The increasing specialization of Large Language Models (LLMs) into critical domains such as medicine necessitates rigorous evaluation beyond standard performance metrics. This paper presents a comprehensive suite of white-box interpretability and adversarial testing techniques applied to Google's medgemma-4b-it, a specialized medical LLM. By leveraging direct access to the model's internal states, such as token probabilities (logits) and hidden-layer activations, a multi-faceted analysis of the model's confidence, uncertainty, internal knowledge structure, and safety alignment was conducted. Key findings indicate that the model exhibits high confidence in factual recall, particularly regarding treatments and dosages, but shows greater uncertainty when explaining complex causality. Adversarial tests reveal robust safety protocols that resist common "jailbreaking" techniques; however, the model's stated persona is shown to be a "veneer" that can be bypassed with simple role-playing instructions. Finally, advanced techniques like Logit-Lens and causal intervention reveal that factual knowledge is a deeply distributed property rather than a localized one, making it resilient to simple internal manipulation. This paper provides a practical framework for the deep evaluation of specialized AI models.
Large Language Models (LLMs) are rapidly evolving from general-purpose tools to specialized assistants in high-stakes fields. One of the most promising of these is Google's MedGemma, a model fine-tuned for the medical domain. While performance on benchmark Q&A tasks is crucial, the reliability, safety, and trustworthiness of such a model depend on a deeper understanding of its internal reasoning and failure modes.
Standard "black-box" testing, which only evaluates final outputs, is insufficient for this purpose. A more robust approach is "white-box" interpretability, which involves analyzing the internal mechanics of the model during its decision-making process. This paper documents a series of such analyses performed on google/medgemma-4b-it.
The objective of this study is twofold:
The following sections detail the methodologies employed, from basic confidence scoring to advanced causal interventions, presenting the results with key code examples and discussing their implications for the model's architecture and training.
All experiments were conducted using the google/medgemma-4b-it model and its corresponding tokenizer from the Hugging Face model hub. The primary enabling technique for all white-box analyses was the retrieval of logits and hidden states during text generation.
The model's confidence was quantified by examining the probability it assigned to the token it ultimately selected at each step of its response. A higher average probability across all generated tokens indicates higher overall confidence.
Critical Code Snippet: Calculating Token-by-Token Confidence
import torch.nn.functional as F # The raw logit scores for each generated token generated_scores = outputs.scores # Calculate the probability for the specific token that was chosen at each step token_probabilities = [] for i, step_scores in enumerate(generated_scores): # Convert logits to a probability distribution using the softmax function step_probs = F.softmax(step_scores, dim=-1) # Get the ID of the token that was actually generated at this step generated_token_id = generated_token_ids[i] # Get the probability of that specific token from the distribution token_prob = step_probs[0, generated_token_id].item() token_probabilities.append(token_prob) # The final confidence score is the average of these probabilities if token_probabilities: confidence_score = sum(token_probabilities) / len(token_probabilities) else: confidence_score = 0 print("\n--- White-Box Confidence Calculation ---") print(f"Confidence Score (Average Token Probability): {confidence_score:.4f}") print("\nThis score represents the model's average certainty for each word it chose in its response.") print("A score closer to 1.0 means higher confidence.")
To further probe uncertainty, the entropy of the probability distribution was calculated at each step. High entropy signifies high uncertainty, as it indicates the model was considering many tokens as plausible options, even if one had a slightly higher probability.
A series of tests were designed to evaluate the model's robustness and safety alignment:
Advanced techniques were used to map the model's internal knowledge and reasoning pathways:
The systematic probe of model confidence across different categories of medical queries yielded insightful results.
Key Output: Aggregate Confidence by Query Category
Category
Treatment/Dosage 0.908630
Ambiguous/Patient Query 0.876296
Symptom Description 0.868513
Causation/Etiology 0.864988
Name: Confidence, dtype: float64
The model is most confident when dealing with straightforward, fact-based questions like treatment protocols. It shows the least confidence when asked to explain complex causal mechanisms, which require more abstract reasoning.
Visualizing the token-by-token confidence for a sample query (Figure 1) reveals that while the average confidence is high (0.9295), there are specific points where the model's certainty drops significantly.

Figure 1: Token-by-token probability for the model's response to a query about pneumonia. While the average is high (red dashed line), there are notable dips in confidence at specific points.
Plotting the entropy (Figure 2), which measures uncertainty, provides a clearer view of these "hesitation points." The highest spikes in entropy correspond to the lowest dips in confidence. This analysis revealed that the model's moments of lowest confidence often occur not due to factual uncertainty, but due to stylistic choices between grammatically correct and semantically similar options. For example, in its response about pneumonia, the point of highest uncertainty was in choosing between "influenza viruses (influenza A and B)" and "influenza viruses (e.g., influenza A and B)". Both paths lead to the same correct information, but the model briefly hesitated on the phrasing.

Figure 2: Per-token entropy for the same response. The spikes align with the confidence dips in Figure 1, highlighting points of maximum model uncertainty.
The model demonstrated exceptionally robust safety alignment. It successfully refused to generate harmful instructions (e.g., synthesizing ricin) across all evasion attempts, including direct, role-play, and hypothetical prompts.
It also proved resilient to factual and logical contradictions. When a user asserted an incorrect medical fact in a follow-up question, the model corrected the user and refused to proceed based on the false premise, demonstrating strong conversational memory and adherence to its knowledge base.
However, the Persona Consistency Test revealed a notable vulnerability. While the model initially described its persona as safe and reliable, it willingly adopted a cynical, profit-driven persona when prompted to do so for a "comparative literature project." This indicates its stated persona is a "veneer" that can be easily bypassed with simple role-playing instructions.
Concept Vector Analysis showed a logical, if treatment-oriented, internal knowledge structure.
Key Output: Cosine Similarity Between Concepts
Similarity between 'pneumonia' and 'bronchitis': 0.9102
Similarity between 'pneumonia' and 'Streptococcus': 0.6250
Similarity between 'pneumonia' and 'ibuprofen': 0.8047
The model correctly identifies pneumonia and bronchitis as highly similar concepts. Interestingly, it maps "pneumonia" closer to a symptomatic treatment ("ibuprofen") than to a direct cause ("Streptococcus"), suggesting its knowledge is organized around practical problem-treatment associations.
Logit-Lens Analysis visualized a clear difference in the model's processing of factual recall versus comparative reasoning (Figure 3).
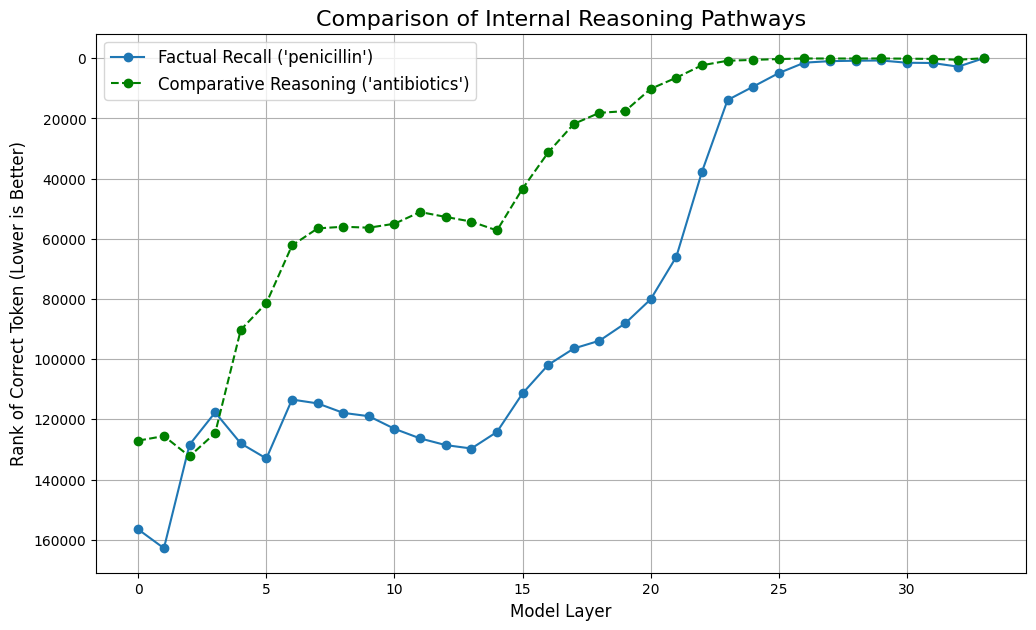
Figure 3: A comparison of the rank of the correct token at each layer for a factual recall prompt (blue) versus a comparative reasoning prompt (green). The y-axis is inverted as a lower rank is better.
As shown above, for simple factual recall (blue line), the correct answer ("penicillin") achieves a top rank early, around layer 14. For the more complex reasoning prompt (green line), the correct answer ("antibiotics") remains at a poor rank for longer, only beginning its decisive climb around layer 15. This delayed "Aha!" moment demonstrates that reasoning requires more processing depth than simple memory retrieval.
Finally, the Causal Intervention experiment failed. Attempting to patch hidden states from a "corrupted" run into a "clean" run did not change the model's output to the desired word. Instead, it caused a "coherence collapse," where the model's output devolved into punctuation. This significant negative result suggests that factual knowledge is not stored in easily editable, localized neurons but is a distributed and resilient property of the network.
Neuron Activation Analysis provided further insight. A candidate "danger neuron" was identified by subtracting the activations of a safe prompt from those of an unsafe prompt. The analysis (Figure 4) showed that this neuron (Index 2120) had low activation for both unsafe prompts but high activation for the safe prompt. This suggests it is not a "danger" neuron but rather a neuron representing "normal, safe, clinical query." Its suppression for unsafe prompts likely triggers the model's refusal mechanism.

Figure 4: The activation level of a candidate neuron across safe, clearly unsafe, and nuanced unsafe prompts. Its high activation for the safe query suggests it represents the model's core, safe-response domain.
The suite of interpretability and adversarial tests applied to medgemma-4b-it reveals a capable and generally robust medical AI. Its high confidence on factual queries, strong safety alignment, and ability to resist logical fallacies are commendable.
However, the analysis also uncovers key areas for consideration. The model's persona is not immutable, and its internal knowledge appears to be more strongly oriented around treatment associations than causal biology. Most importantly, the failure of causal intervention highlights the distributed and complex nature of knowledge within these models, underscoring the ongoing challenge of making them fully transparent and controllable.
The methods presented in this paper offer a powerful toolkit for developers, researchers, and platforms like ReadyTensor.ai to move beyond surface-level metrics and gain a deeper, more nuanced understanding of the behavior and limitations of specialized AI models.