
⬅️ Previous - Module 1 Project Description
You’re here to fine-tune—awesome. Before we turn any knobs, let’s answer a simple question: fine-tune what?
“An LLM,” you say. Great. But what exactly is a large language model?
This lesson gives you a clear mental model: the three ways language models are built, what each is good at, and which one powers tools like ChatGPT, Claude, and Gemini.
By the end, you’ll recognize the three families of language models at a glance—Encoder-Only (the analyst), Encoder–Decoder (the translator), and Decoder-Only (the author)—and you’ll see why the Decoder-only architecture that powers today’s assistants is the one we’ll master in this program.
When you chat with ChatGPT, Claude, or Gemini, you’re interacting with a language model—a machine learning system trained to generate high-quality, human-like text.
What’s interesting is that while these assistants come from different companies, they all share the same core architecture for language generation.
But that architecture isn’t the only kind out there when it comes to language modeling.
In fact, the field of language models includes multiple architectures, each designed with a different goal in mind. Some models specialize in understanding and labeling text. Others are great at translating or summarizing. And then there are those, like ChatGPT, that are built to generate fluent, multi-turn responses.
In this lesson, you’ll get a clear picture of each one—and see why the architecture behind modern assistants has become the go-to choice for real-world applications like chatbots, coding assistants, and task automation.
We’ll start with the common foundation they all share: the Transformer.
All modern language models—whether used for search, chat, translation, or summarization—are built on the Transformer, introduced in 2017 by Google in the paper Attention Is All You Need.
What made it revolutionary? The Transformer's self-attention mechanism processes all tokens in parallel—no sequential bottleneck. This parallelization enabled training on trillions of tokens at scale, which is what gave us modern LLMs. That’s how it knows that in the sentence:
“The bank was steep,”
the word bank relates to a river, not money.
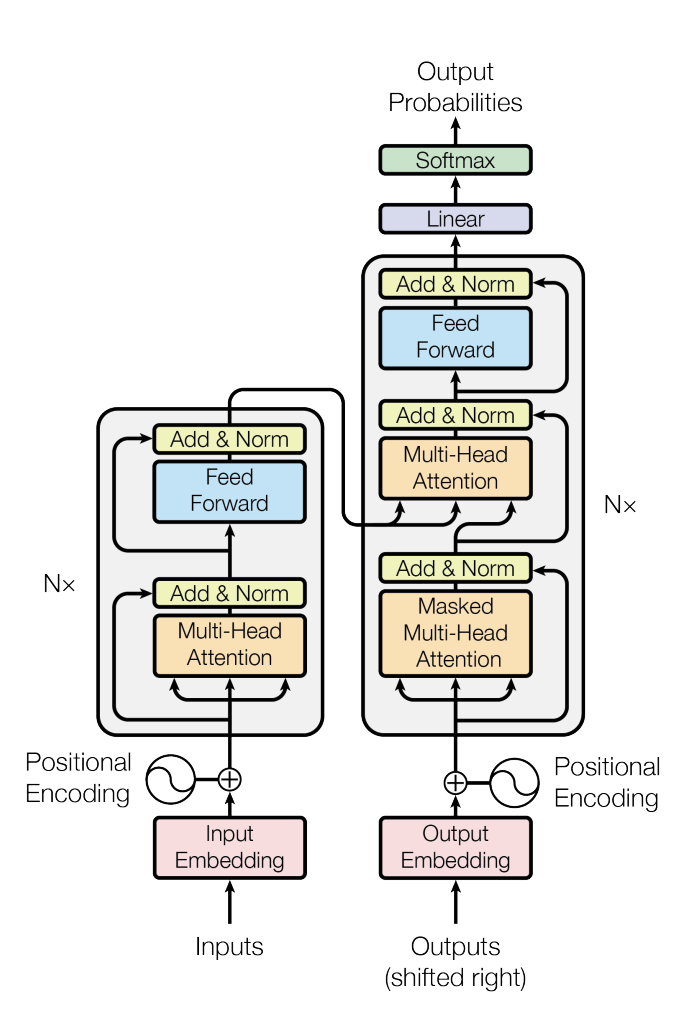
The original Transformer has two parts:
This full encoder–decoder setup was designed for machine translation: the encoder understands a sentence in one language, and the decoder writes it in another.
Researchers soon realized you don’t always need both parts. Depending on the task, you can build models using just the encoder, just the decoder, or both. That gave rise to the three main architecture types:
Let’s break each one down.
In this video, we walk through the three core Transformer architectures — encoder–decoder, encoder-only, and decoder-only — using real examples from T5, BERT, and GPT-2.
You’ll see how each model is structured, what it’s best at, and why decoder-only architectures have become the standard for modern LLMs like ChatGPT and Claude.
This is the original full Transformer. It uses the encoder to fully understand an input, then the decoder to transform it into something new.
Great for: translation, summarization, paraphrasing, and other “X → Y” tasks.
Example:
Task: Translate and summarize Input: A long English document about quantum computing Output: A short French summary
You’ll see models like T5, BART, and PEGASUS in this family.
Why we don’t focus on this in the program: Decoder-only models now perform many of these tasks nearly as well, while also enabling chat, coding, and general-purpose generation.
These models use just the encoder. They look at the full input simultaneously and build a deep understanding—but they don’t generate fluent text.
Great for: classification, NER, topic detection, semantic similarity, and embeddings.
Example:
Task: Classify support ticket Input: "My order hasn't arrived and it's been 2 weeks" Output: Category = "Shipping Issue", Urgency = "High"
You’ll see models like BERT, RoBERTa, ALBERT, and DistilBERT here.
Why we don’t focus on this in the program: Encoder-only models are excellent for understanding tasks—but not for generation. You can’t fine-tune BERT into a chatbot.
Decoder-only models have become the dominant architecture for modern LLMs. They generate text one token at a time, left to right—making them ideal for instruction-following, chat, and creative writing.
Great for: chat assistants, code generation, email drafting, creative writing, and more.
Example:
Task: Write a polite email Input: "Decline a meeting request" Output: "Dear [Name], Thank you for the invitation... [polite decline message]"
These models are autoregressive: they generate the next word based on everything written so far. Despite only seeing prior context, they produce fluent, coherent, and goal-driven responses.
An autoregressive model predicts the next element in a sequence using previous elements as input. In LLMs like GPT, this means generating text one token at a time, where each predicted word depends on all preceding words. In forecasting, it predicts future values (like stock prices) based on historical data points. The key idea: each output becomes part of the input for the next prediction.
You’ve already used models from this family:
Why this program focuses here: This is the architecture behind nearly every production assistant today. It’s the most versatile, scalable, and well-supported for real-world applications—and it’s where modern LLM engineering happens.
When we say models like ChatGPT, Claude, or Gemini use a decoder-only architecture, we’re talking about their core language model—the part that generates text.
These assistants are full products built on top of that core. They include other components like memory systems, retrieval tools, APIs, moderation layers, guardrails, and orchestration logic.
This program focuses on the language model layer itself: how to fine-tune and deploy it for your own use cases.
The following table compares the three architectures:
| Aspect | Encoder-Decoder | Encoder-Only | Decoder-Only (GPT-Style) |
|---|---|---|---|
| Text Processing | Both (encoder bidirectional, decoder unidirectional) | Bidirectional (sees full context) | Unidirectional (left-to-right) |
| Primary Strength | Sequence transformation | Understanding & classification | Generation & conversation |
| Best For | Translation, summarization | Classification, NER, embeddings | Chat, code, creative writing |
| Can Generate Text? | Yes, but focused on transformation | No (or poorly) | Yes, fluently |
| Examples | T5, BART, Original Transformer | BERT, RoBERTa | GPT, LLaMA, Claude, Mistral |
| This Program | Not covered | Not covered | ✅ Primary focus |
In this video, we tackle two critical questions about the transformer architecture that powers all modern LLMs: What makes it so powerful? And where does it fall short?
Understanding these strengths and limitations will help you make better decisions as you fine-tune and deploy models throughout this program.
The modern LLM landscape has decisively shifted toward decoder-only models—and understanding why is key to understanding what you’ll be working with throughout this program.
A single decoder-only model can act as:
Tasks that were once the domain of other architectures—like sentiment classification (encoder-only) or machine translation (encoder–decoder)—are now routinely handled by decoder-only models. You’ve likely experienced this firsthand using ChatGPT to summarize, translate, or interpret text.
This flexibility allows organizations to rely on a single model architecture across dozens of use cases—without managing multiple, specialized systems.
Decoder-only models scale extremely well. Trained on trillions of tokens, they continue to improve as model size and data grow. This predictable scaling has made them the architecture of choice for cutting-edge research and enterprise deployment.
From Hugging Face Transformers and PEFT to DeepSpeed, Axolotl, and countless community tools, the entire open-source ecosystem has consolidated around decoder-only models. When you fine-tune, evaluate, or deploy LLMs in the real world, this is the architecture you're working with.
Bottom line:
When most people say “LLM” today, they mean a decoder-only model.
And that’s exactly where this certification program focuses.
You’ll learn to fine-tune these models for your own use cases—whether you’re building a customer service assistant, a domain-specific chatbot, a task automation agent, or something entirely new.
This is the architecture that powers modern AI—and by the end of this program, you’ll know how to make it your own.
You now have a clear mental model of the three Transformer architectures—and why decoder-only models dominate today’s AI landscape.
These are the models that power ChatGPT, Claude, and nearly every LLM-powered assistant in production. They’re also the models you’ll be fine-tuning, evaluating, and deploying throughout this program.
In the next lesson, we’ll zoom in on the broader LLM ecosystem:
It’ll give you the context to make smart choices as an LLM engineer—and help you see how the models you’re about to build fit into the bigger picture.
Let’s keep going.
⬅️ Previous - Module 1 Project Description

