
⬅️ Previous - Using Google Colab
➡️ Next - LLM Fine-Tuning Foundations
In the last lesson, you learned how to interpret leaderboards and compare model performance.
Now, let’s do a quick, practical exercise: reproduce one of those benchmarks yourself.
You’ll run an official Hugging Face leaderboard task inside Google Colab, using the open-source lm-evaluation-harness.
In the last lesson, you learned how to interpret leaderboard results — understanding what each benchmark measures and how to pick models that fit your goals.
Now, it’s time to get hands-on.
We’ll reproduce a real benchmark from the Hugging Face Open LLM Leaderboard to see how those scores are actually computed.
For this exercise, we’ll focus on tinyGSM8K — a fast, lightweight benchmark that measures Math capabilities.
To run this benchmark, we’ll use lm-evaluation-harness, the same open-source tool that Hugging Face uses behind the scenes for leaderboard evaluations.
It makes benchmarking transparent, consistent, and reproducible — so you can verify published results or evaluate your own fine-tuned models with a single command.
In this video, you’ll learn how to take your model and run it through an official Hugging Face leaderboard benchmark to measure its performance on a high-level math reasoning task using GSM8K.
Start by opening a new Colab notebook and connecting to a GPU runtime:
Runtime → Change runtime type → GPU.
Then install the evaluation framework:
! pip install lm_eval langdetect -q ! pip install git+https://github.com/felipemaiapolo/tinyBenchmarks
Verify it installed correctly:
!lm_eval --help
You’re ready to evaluate models exactly like the Hugging Face leaderboard does.
You can test any model hosted on Hugging Face Hub.
For this exercise, pick a small instruct-tuned model such as:
meta-llama/Llama-3.2-1B-Instruct
and a lightweight benchmark task like tinyGSM8K (a math dataset).
Use the command-line interface for a quick test:
!lm_eval --model hf \ --model_args pretrained=meta-llama/Llama-3.2-1B-Instruct \ --tasks tinyGSM8K \ --device auto \ --batch_size auto
This command:
Compare the final score with the Hugging Face leaderboard — your result should match closely.
To integrate evaluation into fine-tuning or research workflows, use the Python API:
from lm_eval import evaluator from joblib import dump results = evaluator.simple_evaluate( model="hf", model_args="pretrained=meta-llama/Llama-3.2-1B-Instruct,parallelize=True,trust_remote_code=True", tasks=["tinyGSM8K"], device="cuda", batch_size="auto" ) print(results) dump(results, "results.joblib")
This lets you:
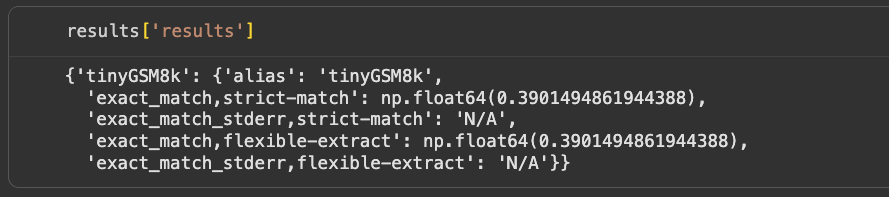
The output includes:
The model scored about 39% accuracy on the tinyGSM8k benchmark. The strict metric counts only exact matches, while the flexible metric allows small variations like formatting differences. Both produced the same score, meaning the model’s answers aligned with the expected ones about four out of ten times. The stderr (standard error) value is null because it wasn’t computed, but it can be enabled with the --bootstrap_iters flag (for example, --bootstrap_iters 1000). This uses bootstrap resampling, a statistical method that repeatedly samples subsets of the evaluation data to estimate how much the reported score might vary if the test were repeated on different examples.
Question: Rory orders 2 subs for $7.50 each, 2 bags of chips for $1.50 each and 2 cookies for $1.00 each for delivery. There’s a 20% delivery fee added at check out and she wants to add a $5.00 tip. What will her delivery order cost? True Answer: 2 subs are $7.50 each so that’s 2*7.50 = $<<2*7.5=15.00>>15.00 2 bags of chips are $1.50 each so that’s 2*1.50 = $<<2*1.50=3.00>>3.00 2 cookies are $1.00 each so that’s 2*1 = $<<2*1=2.00>>2.00 Her delivery order will be 15+3+2= $<<15+3+2=20.00>>20.00 There’s a 20% delivery fee on the $20.00 which adds .20*20 = $4.00 to her bill The delivery order is $20.00, there’s a $4.00 delivery fee and she adds a $5.00 tip for a total of 20+4+5 = $<<20+4+5=29.00>>29.00 #### 29 LLM Answer: Rory will spend $7.50 x 2 = $15.00 on subs. She will spend $1.50 x 2 = $3.00 on chips. She will spend $1.00 x 2 = $2.00 on cookies. So, the total cost of the subs, chips, and cookies is $15.00 + $3.00 + $2.00 = $20.00. The delivery fee is 20% of $20.00, which is 0.20 x $20.00 = $4.00. The tip is $5.00. Therefore, the total cost of the order is $20.00 + $4.00 + $5.00 = $29.00. #### 29
When you start fine-tuning in later modules, you’ll rerun this process to check whether your model’s scores actually improved.
That’s it — you’ve completed Week 1!
You now know how to:
Next week, we’ll build the foundation for fine-tuning.
You’ll learn how language models behave as classification systems, how tokenization and padding work, how to prepare datasets, and how techniques like LoRA and QLoRA make fine-tuning efficient.
Get ready — next week we start putting together the building blocks for LLM fine-tuning.
⬅️ Previous - Using Google Colab
➡️ Next - LLM Fine-Tuning Foundations


