Type: Software Tool + Real-World Application
Goal: To build a professional, and high-performance chatbot that answers user questions based strictly on the content of uploaded documents using Retrieval-Augmented Generation (RAG).
This project demonstrates a complete RAG pipeline that transforms a general-purpose Large Language Model (LLM) into a specialized, document-grounded expert. By leveraging the high-speed inference of the Groq API, LangChain for orchestration, and ChromaDB for efficient vector storage, this chatbot delivers fast, accurate, and secure answers. It supports multiple document formats (PDF, DOCX, TXT, and Markdown) and is wrapped in a user-friendly Streamlit interface.
The core strength of this application lies in its performance and strict adherence to the provided context, ensuring that it never hallucinates or provides information outside the scope of the uploaded document.
This publication serves as a comprehensive guide for developers, researchers, and AI enthusiasts looking to build reliable and secure RAG systems. While many LLMs offer broad knowledge, they often fail when domain-specific, factual accuracy is required. This project provides a practical, end-to-end solution to that problem.
It is particularly useful for:
configs/prompt_config.yaml) ensures the chatbot refuses to answer out-of-scope, unethical, or sensitive questions.ingest.py.chatbot.py).ingest.py), RAG pipeline logic (RAG_pipeline.py), and prompt engineering (prompt_builder.py).The system follows a clear and efficient pipeline to transform a user's question into a document-grounded answer. The entire workflow can be visualized in the architecture diagram below.
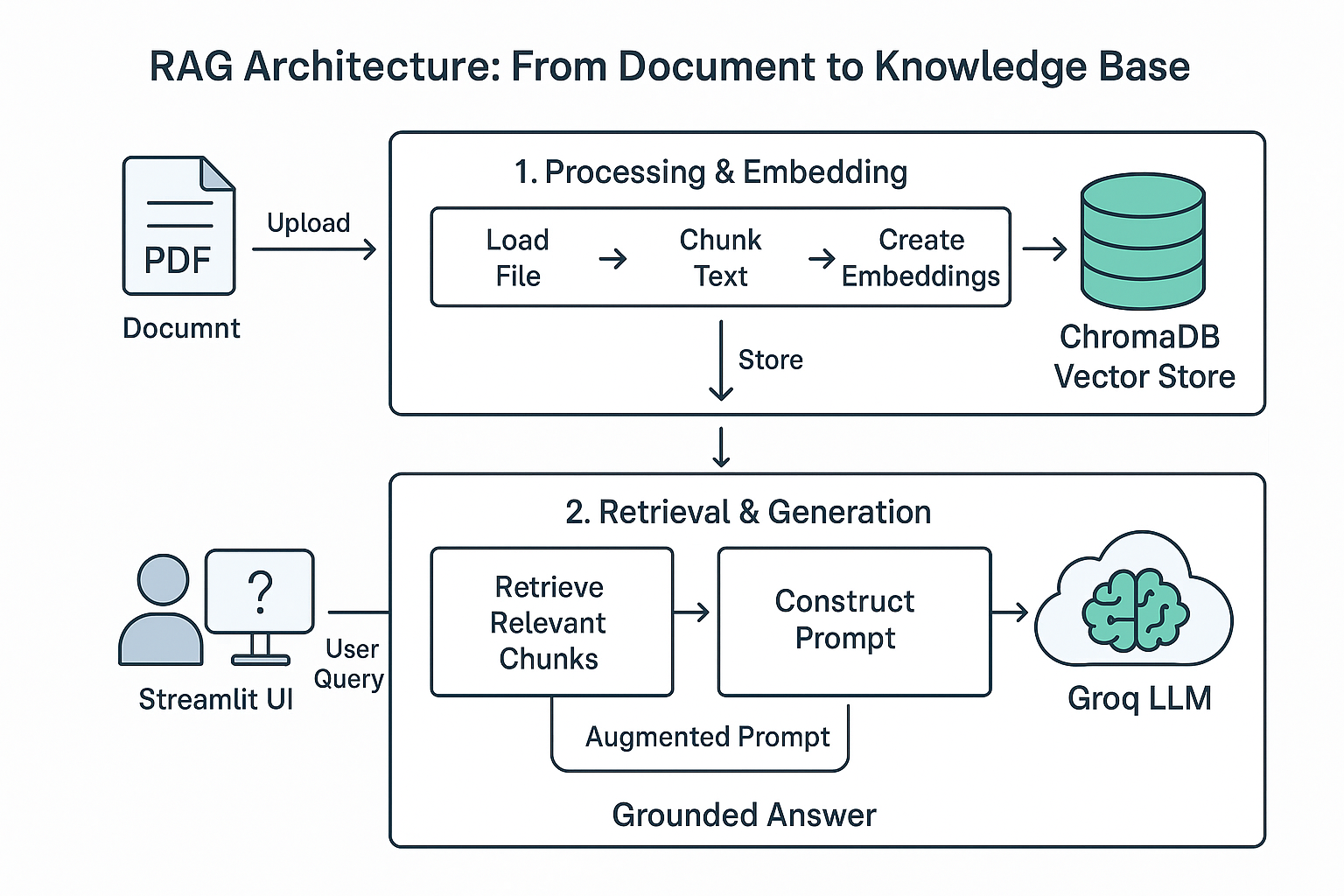
ingest.py script uses the load_document function to extract raw text from the file.RecursiveCharacterTextSplitter with a chunk size of 512 and an overlap of 128 tokens. This is handled by the chunk_document function.sentence-transformers/all-MiniLM-L6-v2 model via the embed_chunks function.initialize_vector_db and insert_documents.retrieve_relevant_documents function in RAG_pipeline.py first converts the query into an embedding.build_prompt_from_config function, which uses a detailed YAML configuration (configs/prompt_config.yaml) to construct a highly specific system prompt.llama-3.1-8b-instant) to generate a response that adheres to the prompt's constraints.Get started locally in just a few steps:
Clone the Repository
git clone https://github.com/mohsinansari0705/File-QnA-Chatbot-using-RAG.git cd File-QnA-Chatbot-using-RAG
Create a Virtual Environment (Recommended)
# On Windows python -m venv RAG_env RAG_env\Scripts\activate # On macOS/Linux python3 -m venv RAG_env source RAG_env/bin/activate
Install Dependencies
pip install -r requirements.txt
Launch the App
streamlit run chatbot.py
The chatbot will open in your browser. Enter your Groq API key in the sidebar, upload a document, and start asking questions!
The application provides a seamless and secure user experience. The interface is clean, and the responses are strictly confined to the document's content, delivering fast and accurate answers.
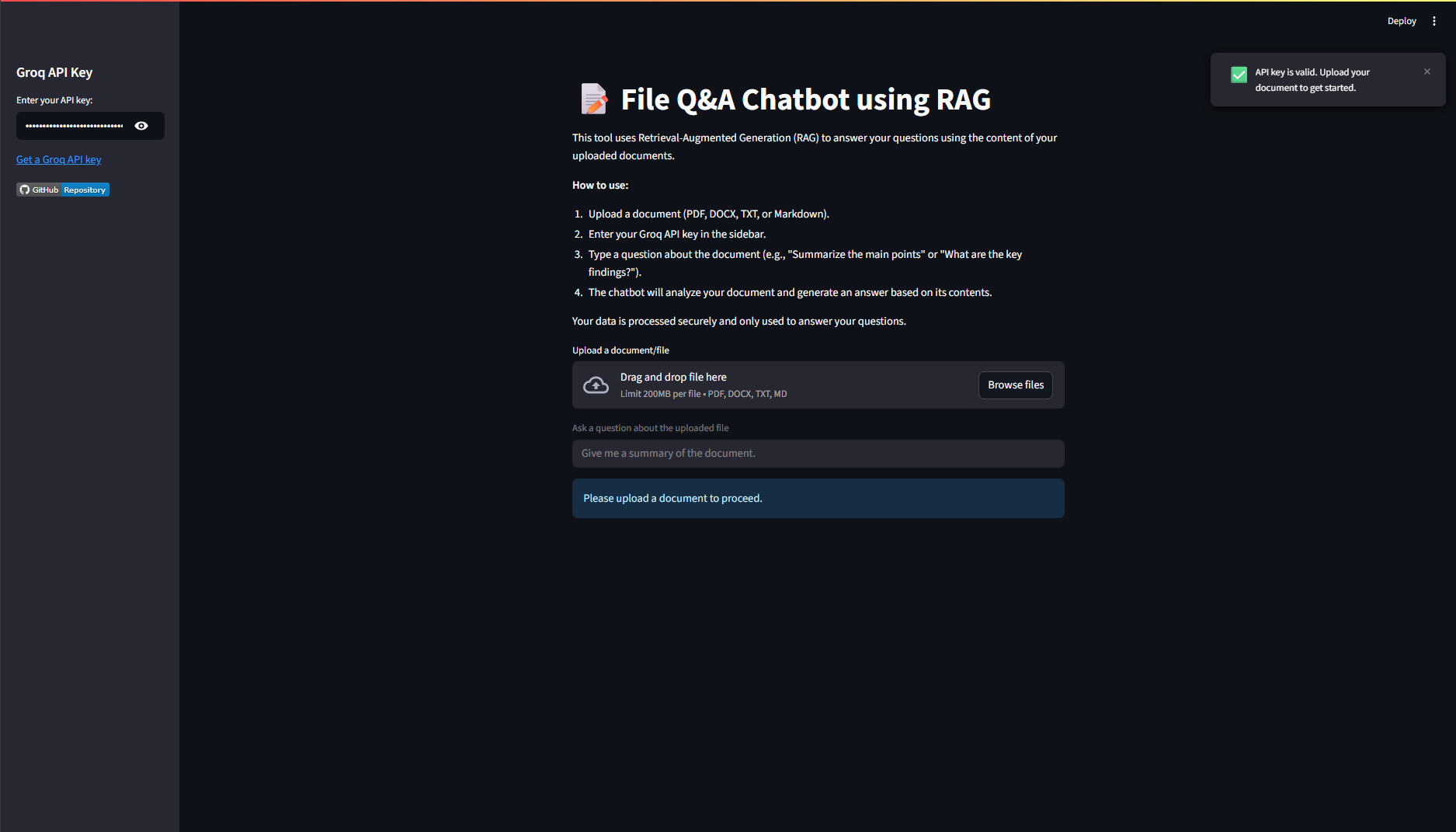
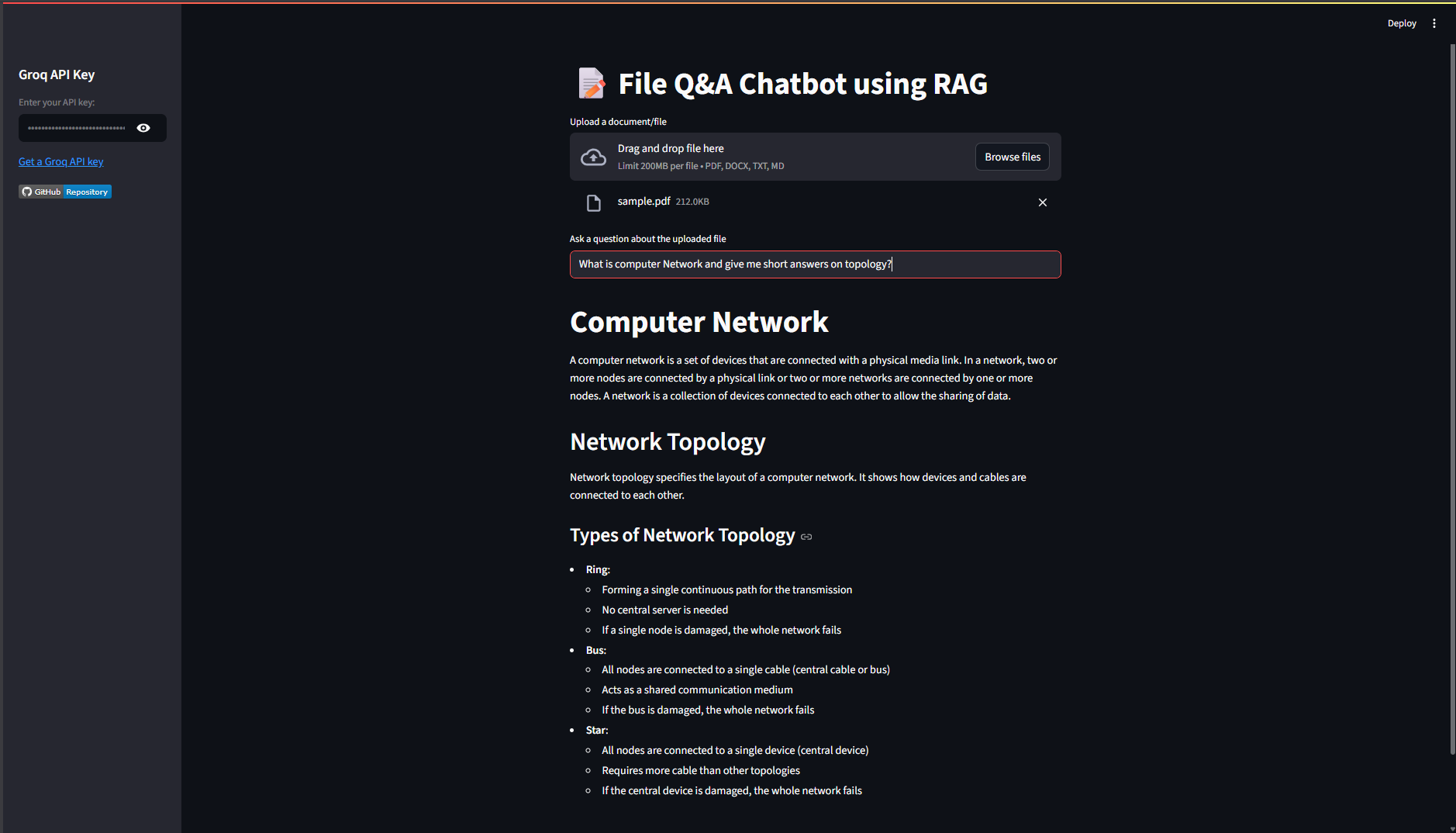
This project successfully implements a secure, high-performance RAG chatbot by combining the strengths of modern AI tools. It stands out due to its robust security framework, which is enforced by a meticulously crafted system prompt, and its impressive speed, thanks to the Groq LLM API. The modular architecture makes it an excellent foundation for building more complex, domain-specific AI applications.
This project is licensed under the MIT License. The full license text is in the MIT License file in the repo.
I am interested in your opinion about this project!
If you have any suggestions or want to adapt the bot to your own tasks, reach out to me Mohsin Ansari.
