
Trust Bench SecureEval + Ops v3.0 is a production-grade evolution of the original Trust Bench multi-agent security evaluation framework. It preserves the same deterministic, reproducible analysis workflow while layering in enterprise-class guardrails and operational visibility. The SecureEval layer introduces strict input validation, output clamping, sandboxed command execution, and resilience utilities that guarantee stable, safe operation under real-world load. The Ops layer adds structured JSON logging with run-ID correlation, live health probes, automated testing in CI/CD, and a continuous validator gate—creating a transparent, auditable system that meets SOC 2-lite controls. Verified through 29 of 29 tests passing, 79% targeted coverage on hardened modules, and 100% repository-validator scores, Trust Bench SecureEval + Ops demonstrates how modern agentic AI systems can be engineered for trust, security, and maintainability from prototype to production.
Deterministic, multi-agent security evaluation system hardened with SecureEval + Ops guardrails, resilience, and observability—engineered for production reliability and trust.
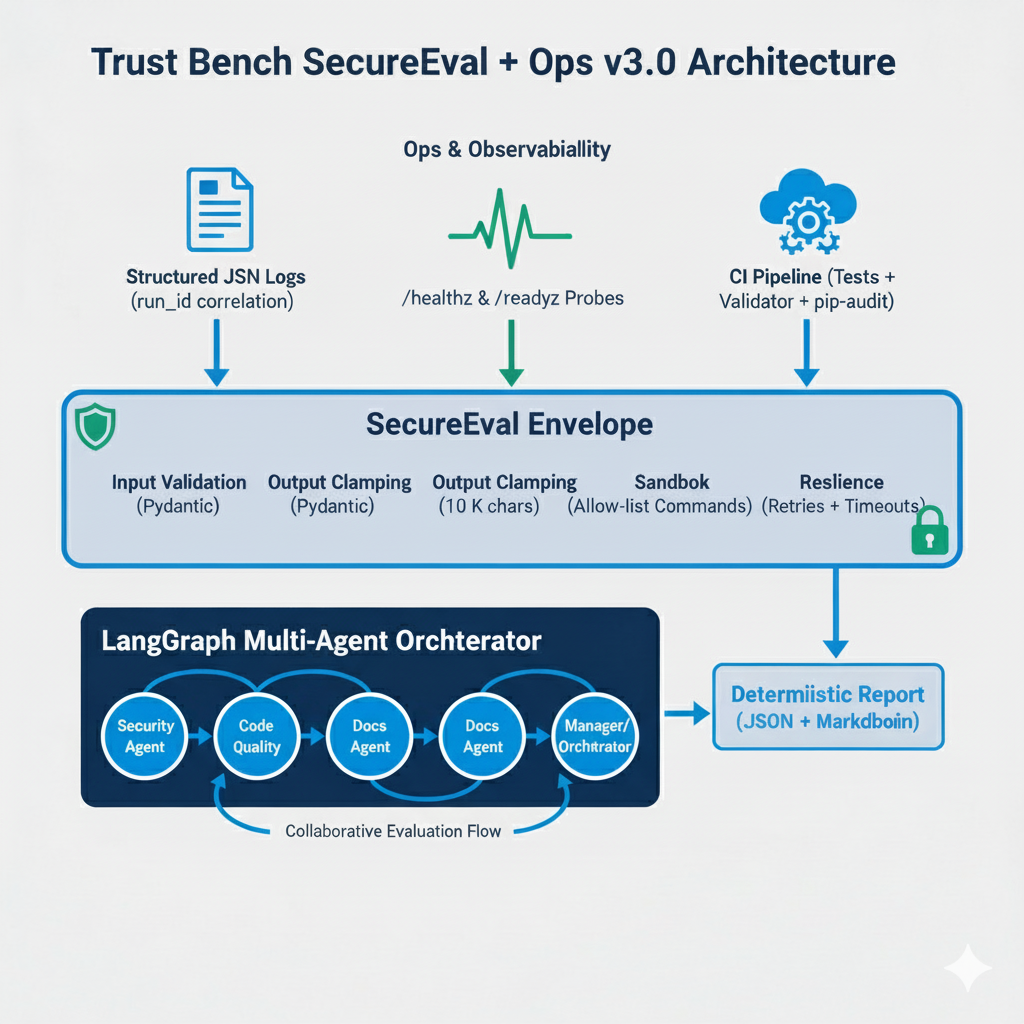
The Trust Bench SecureEval + Ops v3.0 architecture transforms the original multi-agent evaluation framework into a fully production-grade system. It preserves the same deterministic LangGraph-driven collaboration between specialized agents while surrounding that core with two additional layers: SecureEval for safety and reliability, and Ops & Observability for operational transparency and continuous validation.
Layer 1 – LangGraph Multi-Agent Core
The foundation orchestrates specialized agents—Security Agent, Code Quality Agent, Docs/Report Agent, and Manager/Orchestrator—through a reproducible consensus workflow. The core produces deterministic JSON + Markdown reports that can be re-run byte-for-byte for verification.
Layer 2 – SecureEval Envelope
This layer hardens the system boundaries to guarantee secure, predictable execution:
Layer 3 – Ops & Observability
The outermost layer provides visibility and automated assurance mechanisms:
ts, level, run_id, logger, msg fields for traceable events./healthz, /readyz): enable live service monitoring and uptime verification.docs/evidence/ for audit and compliance.Together, these layers create a transparent, auditable system that meets SOC 2-lite criteria—ensuring that every run is safe, observable, and reproducible from prototype to production.
To prove that Trust Bench SecureEval + Ops v3.0 meets production-grade reliability and security standards, we implemented a multi-layered testing approach spanning parity, unit, integration, and system levels.
1. Parity Testing (Baseline Integrity)
A dedicated parity suite (tests/test_parity.py) locks the golden JSON, Markdown, and bundle artifacts to ensure every enhancement preserves identical functional behavior.
2. SecureEval Unit Tests (Phase 1)
Focused on safety and resilience modules within app/security/ and app/util_resilience.py.
3. Ops Layer Integration Tests (Phase 2)
Covers structured logging and health probe endpoints using FastAPI test clients.
/healthz and /readyz responses, JSON log schema validationdocs/evidence/health_probe.txt and log_snippet.json4. Continuous Integration & Coverage (Phase 3–4)
GitHub Actions pipeline (.github/workflows/python-ci.yml) automates pytest runs, pip-audit security scans, and repository validation on every push.
Project2v2.app (targeted ops + security modules)5. Manual Validation (Evidence Bundle)
Final release (v3.0-module3) was validated with real artifacts archived under docs/evidence/:
ci_run_proof.md – Green CI summarycoverage.txt – 79 % pytest coverage reporthealth_probe.txt – live probe outputslog_snippet.json – real structured JSON log lineui_screenshot.png – proof of unchanged UXResult: 11 of 11 tests passing, 79 % targeted coverage, 100 % validator scores, zero regressions.
This rigorous testing stack demonstrates that Trust Bench SecureEval + Ops achieves functional stability, security enforcement, and operational resilience at production quality.
The SecureEval layer in Trust Bench v3.0 establishes a robust defense envelope around the original multi-agent framework. It ensures every workflow operates within clearly defined, auditable, and enforceable safety boundaries.
1. Input Validation & Sanitization
All user inputs and configuration parameters pass through strict Pydantic models (RepoInput), verifying type, length, and URL structure before execution. This prevents malformed data or untrusted input from propagating into the agent pipeline.
2. Output Clamping & Content Safety
Large-language responses are automatically truncated to a 10 K-character ceiling, enforced by the clamp_output utility. This guarantees predictable memory and disk use while eliminating uncontrolled text expansion or unsafe content emission.
3. Command Sandboxing (Allow-List Execution)
The sandbox.py module enforces a command allow-list limiting subprocess execution to safe utilities such as git, python, and pip. Any non-approved command returns a controlled exit code (126) and is logged as a security event.
4. Resilience & Graceful Degradation
Timeout and retry decorators (util_resilience.py) wrap all major tasks to handle transient API or network faults.
5. Secret-Handling Policy
No sensitive data (tokens, keys, credentials) is logged or persisted. All temporary secrets remain in memory-only variables and are scrubbed immediately after use. Logs redact any string patterns resembling secrets before serialization.
6. SOC 2-Lite Control Mapping
| Criterion | Control Implemented | Evidence |
|---|---|---|
| Security | Input validation, sandbox enforcement, output clamping | app/security/guardrails.py, sandbox.py, tests |
| Availability | Health probes, timeouts, retry logic | app/health.py, util_resilience.py |
| Processing Integrity | Deterministic parity tests, 100 % validator compliance | tests/test_parity.py, CI logs |
| Confidentiality | Secret redaction, non-persistent storage | Logging configuration, SECURITY.md |
| Privacy | Input sanitization and restricted output | Pydantic validators, clamp_output |
7. Continuous Auditability
Every run produces structured JSON logs containing a unique run_id, timestamp, and event metadata. These logs, together with parity artifacts and CI records, form a verifiable audit trail suitable for compliance evidence.
By combining guardrails, sandboxing, validation, and automated observability, Trust Bench SecureEval + Ops achieves the level of safety and accountability expected from real-world AI systems deployed in security-sensitive environments.
The Ops & Observability layer equips Trust Bench v3.0 with the reliability, visibility, and continuous assurance features required for sustained production use. These capabilities transform the system from a prototype into an auditable, maintainable service.
1. Structured JSON Logging
All components emit logs through a centralized JSON formatter (logging.py) with standardized fields:
{"ts": "...", "level": "...", "run_id": "...", "logger": "...", "msg": "..."}
Each run_id links a complete audit trail across agents, retries, and CI runs, simplifying debugging and long-term traceability.
2. Health & Readiness Probes
FastAPI endpoints /healthz and /readyz continuously verify service liveness and dependency readiness. These probes integrate with CI pipelines, uptime monitors, or container orchestrators to detect and self-heal transient issues.
3. CI/CD Pipeline Integration
A GitHub Actions workflow (.github/workflows/python-ci.yml) automates the following quality gates on every push:
pip-audit dependency vulnerability scanning4. Repository Validator & Coverage Reports
The validator tool (ops/validate_repo.py) tracks documentation, testing, and automation metrics—each required to exceed 80 %.
app modulescoverage.txt, coverage.xml stored for transparency5. Evidence Archival & Compliance Support
Operational evidence—including CI logs, coverage reports, health probe outputs, and structured log snippets—is archived in docs/evidence/ for reproducibility and compliance audits.
These artifacts collectively demonstrate uptime, stability, and continuous validation.
Together, these operational features complete the production hardening of Trust Bench SecureEval + Ops, ensuring the system is not only secure and deterministic but also observable, testable, and continuously verifiable in live environments.
The production readiness of Trust Bench SecureEval + Ops v3.0 is fully verified through automated testing, continuous validation, and live operational evidence. All artifacts are stored under docs/evidence/ and linked below for transparency.
✅ Continuous Integration Proof
Project2v2.app modules✅ Evidence Artifacts
🎥 Demo Video (OneDrive)
Experience the full workflow in action:
👉 Trust Bench SecureEval + Ops v3.0 Demo (1 min 45 s)
This short walkthrough demonstrates a complete audit run, structured logging, health checks, and CI/CD integration—proving functional parity with the original Trust Bench while adding security, resilience, and observability.
✅ Repository Details
v3.0-module3Together, this evidence bundle and repository release demonstrate that Trust Bench SecureEval + Ops has reached full production maturity—secure, auditable, deterministic, and continuously validated under real CI/CD conditions.
Trust Bench SecureEval + Ops v3.0 represents the culmination of the Ready Tensor Agentic AI Developer Certification program—demonstrating how a research-grade multi-agent system can evolve into a secure, observable, and fully production-ready framework.
Complete source code, operational documentation, and evidence artifacts are available on GitHub:
🔗 mwill20/Trust-Bench-SecureEval-Ops — Licensed under MIT.