
Can a language model with only tens of millions of parameters learn grammar, narrative structure, and character consistency? With the right dataset, context length, and training budget, the answer is surprisingly yes.
Many tutorials on building GPT-style language models stop at generating toy outputs—character-level text, simple word sequences, or incoherent stories trained on only a tiny fraction of a dataset. While these examples are useful for understanding transformer mechanics, they rarely demonstrate how to train a model capable of maintaining narrative flow and producing coherent multi-sentence outputs.
StoryGPT is a causal decoder-only Small Language Model (SLM) trained from scratch on the roneneldan/TinyStories dataset. The project focuses on building a practical and educational pretraining pipeline using modern PyTorch features, memory-efficient data loading, mixed-precision training, and scalable training practices.
The model uses a 10-layer decoder-only transformer with a context length of 256 tokens and is trained on approximately 3.28 billion tokens from TinyStories. Despite its relatively small size compared to modern foundation models, StoryGPT learns grammatical structure, narrative progression, and short-form storytelling patterns while remaining computationally accessible enough to train on a single NVIDIA A100 GPU.
This article walks through the complete engineering pipeline behind StoryGPT—from dataset tokenization and memory-mapped storage to transformer architecture design, optimization strategies, checkpointing, and deployment through the Hugging Face Hub.
The pretraining of StoryGPT is organized into a modular, clean, and efficient pipeline.
graph TD %% Global Configuration subgraph CONFIGURATION["config.py: Configuration State"] G_CFG["GPTConfig\n(vocab_size, context_len, layers, heads, embd)"] T_CFG["TrainingConfig\n(learning_rate, batch_size, grad_accum, path)"] end %% Ingestion Flow subgraph DATA_INGESTION["prepare_data.py: Ingestion & Tokenization"] HF_DS["TinyStories Dataset\n(Hugging Face)"] TOKENIZER["tiktoken (GPT-2 encoding)"] SHARD["Dataset Mapping & Sharding"] MEMMAP_T["train.bin\n(uint16 memmap)"] MEMMAP_V["validation.bin\n(uint16 memmap)"] end %% Model Definition subgraph MODEL_ARCHITECTURE["model.py: GPT Architecture"] TE["Token Embedding"] PE["Positional Embedding"] TRANS_B["Transformer Blocks (x10)\n(CausalSelfAttention, MLP)"] LN["LayerNorm & LM Head"] GPT_CLASS["GPT Model Class"] end %% Pretraining Flow subgraph PRETRAINING["train.py: Training & Checkpointing"] TRAIN_LOOP["Pretraining Loop\n(AdamW + GradScaler)"] EVAL_LOOP["Periodic Validation Loss Evaluation"] SCHEDULER["LR Scheduler\n(Warmup + Cosine Decay)"] PLOT["loss_plot.png"] CHKP_BEST["StoryGPT_best.pt"] CHKP_FINAL["StoryGPT_final.pt"] end %% Inference Flow subgraph INFERENCE["generate.py: Inference Engine"] PROMPT["User Prompt Input"] SAMPLER["Autoregressive Sampler\n(Temp & Top-k Filtering)"] OUTPUT_STORY["Generated Story Output"] end %% Hugging Face Distribution subgraph DISTRIBUTION["upload_to_hf.py: Hub Distribution"] HF_HUB["Hugging Face Model Hub"] end %% Connections G_CFG --> MODEL_ARCHITECTURE T_CFG --> PRETRAINING HF_DS --> TOKENIZER TOKENIZER --> SHARD SHARD -->|np.memmap| MEMMAP_T SHARD -->|np.memmap| MEMMAP_V MEMMAP_T --> PRETRAINING MEMMAP_V --> PRETRAINING GPT_CLASS --> PRETRAINING TE & PE & TRANS_B & LN --> GPT_CLASS PRETRAINING -->|Saves weights| CHKP_BEST PRETRAINING -->|Generates plot| PLOT CHKP_BEST --> INFERENCE PROMPT --> INFERENCE INFERENCE --> SAMPLER SAMPLER --> OUTPUT_STORY CHKP_BEST & MODEL_ARCHITECTURE & CONFIGURATION --> DISTRIBUTION DISTRIBUTION -->|api.upload_file| HF_HUB
We train StoryGPT on the roneneldan/TinyStories dataset. TinyStories contains short stories generated with simple vocabulary and sentence structure, which makes it especially suitable for training small language models on narrative behavior rather than broad world knowledge.
Raw text, however, is too slow to load dynamically during GPU training. We build a high-performance ingestion pipeline in prepare_data.py.
Instead of training a custom tokenizer, we adopt the standard GPT-2 byte-pair encoding (BPE) tokenizer via tiktoken.
vocab_size): 50,25750256 (<|endoftext|>) at the end of each story text.np.memmap)To avoid loading large token arrays into system memory, the tokenized splits are written directly to disk as contiguous binary streams of uint16 values. Since the maximum token value is 50,256, it fits comfortably in a 16-bit integer, which reduces storage overhead and makes training input access fast and simple.
dtype = np.uint16 arr = np.memmap(filename, dtype=dtype, mode='w+', shape=(arr_len,))
During training, train.py memory-maps these files in read-only mode. The training loop samples batches by reading token offsets directly from disk and moving them to the GPU only when needed.
The model implementation in model.py defines a causal, decoder-only Transformer inspired by the GPT-2 architecture. The implementation emphasizes clarity, modularity, and efficient execution using modern PyTorch primitives.
We configure StoryGPT with the following parameters:
| Hyperparameter | Value | Rationale |
|---|---|---|
| Model Parameters | approximately 57M | A compact model size suitable for learning short-form stories |
Embedding Dimension (n_embd) | 512 | Representation capacity of token features |
Attention Heads (n_head) | 8 | Each head has dimension 512 / 8 = 64 |
Layers (n_layer) | 10 | Depth to capture narrative structure |
Context Length (context_length) | 256 | Covers most TinyStories sequences efficiently |
| Dropout | 0.1 | Regularization to reduce overfitting |
| Bias | True | Used in linear layers and layer norms for GPT-2-style consistency |
The attention implementation utilizes PyTorch's native scaled_dot_product_attention API when available:
if hasattr(F, "scaled_dot_product_attention"): attention_output = F.scaled_dot_product_attention( queries, keys, values, dropout_p=self.dropout if self.training else 0.0, is_causal=True, )
This API allows PyTorch to automatically dispatch to the most efficient attention backend supported by the current hardware and software environment. Depending on the GPU architecture and PyTorch version, execution may utilize optimized kernels such as Flash Attention, Memory-Efficient Attention, or the standard mathematical implementation.
When SDPA is unavailable, the model falls back to a manually implemented masked attention mechanism using causal masking.
This approach provides both portability and performance while keeping the implementation simple and easy to study.
Pretraining from scratch is sensitive to training configuration, so the training loop is designed to stay stable and reproducible.
We configure a physical batch size of 64 sequences per micro-step. To simulate a larger batch size of 256 sequences without running out of GPU memory, we accumulate gradients over 4 steps before applying an optimizer update.
64 × 4 = 256 sequences256 × 256 = 65,536 tokensWe use AdamW with a weight decay of 0.1 and gradient clipping set to 1.0 to stabilize training.
The learning rate follows a custom schedule using PyTorch's SequentialLR:
3e-5.scheduler_warmup = LinearLR(optimizer, start_factor=0.001, total_iters=warmup_updates) scheduler_decay = CosineAnnealingLR(optimizer, T_max=total_updates - warmup_updates, eta_min=min_lr) scheduler = SequentialLR(optimizer, schedulers=[scheduler_warmup, scheduler_decay], milestones=[warmup_updates])
To maximize GPU utilization, StoryGPT employs automatic mixed-precision training.
The training script automatically selects:
When float16 is used, PyTorch's GradScaler is enabled to prevent gradient underflow. When bfloat16 is available, scaling is unnecessary because bfloat16 retains the dynamic range of float32 while providing significant memory and throughput benefits.
Validation loss is evaluated periodically during training, and the best-performing checkpoint is saved automatically. This makes it easy to keep the model state that generalizes best, rather than relying only on the final training step.
StoryGPT was pretrained for 50,000 steps. The validation loss was evaluated every 500 steps, and the checkpoint with the lowest validation loss was saved as the production candidate.
The model shows stable optimization throughout training, with validation loss closely tracking training loss. The absence of large divergence suggests that the chosen regularization and learning-rate schedule are effective for this setup.
Example progression:
Step 500: train loss 5.2104, val loss 5.1983 Step 1000: train loss 3.4215, val loss 3.4092 Step 5000: train loss 2.1560, val loss 2.1601 Step 10000: train loss 1.7610, val loss 1.7690 Step 25000: train loss 1.3504, val loss 1.3683 Step 50000: train loss 1.0924, val loss 1.1218
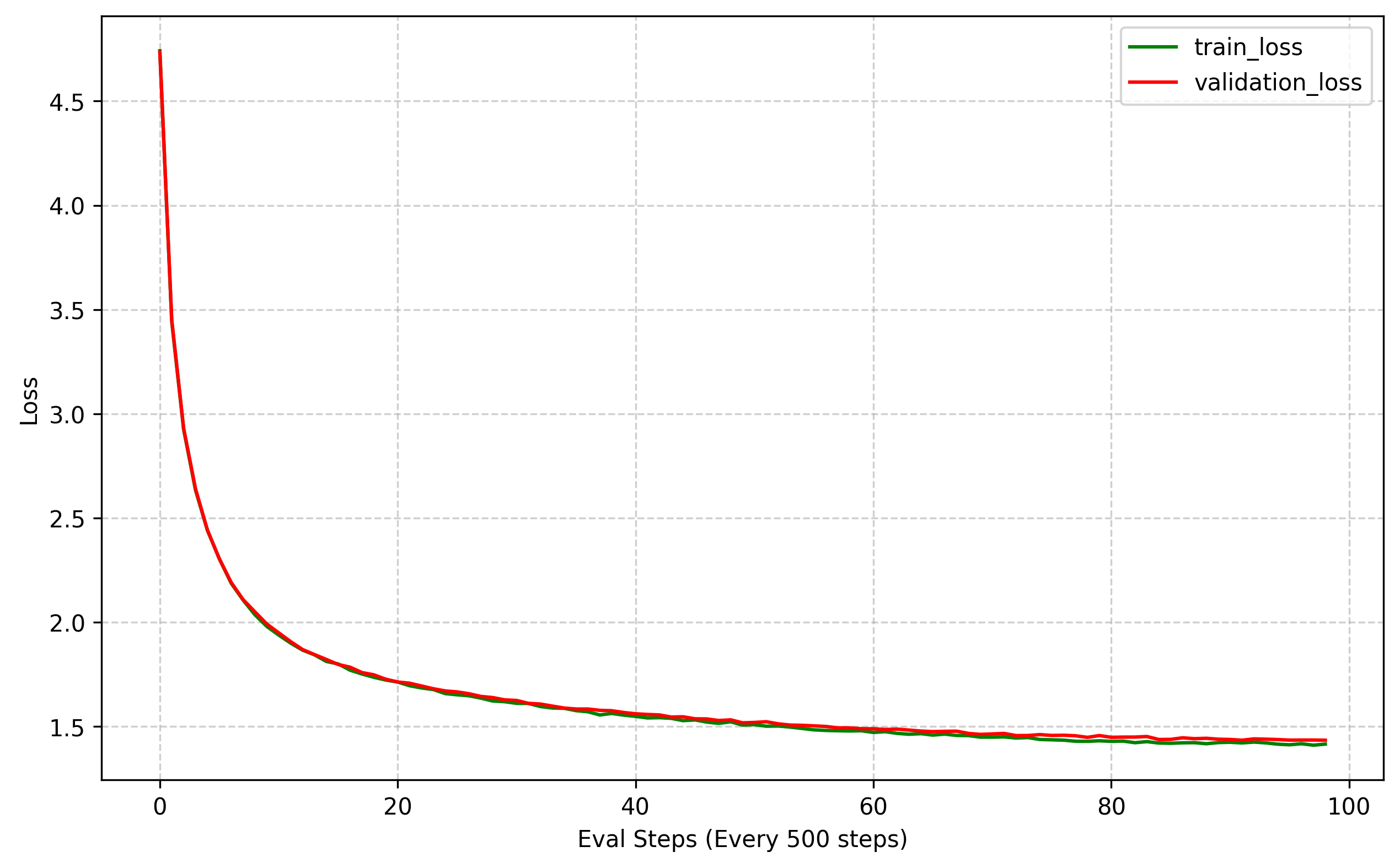
If you want to report an exact perplexity value, you can compute it from the validation loss using:
import math perplexity = math.exp(val_loss)
Prompt
Once upon a time there was a king.
Generated Output
Once upon a time there was a king. He lived in a castle and never wanted to get out. One day, he heard a noise. He looked around and saw a little girl. She was shaking with fear. The king asked her why she was shaking. The girl said she was scared of the loud noise. The king wanted to help her, so he offered her a hand. He said, "Don't be scared. It's just a noise. Just be brave and be brave". The little girl felt much braver and tried to join the king. He held her hand and said, "Let's go together". He took her hand and they went outside. The little girl was so happy. She smiled and hugged the king. They had a wonderful time. From that day forward, they were the greatest of friends.
Prompt
A little rabbit found a mysterious box.
Generated Output
A little rabbit found a mysterious box under a bush. The rabbit was very curious. He wanted to know what was in the box. He hopped closer and looked at it. The rabbit said, "I can't open it, but it might be a surprise!" The rabbit tried to open the box, but it was too hard. He asked his friend, a small mouse, to help him. "Can you help me open the box?" the rabbit said. The mouse tried and tried, but he could not open the box. The rabbit and the mouse decided to work together. They jumped and jumped and shook the box. They pulled and pushed until the box opened. Inside, there were many colorful balls inside. The rabbit and the mouse had so much fun playing with the balls. They played together and became the best of friends.
To make sharing easy, upload_to_hf.py packages the code definition and trained model weights, uploading them directly to the Hugging Face Hub.
Running the upload command creates the model repository on the Hub and generates a structured model card:
python upload_to_hf.py --repo_id "username/StoryGPT" --token "hf_token"
By packaging the model files inside the Hugging Face repository, anyone can run inference programmatically without cloning the full Git repository manually.
import os import sys import torch import tiktoken from huggingface_hub import hf_hub_download # Define repository and destination repo_id = "your-username/StoryGPT" local_dir = "./StoryGPT_model" os.makedirs(local_dir, exist_ok=True) # 1. Download model definition, config, and weights hf_hub_download(repo_id=repo_id, filename="model.py", local_dir=local_dir) hf_hub_download(repo_id=repo_id, filename="config.py", local_dir=local_dir) checkpoint_path = hf_hub_download(repo_id=repo_id, filename="checkpoints/StoryGPT_best.pt", local_dir=local_dir) # 2. Dynamically import model definition from downloaded directory sys.path.append(local_dir) from model import GPT # 3. Load model weights device = "cuda" if torch.cuda.is_available() else "cpu" checkpoint = torch.load(checkpoint_path, map_location=device, weights_only=False) model = GPT(checkpoint["gpt_config"]) model.load_state_dict(checkpoint["model_state_dict"]) model.to(device) model.eval() # 4. Generate story enc = tiktoken.get_encoding("gpt2") prompt = "Once upon a time, there was a little boy named Timmy who found a magic key." context = torch.tensor(enc.encode_ordinary(prompt), dtype=torch.long, device=device).unsqueeze(0) print("Generating...") with torch.no_grad(): out = model.generate(context, max_new_tokens=200, temperature=0.8, top_k=100) print(enc.decode(out[0].tolist()))
During development, several design choices shaped the implementation.
memmap vs. PyTorch DatasetsStandard PyTorch text loaders often keep token sequences in RAM while preparing batches. For datasets with hundreds of millions of tokens, that approach can become expensive and fragile. Using a NumPy memmap format keeps memory usage predictable while allowing fast sequential access to token shards.
The model uses Pre-LayerNorm blocks, meaning normalization happens before attention and MLP sublayers. This design improves training stability, especially as depth increases, and is widely used in modern decoder-only language models.
Using tiktoken's GPT-2 tokenizer avoids introducing a custom vocabulary file and keeps the pipeline portable. It also simplifies loading and inference, because the same tokenizer is widely supported and easy to reproduce.
A context length of 256 is a practical choice for TinyStories. It is long enough to model most short stories in the dataset while keeping compute cost manageable. Since attention cost grows quickly with sequence length, doubling the context window would significantly increase training cost without offering a proportional benefit for this specific dataset.
StoryGPT demonstrates that meaningful language-model pretraining is possible without billion-parameter architectures. By combining efficient data preprocessing, memory-mapped storage, modern transformer design patterns, mixed-precision training, and scalable optimization techniques, a relatively small decoder-only model can learn grammatical structure and narrative patterns from a specialized dataset.
Beyond the final model itself, the project serves as a practical reference implementation for anyone interested in understanding the complete lifecycle of language-model pretraining—from raw text ingestion and tokenization through training, evaluation, checkpointing, and model distribution.
For practitioners interested in training domain-specific Small Language Models, StoryGPT provides a lightweight and reproducible foundation that can be extended to larger datasets, longer context lengths, and more advanced architectures.
HuggingFace Model Weights: https://huggingface.co/justjuu/story-gpt
