
⬅️ Previous - The LLM Landscape
➡️ Next - LLM Fine-Tuning Options
You’ve learned how LLMs differ by architecture and ecosystem — now comes the practical question every engineer faces:
Should you fine-tune at all?
Fine-tuning can be powerful, but it’s not always necessary.
Sometimes great results come from clever prompting or connecting your model to external data with RAG. Other times, only training on your own data will deliver the precision and consistency you need.
This lesson helps you tell those situations apart — understanding when fine-tuning is worth the cost, when lighter approaches are enough, and how all three methods can work together to build production-ready systems.
When you start customizing an LLM for your use case, you have three main tools in your kit:
Each one builds on the other. Think of them less like competing options and more like layers:
Prompting shapes the output.
RAG expands what the model knows.
Fine-tuning changes what the model is.
Let’s look at what each approach actually does — and when to reach for it.
Prompt engineering is the simplest and fastest way to customize an LLM.
You craft instructions, examples, or formats that nudge the model toward the behavior you want.
Say you’re building a customer-support assistant:
You are a helpful, polite support agent for TechFlow. Always respond in two short paragraphs. If you don’t know the answer, politely say so.
With just this prompt, GPT-4 or Mistral can behave like a customer service agent — no training, no data collection, no GPUs.
Prompting is where every project begins because:
But prompting has limits. It’s like telling a brilliant intern exactly what to do every time — useful, but repetitive.
Each interaction resets the model’s memory, and you’re always re-supplying context within the input window. That’s where RAG steps in.
Retrieval-Augmented Generation connects your LLM to external knowledge — documents, databases, or internal systems.
Instead of teaching the model new facts through training, you feed it the right information at runtime.
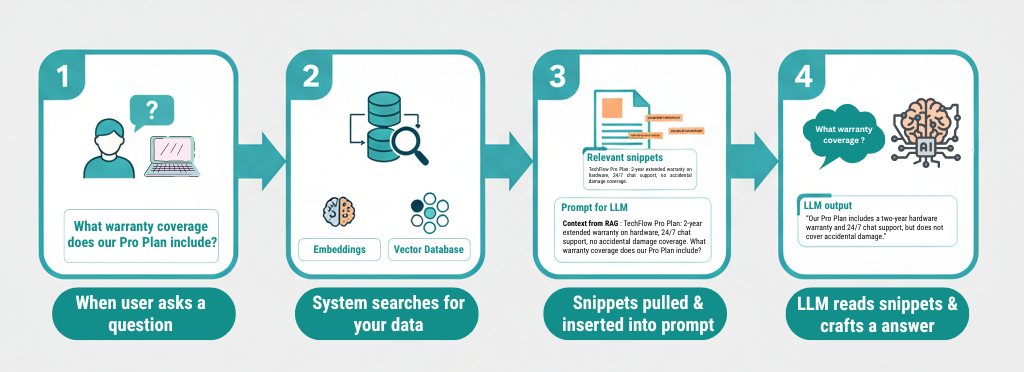
Here’s the flow:
Example:
User: "What warranty coverage does our Pro Plan include?" RAG provides: "TechFlow Pro Plan: 2-year extended warranty on hardware, 24/7 chat support, no accidental damage coverage." LLM output: "Our Pro Plan includes a two-year hardware warranty and 24/7 chat support, but does not cover accidental damage."
The model never memorized this policy; it read it dynamically.
That’s the magic of RAG — your data stays fresh, private, and easy to update.
When to use RAG:
But RAG doesn’t make the model smarter — it only feeds it context.
If your model struggles to interpret the information or follow domain conventions, that’s when fine-tuning becomes necessary.
Fine-tuning means teaching the model new behaviors by training it on your own dataset.
It’s not just giving examples — it’s updating the model’s internal weights so the behavior becomes permanent.
Think of it like moving from “telling” to “teaching.”
You’d fine-tune when:
Example:
A general model might need elaborate prompting to answer medical questions safely. Or, you may use RAG to provide the right context.
But a fine-tuned version, trained on curated clinical data, can speak naturally and reliably in that domain — without having to re-feed examples or needing RAG for context.
Fine-tuning works best when you have at least a few hundred high-quality instruction–response pairs and clear evaluation goals.
Otherwise, you risk spending time and compute to make the model slightly worse than before.
Fine-tuning doesn't make a bad dataset better — it makes its flaws permanent.
Even the most powerful model can't learn useful behavior from inconsistent, noisy, or poorly labeled data.
If your training examples are ambiguous, repetitive, or off-task, your fine-tuned model will reflect those same weaknesses — just faster and more confidently.
And here's the costly part: LLMs can't unlearn what they've been trained on. If you fine-tune on flawed data, there's no "undo" button. You can't patch or correct specific behaviors easily. You'd need to start the fine-tuning process over from scratch with clean data.
This makes upfront data quality your most important investment.
So what counts as quality data?
You'll explore this in depth next week when we cover dataset collection and preparation.
For now, remember this rule of thumb: Fine-tuning amplifies what's already there. So start with data worth amplifying.
Let’s make it practical.
Imagine three engineers facing different challenges:
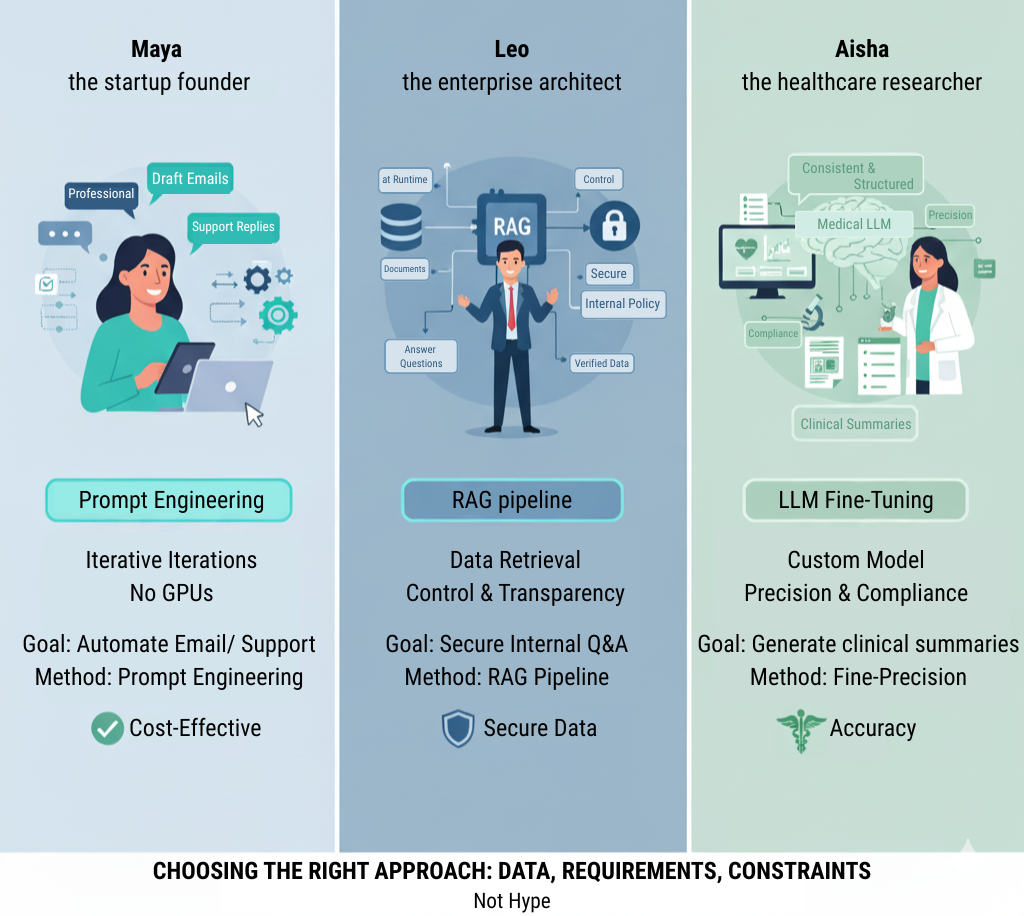
1. Maya — the startup founder.
She needs an AI that drafts emails and support replies for her SaaS tool.
She starts with prompt engineering — iterating instructions until responses sound professional.
That’s enough. No GPUs required.
2. Leo — the enterprise architect.
His team wants to answer internal policy questions securely.
He builds a RAG pipeline over company documents so the model can fetch verified data at runtime.
No retraining, but lots of control and transparency.
3. Aisha — the healthcare researcher.
Her lab needs a model that generates consistent, structured clinical summaries.
Prompts and RAG aren’t enough; she fine-tunes a medical LLM using labeled case notes, ensuring compliance and precision.
Three different goals. Three different approaches.
The right choice depends not on hype — but on data, requirements, and constraints.
Real-world systems rarely pick just one.
The most effective pipelines combine all three approaches:
Example:
A law firm might fine-tune an open-weight model on its legal corpus, use RAG to fetch relevant clauses, and apply prompts to shape the final writing style.
It’s not “either/or.” It’s a layered design:
each method strengthens the others.
Fine-tuning sounds impressive, but it’s often overused.
Here’s when you should pause and reconsider:
If your data fits in the context window and your results are already good — fine-tuning probably isn't worth it. Save that GPU time for when you've hit the ceiling of what prompting and RAG can do.
You now understand the three major ways to customize an LLM - and when each one makes sense.
In the next lesson, we'll tackle the practical question that comes right after deciding to fine-tune:
Where should you actually run the training?
We'll explore your options for fine-tuning infrastructure, from local setups to cloud platforms, and help you choose the right environment for your project.
That's where we move from deciding to doing.
⬅️ Previous - The LLM Landscape
➡️ Next - LLM Fine-Tuning Options


