⬅️ Previous Readiness for LLM Engineering
This program is designed to help you master the full lifecycle of large language models — from fine-tuning to production deployment.
This lesson shows you how everything fits together: a two-module, unit-based learning path with hands-on projects that lead to portfolio-grade work and professional certification.
The program is divided into two modules.
Module 1 focuses on fine-tuning and optimizing large language models, while Module 2 focuses on deployment, inference, and production-grade engineering.
The program is fully self-paced and organized into 10 instructional units, followed by two capstone projects.
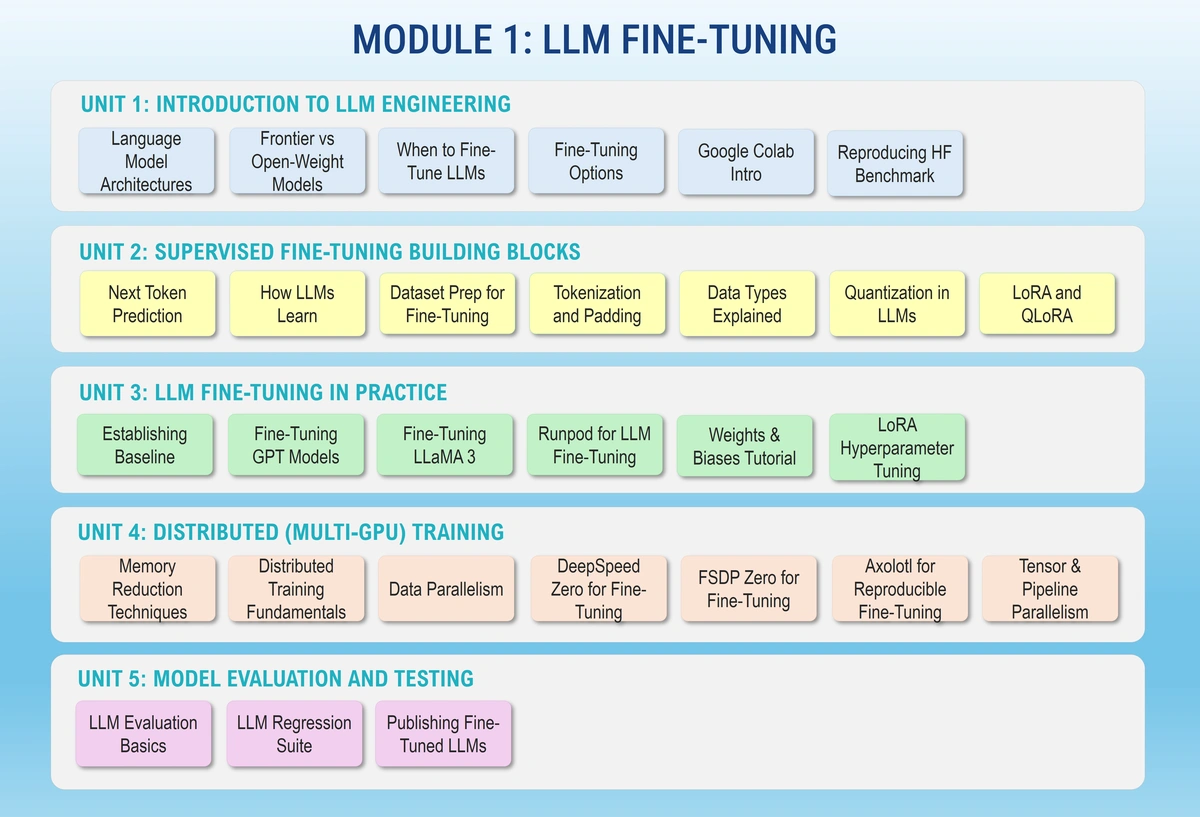
In this module, you’ll learn how to adapt open-source foundation models for specific tasks and domains using modern fine-tuning workflows.
You’ll work with Hugging Face, LoRA/QLoRA, distributed training frameworks, and evaluation tools to understand how training choices affect model quality, cost, and performance.
The module concludes with a fine-tuning capstone project, where you deliver a fully evaluated, optimized, and quantized model with supporting documentation.
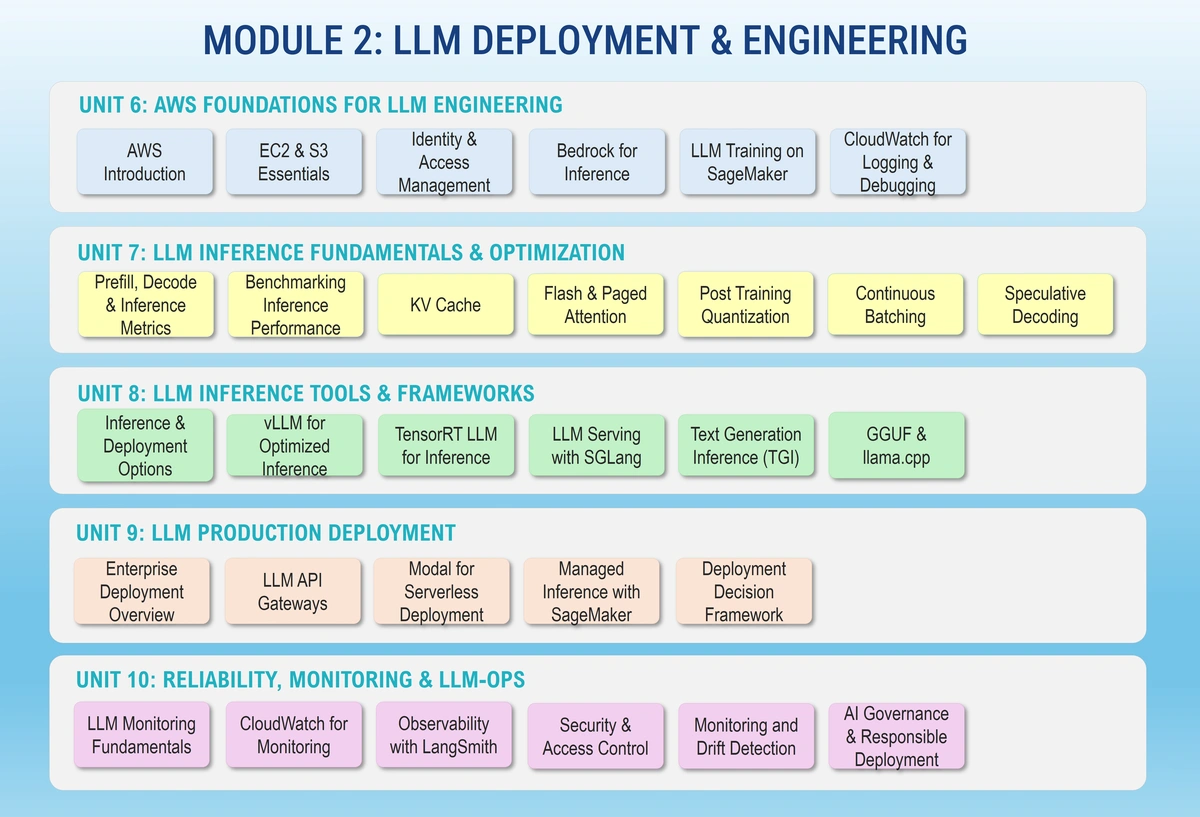
This module focuses on running LLMs reliably in real production environments.
You’ll learn how inference works, how to optimize latency and throughput, and how to deploy models using tools such as vLLM, Modal, SageMaker, and Bedrock. You’ll also cover monitoring, observability, security, and operational best practices.
The module concludes with a production deployment capstone project, where you build and operate an end-to-end LLM system with live endpoints and monitoring.
Below is the structure of the program, organized by module and instructional unit:
| Module | Unit | Focus Area | Key Themes |
|---|---|---|---|
| Module 1 | 1 | Introduction to LLM Engineering | Model architectures, LLM landscape, fine-tuning vs RAG. |
| Module 1 | 2 | Fine-Tuning Building Blocks | Tokenization, datasets, data types, LoRA & QLoRA. |
| Module 1 | 3 | LLM Fine-Tuning in Practice | End-to-end training runs and experiment tracking. |
| Module 1 | 4 | Scaling LLM Training | Memory optimization, distributed training, multi-GPU workflows. |
| Module 1 | 5 | Evaluation & Model Quality | Benchmarking, evaluation suites, publishing and versioning models. |
| Module 2 | 6 | AWS Foundations for LLM Engineering | SageMaker, Bedrock, IAM, monitoring, and cost management. |
| Module 2 | 7 | LLM Inference Fundamentals | Inference mechanics, KV cache, quantization, performance tuning. |
| Module 2 | 8 | Inference Frameworks & Tooling | vLLM, TGI, SGLang, and benchmarking workflows. |
| Module 2 | 9 | Production Deployment Strategies | Self-managed, serverless, and managed deployment patterns. |
| Module 2 | 10 | Monitoring, Reliability & Governance | Observability, security, drift detection, and operational handoff. |
This program is fully self-paced and organized by instructional units, not schedules or deadlines.
You can move faster, slow down, or revisit units based on your background and goals.
Your progress is determined by what you build and submit, not how long you take.
Certification is earned by completing both capstone projects and meeting the evaluation rubric.
Units define learning structure, not timelines.
You control the depth, order, and pace of your learning.
You’ll gain hands-on experience with the same tools modern AI teams rely on:
Everything you learn leads to two major deliverables:
These projects form your professional portfolio and are the basis for certification.
This roadmap is meant to help you build real, hands-on capability — not just theoretical understanding.
As you move through the lessons, you’ll learn to fine-tune, evaluate, and deploy large language models using the same tools production teams use every day.
When you’re ready, continue to Module 1: LLM Fine-Tuning & Optimization to begin your first phase of hands-on work.
🏠 Home - All Lessons
➡️ Next - How to Succeed in This Program



