Abstract
Vision-based perception systems are the foundation of self-driving vehicle technology, allowing real-time analysis and interpretation of the surrounding environment. Our proposed work investigates a hybrid strategy for integrating lane detection and object identification, with a focus on warning generation for impending collisions. Our algorithm detects objects using deep learning models such as YOLOv5, as well as a custom lane detection technique that includes curvature estimation. We have also incorporated traffic sign and signal recognition along with depth estimation to help you make better decisions. The built system has extensive detection and classification capabilities, paving the way for safer and more reliable autonomous navigation.
Objective
Our research proposes a comprehensive framework that combines lane detection with object recognition and collision warnings, utilizing cutting-edge deep learning models and real-time processing methods. Our aim is to add to the ongoing initiatives aimed at enhancing the safety and capabilities of autonomous vehicles, making them ready for real-world implementation.
Introduction
Recent developments in sensor technology, computer vision, and artificial intelligence have sparked a lot of interest in autonomous vehicles. These vehicles utilize a variety of sensory systems to comprehend their surroundings and navigate in a safe and efficient manner. In an effort to provide a safe, effective, and dependable transportation system, cameras and computer vision techniques—in particular, vision-based perception—have gained popularity as a means of distinguishing between objects, identifying road restrictions, and perceiving the full picture.
Camera model and calibration
Camera model and callibration are an important aspect of dealing with vision-based perception. With the advancement in cameras and their features, they now serve as primary sensors for the purpose of achieving accurate modelling and calibration, as these elements are crucial for dependable object detection, localization, and scene comprehension.
Object detection and tracking
Perception systems in autonomous vehicles depend on object identification and tracking to enable real-time observation and detection of things such as cars, pedestrians, and barriers. Tracking techniques like SORT, Deep SORT, and Kalman filters allow continuous surveillance across frames, maintaining object IDs and providing temporal context, while models like YOLO, Faster R-CNN, and SSD effectively classify items. This combination enables precise velocity estimation, distance measurement, and forecasting abilities, which are vital for secure navigation. Furthermore, techniques for sensor fusion that integrate cameras, LiDAR, and radar improve the detection and tracking effectiveness, ensuring dependability in dynamic or challenging conditions, including low-light situations or adverse weather.
Lane detection
In autonomous driving, lane detection is essential because it provides vital data for path planning and vehicle positioning. Techniques range from sophisticated deep learning methods like semantic segmentation utilizing convolutional neural networks (CNNs) to more conventional edge detection and Hough transform methods. Even in difficult situations, including occlusions, faded lines, or changing lighting, these models are able to recognize lane markers with accuracy. In order to improve accuracy and enable adaptive lane following and lane departure warning features in actual driving situations, robust lane-detecting systems frequently integrate optical data with sensor inputs such as LiDAR.
Depth estimation
Furthermore, depth estimation aids in assessing the distance to surrounding objects, improving the vehicle’s ability to respond suitably to changing circumstances, and understanding the spatial layout of the environment, enabling accurate distance measurement to surrounding objects. Techniques like stereovision, monocular depth estimation using deep learning, and LiDAR integration are commonly employed to enhance depth perception. This information allows autonomous vehicles to make informed decisions, such as maintaining safe distances and executing obstacle avoidance maneuvers effectively.
The fusion of these technologies allows for a thorough understanding of the environment, supporting real-time decision-making.
Despite substantial advancements in these fields, challenges persist in merging multiple perception tasks into a single, efficient system that can function reliably in diverse environmental conditions.
Methodology
Our approach integrates vision-based perception tasks for autonomous vehicles, focusing on lane detection, object recognition, and collision warnings.
Data Collection
We collected essential data such as GPS GNSS FIXED corrections, ZED2i stereo vision camera inputs, and IMU pose information, all while driving the electric vehicle.
.jpeg?Expires=1781506319&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=N3n8VY15jCBf6x7zeEejss8Or~4bmWUPF4KetYOHS1iyc9gHeh8FT2fOAyFIFZ0Xf5FH4Yk5AmhGpz71ucT7Mkl7l6S8l~aCD0eiiS6jB1BloWhfvgsT32YlP2BmVDY0TACuyIl70UCD3TbzJgGZQI67mgIQBAfqXDiXKvNM0FeEAuVIPgzbGw0GgMjk27~9hpj3AYDagzSmS~qHsjHxaI2lnubu9GmZ-wipR79t9-B~XUal3ULZR1jczcBnUepIE-4VsFFxKtc8LMTlALjDzEL0EcbP6iRfiNKRZ0PzDDaqiuIsPFr7Cw4iINeYxiK5Obnl3aAco75dyO2gDR3WKw__)
Object Detection
Using deep learning models (YOLOv5 and Traffic Sign Detection), we perform real-time object detection for identifying vehicles, pedestrians, and traffic signs, critical for obstacle avoidance and compliance with traffic rules.
Custom model
- A custom YOLOv5 model trained on traffic sign data and a traffic light classification model were loaded for detecting relevant objects and traffic signals and the signal colors (red, yellow, and green). We fine-tuned the parameters, confidence thresholds and IoU thresholds for optimal detection accuracy.
Traffic Signal Color Detection
- A lightweight convolutional neural network (CNN) is used to classify traffic light colors. The design consists of a convolutional layer followed by ReLU activation, max pooling, and a fully linked layer.
- The pre-trained weights are loaded, and the model is switched to evaluation mode for real-time inference.
Lane Detection
We applied lane detection algorithms that not only identify lanes but also estimate their curvature to ensure safe navigation in real-world driving scenarios.
- We defined a region of interest (ROI) as a trapezoidal mask to focus on the lane area.
- Preprocessed frames undergo Canny edge detection and Hough line transform to extract lane boundaries, and then the detected lines are fitted with polynomial equations to calculate lane curvature and estimate vehicle position relative to the lane center. The area in between the detected lane lines was filled using the OpenCV
fillPoly( )function.

Depth Estimation for Distance Measurement
The depth of detected objects is calculated using median depth values extracted from a depth map. Invalid or missing depth values are handled gracefully to ensure reliability. The bounding box coordinates for detected objects guide depth analysis.
Collision Warning System
-
The system calculates the distance to detected objects using depth information, providing warnings when objects come within a predefined safety range, thereby enhancing vehicle safety.
-
A side panel displays dynamic warnings and vehicle information, including lane curvature, vehicle position, and potential hazards.
-
We also subscribed to camera topic on ROS and published proximity warning. The topic published true upon detection of object within the set distance threshold and false if far.
We combine these perception tasks into a real-time video processing pipeline, overlaying detected information on the video feed and providing visual warnings when necessary.
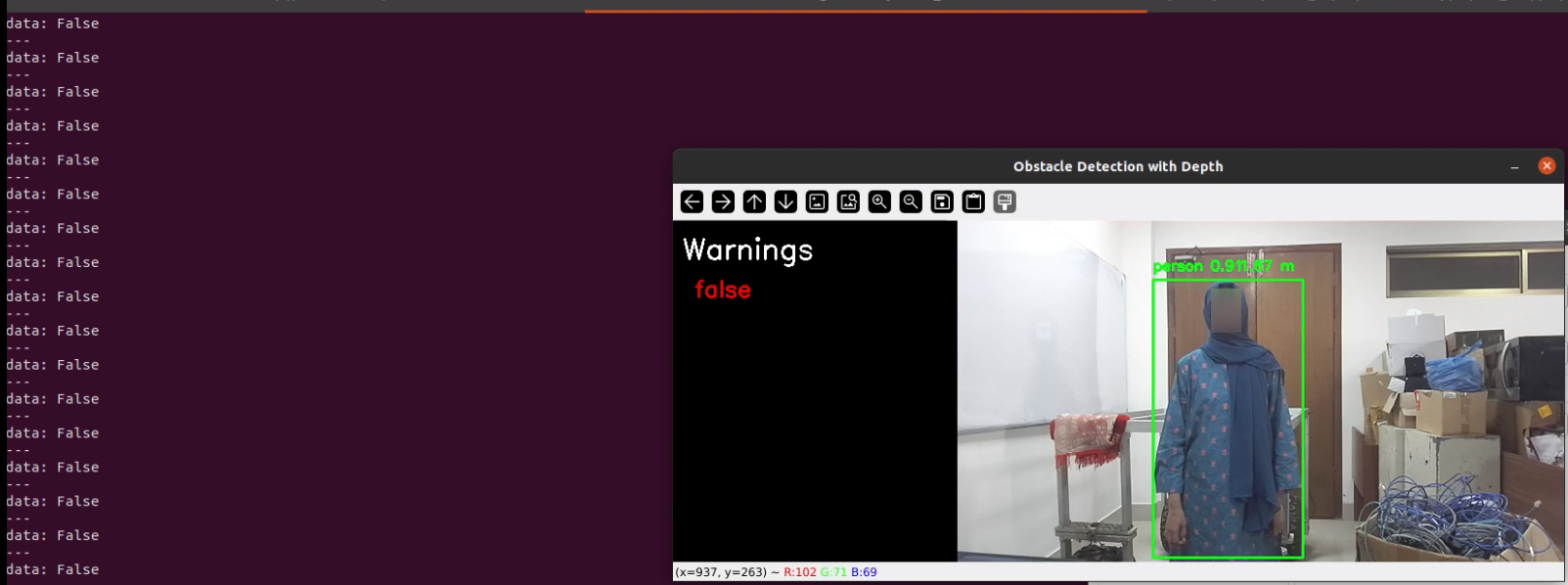
.png?Expires=1781506319&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=PdAi6Bk6vGfjm1-XsBdvvY7rz7mlIloHJ6Ef8bDi91USeRERvUl5S6JqZY3xhqvrQDmC46ewlrw7uPvsmVCg1ZnRnAqpRZ1Afkdv7iq0aAB~6llaKJ4N3g44WuaQlINOb-iDVMpF4xWYfaUYioeDYVdRqz~6TXQJCWBMJ76SRhuhKdh6r9BwlgQyHW3WphmAwzDr5ncDvoy2pXkPZ5~gV6qxcxEG6ep7pEc0hbOf4LEVHv1zntJgRL8CNNvvPtE2vuBV7MKQLbybxugdIKnP2o5PX3Z-83Cv~RQXx~4HQZQau148fW4dA4Wi3xAjxqlfSzMLz3JohYCjF3b~BnzF5g__)
Additionally, we also developed pedestrian behavior-based brake and throttle control using computer vision, ROS, a ZED camera, and BLDC controllers. The system applies brakes when objects of specific classes are detected within a specified distance and re-engages throttle when the detected objects move beyond the threshold distance.
Simulation in CARLA
Along with designing and testing our methods in real time environment, we also worked on CARLA Simulator environment. Below mentioned are the approaches we used in the simulator environment:
Object Detection
To validate object detection capabilities, we incorporated the object detection algorithm into the CARLA environment, a high-fidelity platform for simulating urban driving environment.
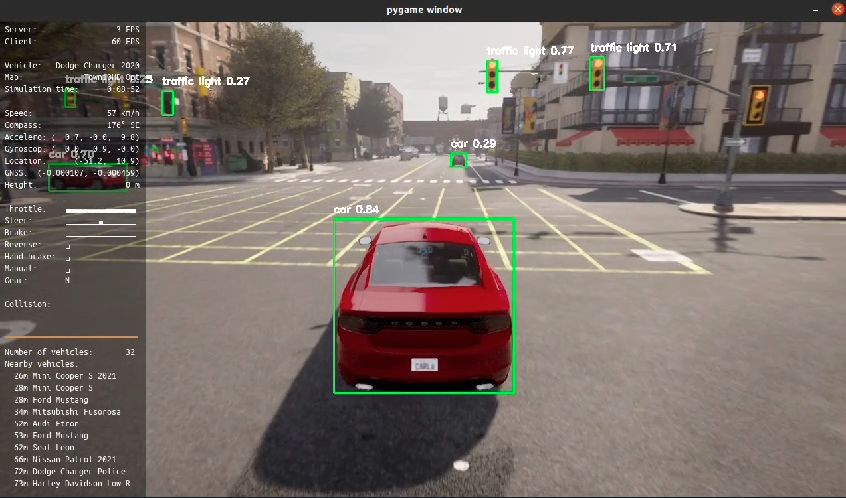
Path Control Using MPC and CARLA Visualization
We also integrated the CARLA autonomous driving simulator with ROS to enable real-time control of physical vehicle actuators. A Model Predictive Controller (MPC) was implemented in CARLA for precise throttle and brake control, ensuring smooth data communication between CARLA and a microcontroller via ROS. The control outputs, including steering, throttle, and brake, were successfully applied to a physical vehicle’s tires equipped with BLDC motor hall sensors during on-ground testing.The results are visualized in CARLA, demonstrating precise vehicle control and navigation.
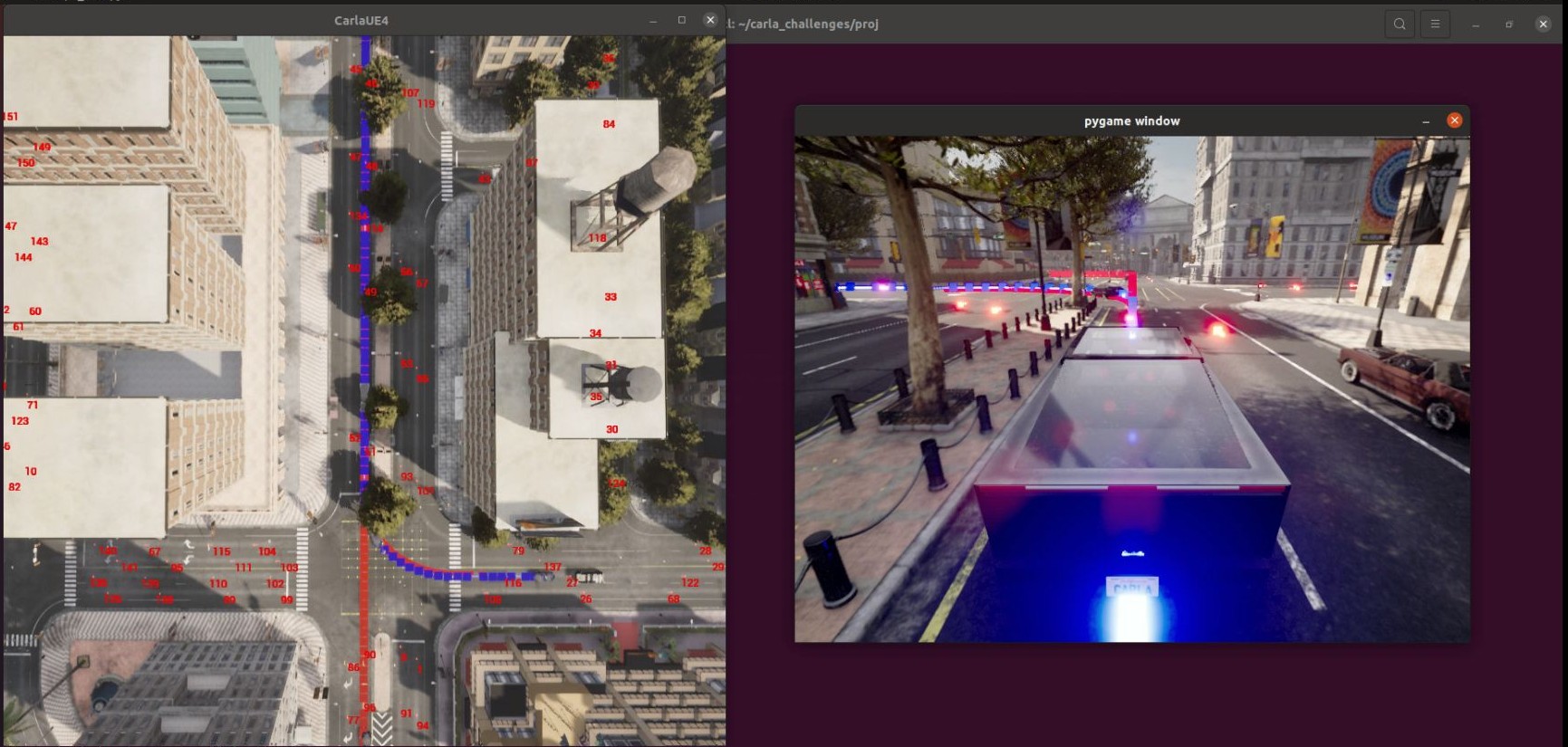
Vehicle Simulation with Real-Life Prototype Integration
The simulated vehicle in CARLA is synchronized with a real-life prototype using Arduino and ROS. This setup allows the prototype’s wheels to mimic the steering movements of the virtual car, with throttle and brake actions reflected in real time. The integration ensures seamless interaction between the virtual simulation and the physical prototype, providing a comprehensive validation framework.
Real-time camera feed was visualized via Pygame along with semantic segmentation for detailed environmental data collection.
Results
Despite complex driving settings, our system performs consistently in real-time lane detection, object recognition, and distance calculation. Lane curvature is reliably identified, allowing for smooth navigation, while object detection models (YOLOv5 and Traffic Sign Detection) effectively identify vehicles, pedestrians, and traffic signs. The collision warning system responds quickly to objects that approach too closely, delivering timely alerts. The integrated system successfully overlays pertinent information into the video feed, making it acceptable for use in real-world settings.
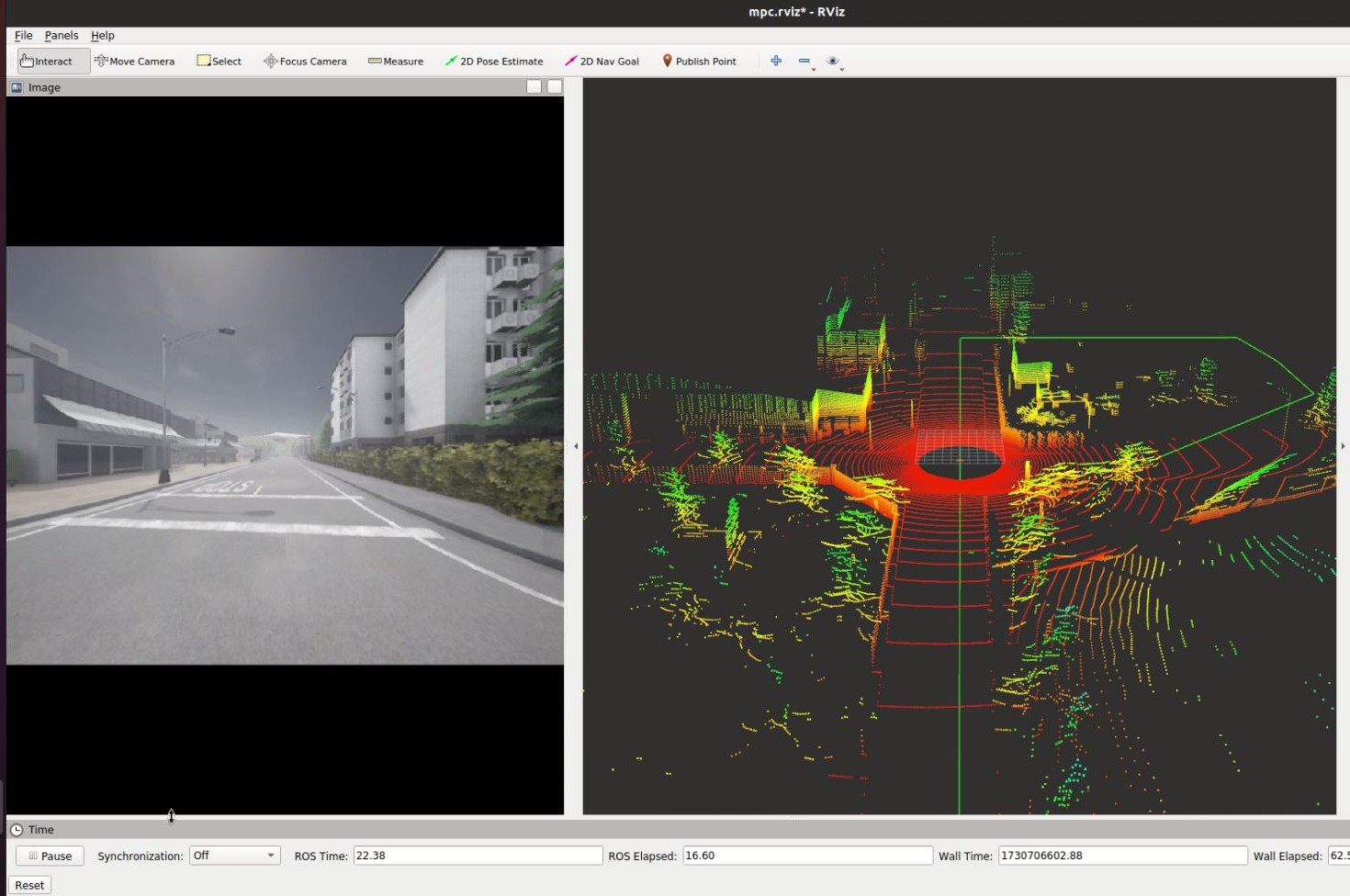
The Robosense LiDAR sensor—serving as the "eyes" of our self-driving car—helped generate a detailed 3D map of the environment. Combined with precise GPS localization, we’ve made significant progress in sensing, localization, mapping, and perception.
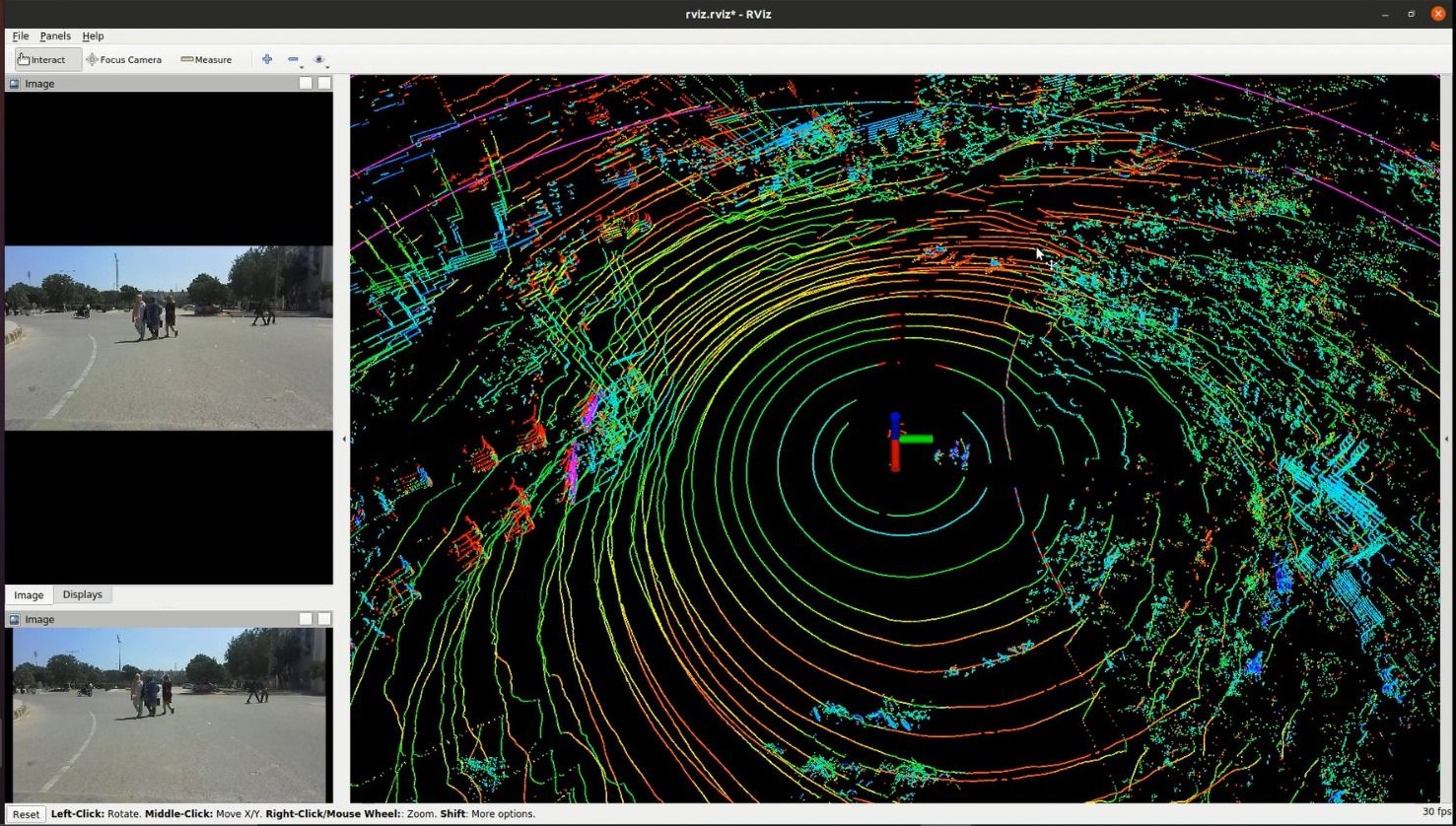
Conclusion
This work showcases the potential of leveraging computer vision techniques for improved navigation and decision-making in autonomous vehicles, contributing to the development of safer self-driving systems.
Future Work
Future developments might concentrate on improving the system's accuracy in dynamic settings, such tracking and identifying moving cars in various weather conditions. Furthermore, incorporating more sophisticated object detection models, such as multi-camera or multi-sensor fusion, may improve performance in difficult situations. Additionally, we intend to investigate environmental-condition-based adaptive warning methods, such as modifying proximity criteria for various object categories. Lastly, using predictive analytics with machine learning-based models may enhance long-term navigation and decision-making techniques.