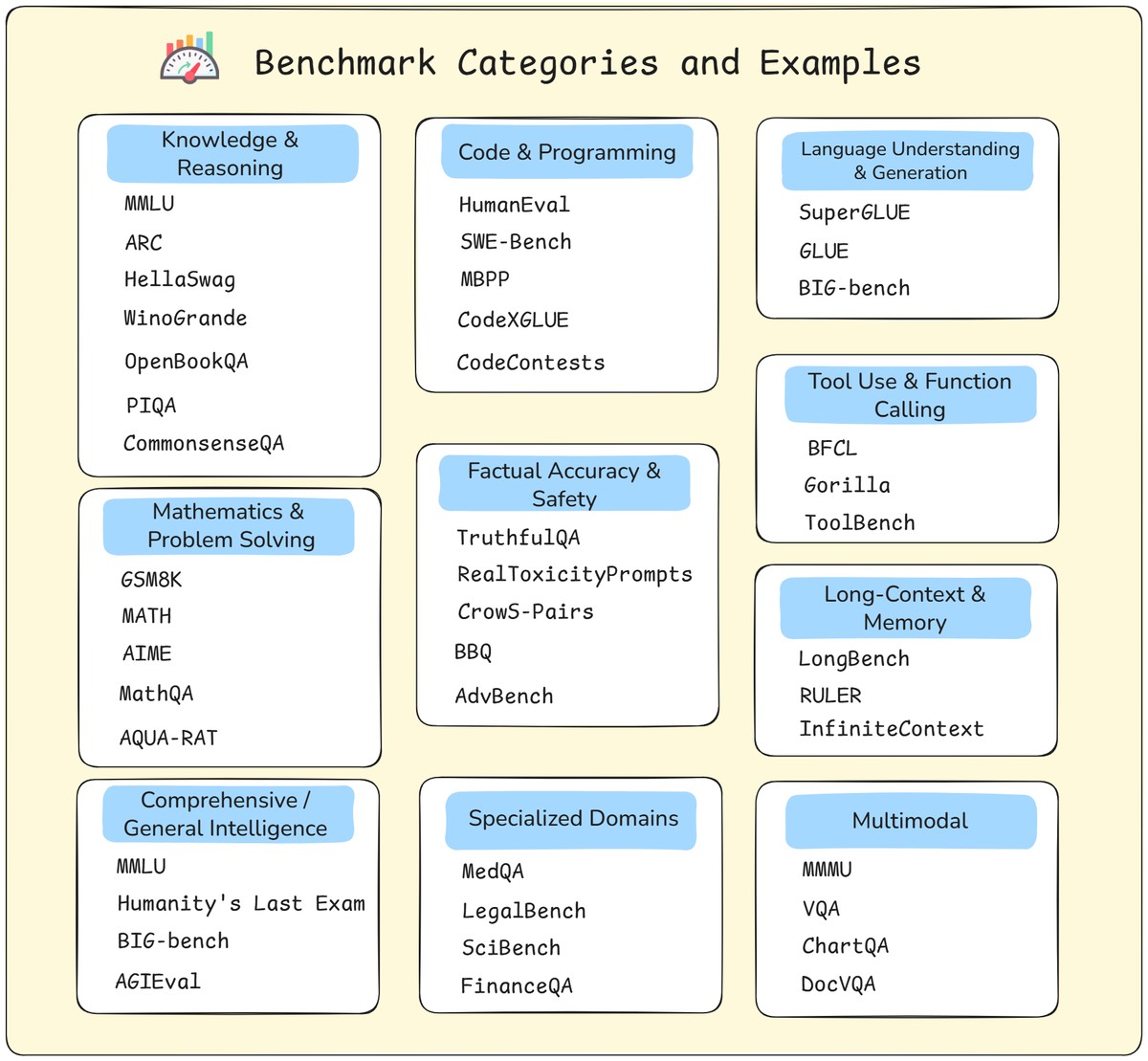
Three takeaways:
Let’s zoom into the most common ones.
These are the datasets you’ll see most often on leaderboards and in papers:
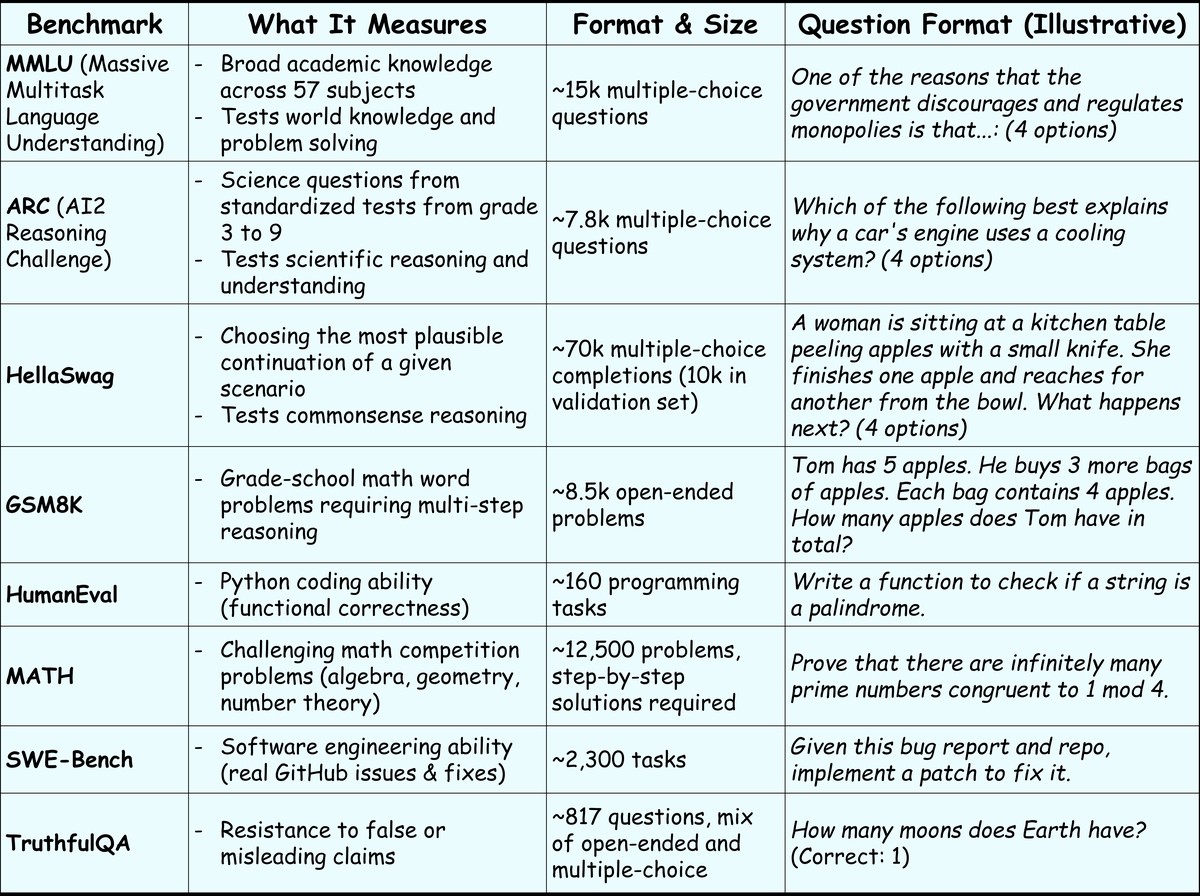
Two insights stand out:
Different formats = different skills.
Multiple choice tests (MMLU, ARC) assess recall.
Reasoning tasks (GSM8K, MATH) test logical chains.
Code synthesis (HumanEval, SWE-Bench) checks real-world competence.
Benchmarking costs compute.
Evaluating a 70B model on multiple datasets can take hours and GPUs.
Public leaderboards save you that effort.
Benchmarks yield scores. Leaderboards turn those scores into rankings — an easy-to-digest snapshot of model performance. But rankings can oversimplify the story.
Let’s look at the three major sources:
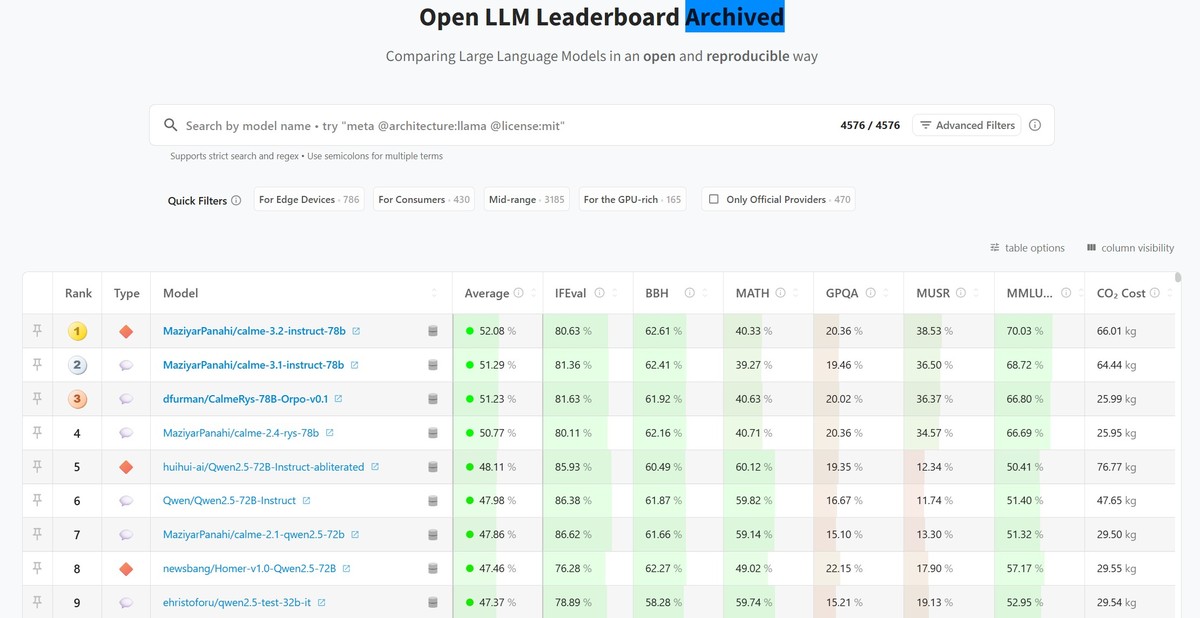
Hugging Face Open LLM Leaderboard (Aug. 26th, 2025)
In this video, you’ll learn how to navigate the Hugging Face leaderboard to filter, compare, and select the best LLM for your fine-tuning project based on performance and infrastructure needs.
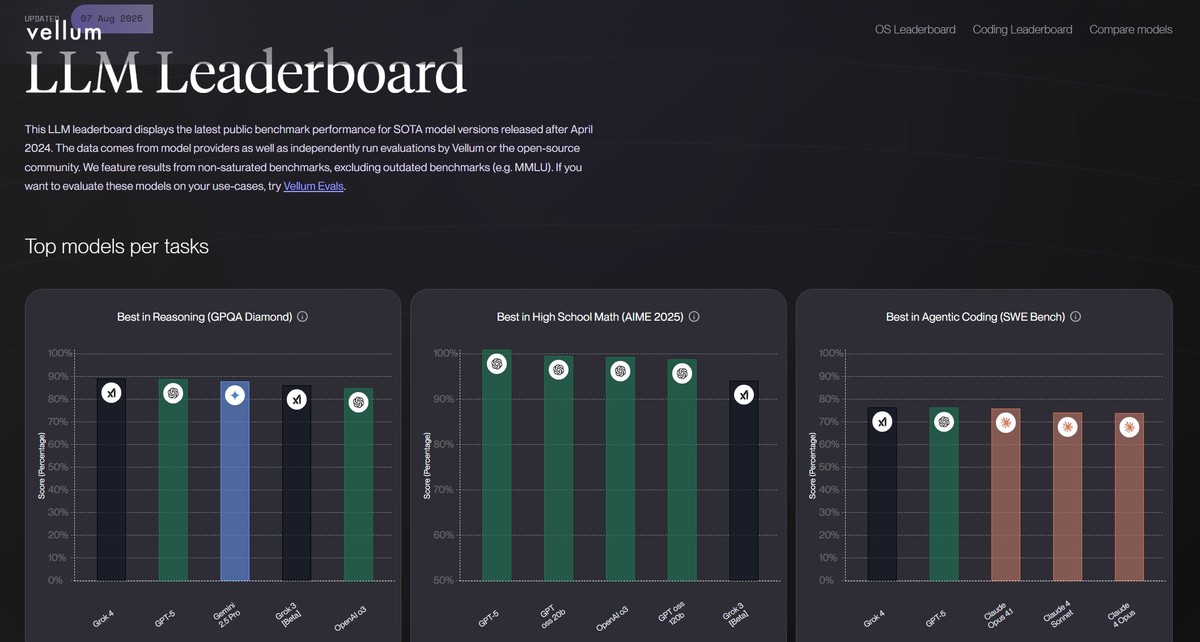
Vellum Public Leaderboard (Aug. 26th, 2025)
Vellum tracks state-of-the-art models on newer, less-saturated benchmarks. It also enables custom evaluations, so you can test models with your own prompts before committing to one. This bridges public data and real-world workflows.
In this video, you'll learn how to use the Vellum leaderboard to compare open-source LLMs and make informed decisions for fine-tuning based on performance, latency, and cost considerations.
Static benchmarks measure competence. Chatbot Arena measures how models feel to use.
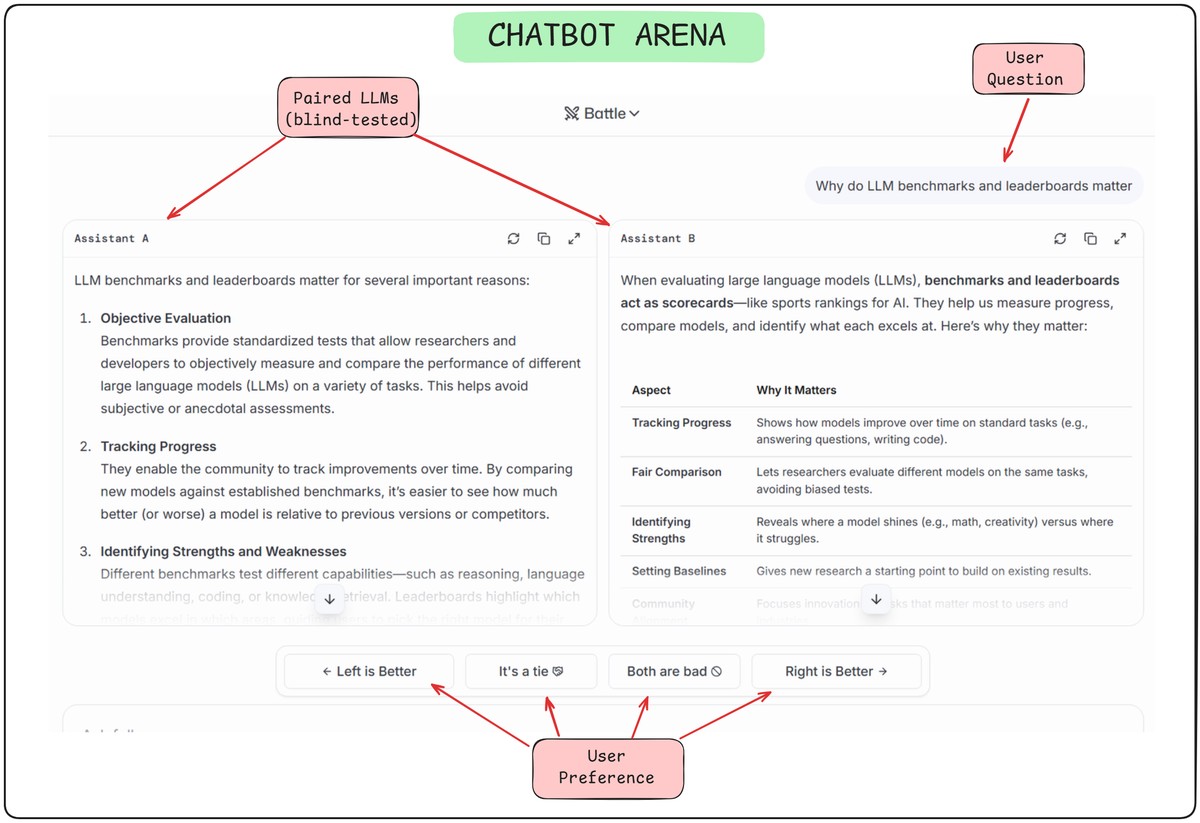
Run by LMSYS, it presents users with two anonymized model responses to the same prompt. Humans vote for the better one. Results form an Elo rating (like chess). Over time, thousands of votes yield a live, human-driven ranking.
Watch this video to learn how to use Chatbot Arena to compare LLMs based on their responses to the same prompt, allowing you to evaluate models not just on their benchmarks, but on how they actually perform in a conversational setting.
Why it matters:
In short:
Leaderboards are powerful tools — but only if you know how to interpret them. It’s easy to get dazzled by a top-ranked model or misled by tiny score differences.
Instead of treating them like a race, think of them as filters that help you shortlist candidates worth deeper evaluation.
Here’s how to use them effectively:
Start with overall scores — but dig deeper.
The average score gives a quick sense of general capability. But the breakdown by benchmark reveals where a model actually shines.
Example: a model strong in reasoning but weak on TruthfulQA might not be ideal for customer support systems.
Consider deployment realities.
Model size, latency, and context length affect practical usability far more than a one-point bump in MMLU.
Check licensing and access.
Can you actually use it? Is it open-weight or API-only? Some models forbid commercial deployment.
Run your own evaluations.
Always test leaderboard favorites on your actual use case before committing resources.
Even with careful reading, leaderboards can mislead. Keep these cautions in mind:
The Benchmark-to-Reality Gap:
Numbers don’t capture tone, clarity, or how well a model integrates into a workflow.
Benchmark Overfitting:
Some models are tuned specifically to ace tests without improving real-world behavior.
Unmeasured Variables:
Latency, memory footprint, and cost-per-token are rarely reflected in leaderboard scores.
Tiny Deltas Aren’t Meaningful:
A 0.5% change is often noise, not progress. Avoid chasing hype around microscopic differences.
Used thoughtfully, leaderboards point you toward promising options. Used blindly, they’ll send you chasing hype instead of results.
You’re building a customer support assistant.
The top model on the Hugging Face leaderboard is a 70B system — but it’s too large for your infrastructure and weak on TruthfulQA.
Instead, you find a 13B model ranked slightly lower overall but stronger in truthfulness and instruction-following. After testing it on your own documents, it meets your accuracy and latency goals — at a fraction of the cost.
👉 The best model isn’t always #1 — it’s the one that fits your constraints and your task.
Benchmarks and leaderboards help you find strong base models. But production success depends on far more than leaderboard rankings.
Prompt engineering matters.
The same model can perform poorly or brilliantly depending on how you structure instructions and constraints.
Grounding matters.
Retrieval-Augmented Generation (RAG) pipelines can make a smaller model outperform a larger one by anchoring it to the right knowledge.
System design matters.
Reflection loops, supervisor–worker architectures, and error recovery strategies often determine real-world reliability.
Engineering quality matters.
Monitoring, safety, and optimization turn a model into a robust product.
The industry is moving beyond static benchmarks toward system-level evaluation, measuring:
Even the strongest LLM can fail in a weak system, while a smaller one can excel in a well-engineered setup.
👉 Key takeaway: Don’t chase leaderboard glory — build systems that win in practice.
You now have a structured framework for choosing LLMs — whether you’re fine-tuning or deploying out of the box.
In the rest of this week, you’ll put this knowledge into practice.
We’ll show you how to reproduce a model’s benchmark scores from a public leaderboard — choosing one from the Hugging Face Open LLM Leaderboard as our example.
To do that, you’ll first learn how to use Google Colab, a zero-setup, browser-based environment with GPU access that’s perfect for this exercise.
Then, you’ll walk through the steps to run and reproduce a real benchmark — your first coding exercise in this program, and a valuable one!
Let’s keep building.
⬅️ Previous - LLM Fine-Tuning Options



