In the previous articles, we explored how speech signals are transformed into meaningful representations.
We began with the physics of sound, examining how speech exists as pressure waves in air. We then moved through frequency analysis, learning how the Fourier Transform reveals the frequency components of speech. After that, we explored mel-scale representations, which approximate how humans perceive pitch, and MFCCs, which have been a foundational feature representation in speech recognition for decades.
Most recently, we examined pitch, formants, and prosody, which capture important characteristics of how speech evolves over time.
All of these techniques share a common idea: we design features manually based on our understanding of speech production and perception.
For many years, speech recognition systems relied heavily on these carefully engineered features.
However, modern speech AI systems increasingly rely on a different paradigm: Self-Supervised Learning (SSL).
Instead of relying on handcrafted features, these models learn representations directly from raw audio by training on massive amounts of unlabeled speech.
This shift has fundamentally transformed speech technology.
The Challenge of Labeled Speech Data
Training traditional speech recognition systems requires labeled datasets.
A typical training example looks like this:
Audio recording → “The quick brown fox jumps over the lazy dog.”
Each audio clip must be paired with its correct text transcription.
Creating such datasets is extremely expensive and time-consuming because the transcription must be performed manually by humans.
For many languages around the world, especially in Africa and other underrepresented regions, this presents a serious challenge.
Common issues include:
- limited availability of large speech corpora
- shortage of trained annotators
- high dialect variation across regions
At the same time, there is an enormous amount of unlabeled speech data available:
- radio broadcasts
- podcasts
- online videos
- community recordings
- everyday conversations
Self-supervised learning allows models to learn from this raw audio without requiring human annotations.
What Is Self-Supervised Learning?
Self-supervised learning is a training paradigm in which a model creates its own supervision signal from the input data.
Instead of learning from labels provided by humans, the model learns by solving pretext tasks derived from the structure of the data itself.
In speech processing, these tasks typically involve forcing the model to predict or reconstruct parts of the signal.
Examples include:
- predicting masked portions of the audio
- identifying the correct acoustic representation among several alternatives
- predicting hidden acoustic units derived from clustering
By solving these tasks, the model learns general-purpose speech representations.
These learned representations can later be adapted for downstream tasks such as:
- automatic speech recognition
- speaker identification
- emotion detection
- keyword spotting
Once the model has learned these representations, only a small amount of labeled data is required to fine-tune it for a specific application.
wav2vec 2.0: Learning Speech Representations from Raw Audio
One of the most influential self-supervised speech models is wav2vec 2.0, introduced by researchers at Meta AI.
Unlike earlier speech systems that relied on features like MFCCs or mel spectrograms, wav2vec 2.0 operates directly on raw waveforms.
The architecture consists of three major components.
Feature Encoder
The first stage is a convolutional neural network that processes the raw waveform.
Speech signals are continuous time-series data, and convolutional layers are well-suited for capturing local temporal patterns.
This network transforms the waveform into a sequence of latent acoustic representations.
These latent features capture patterns such as:
- short-term frequency structure
- amplitude variations
- local temporal dependencies
In effect, the model learns its own internal representation of low-level acoustic features.
Context Network (Transformer)
The latent acoustic features are then passed into a Transformer encoder.
Transformers are sequence models that rely on self-attention mechanisms.
Self-attention allows each time step in the speech signal to incorporate information from other time steps.
In speech processing, this enables the model to capture relationships such as:
- transitions between phonemes
- syllable patterns
- long-range dependencies across an utterance
Through multiple layers of self-attention and feed-forward transformations, the network builds increasingly context-aware speech representations.
Contrastive Learning Objective
During training, parts of the latent representation sequence are masked.
The model must identify the correct representation among several possible candidates.
This task is known as contrastive learning.
By forcing the model to distinguish correct acoustic representations from incorrect ones, the training process encourages the network to learn meaningful speech structure.
Importantly, this learning occurs without any text transcripts.
Other Self-Supervised Speech Models
Several other architectures have extended the ideas introduced by wav2vec 2.0.
HuBERT
HuBERT (Hidden-Unit BERT) uses a different training strategy.
Instead of directly predicting masked acoustic representations, it predicts cluster assignments derived from acoustic features.
The process works in stages:
- Extract acoustic features from speech.
- Cluster these features using k-means.
- Use the cluster IDs as pseudo-labels.
- Train a model to predict these units when audio segments are masked.
Even though the cluster labels are imperfect, they provide enough structure for the model to learn meaningful speech representations.
WavLM
WavLM further extends the SSL framework by learning representations that capture both:
- linguistic content
- speaker characteristics
This makes WavLM particularly effective across a wide range of speech tasks, including:
- speech recognition
- speaker verification
- speech separation
What Do Different Layers Learn?
An interesting research question is:
What types of information are represented in different layers of self-supervised speech models?
Researchers investigate this using probing experiments.
A typical probing experiment involves:
- Extracting representations from different layers of a model.
- Training a simple classifier on top of those representations.
- Evaluating which layers capture particular types of information.
These studies reveal a consistent pattern.
Early Layers
Early layers capture low-level acoustic features, such as:
- pitch
- energy
- spectral patterns
These representations resemble the information captured by traditional signal processing techniques.
Middle Layers
Middle layers tend to represent phonetic information, including:
- phonemes
- syllables
- pronunciation patterns
This is often where the model's representations are most useful for speech recognition tasks.
Higher Layers
Higher layers capture more abstract linguistic structure, including:
- word-level information
- semantic context
- longer linguistic dependencies
In effect, the model builds increasingly abstract representations as information flows through the network.
A Small Experiment: Visualizing Speech Embeddings
To better understand how self-supervised models organize speech internally, I ran a small experiment using the pretrained wav2vec 2.0 base model.
For a small dataset of Igbo speech recordings, I performed the following steps:
- Passed each waveform through the wav2vec model.
- Extracted the hidden representations produced by the Transformer encoder.
- Averaged the representations across time to obtain a single embedding vector for each audio recording.
- Applied Principal Component Analysis (PCA) to project the embeddings into two dimensions for visualization.
This allows us to visualize how the model groups speech signals in its learned representation space.
https://colab.research.google.com/drive/1q9q3Vi5H3z_mhrHqH2KerhINEJtB1CT_?usp=sharing
Adjusting the Experiment
Initially, I attempted to visualize embeddings using only multiple variations of the same word.
However, this produced weak separation in the PCA visualization. This outcome is not surprising: recordings of the same word often share very similar acoustic characteristics, especially when spoken by the same speaker.
To make the experiment more informative, I expanded the dataset to include several different words, while still including multiple recordings of the same word.
This allowed clearer patterns to emerge in the embedding space.
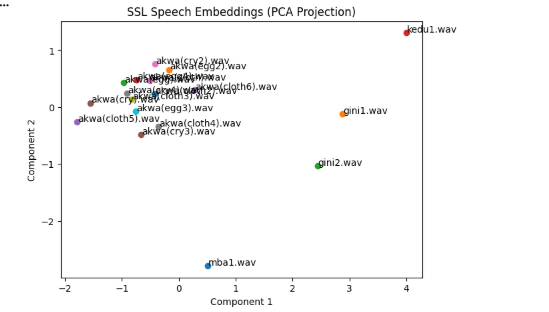
What the Visualization Revealed
The PCA projection revealed a meaningful structure in the learned embeddings.
Several recordings of the word “akwa” appeared clustered together, indicating that the model captured their shared phonetic structure.
Similarly, the two recordings of “gini” appeared close together in the embedding space.
The word “kedu” appeared farther from these clusters, while “mba” appeared isolated in another region of the visualization.
These patterns suggest that the model organizes speech embeddings based on acoustic and phonetic similarity.
Words that share similar sound structures tend to appear closer together, while acoustically distinct words are placed farther apart.
Even with a small dataset, this experiment provides an intuitive glimpse into how self-supervised speech models internally represent spoken language.
Why Self-Supervised Learning Matters for Low-Resource Languages
Self-supervised learning is particularly important for languages with limited annotated datasets.
Because these models can be trained on unlabeled audio, it becomes possible to build speech systems using large collections of recordings such as:
- radio broadcasts
- podcasts
- community speech recordings
- conversational audio
Only a relatively small labeled dataset is then required to fine-tune the system for tasks like speech recognition.
For many underrepresented languages, this approach may be the most practical path toward building robust speech technology.
From Signal Processing to Representation Learning
Across this series, we have gradually moved from signal-level representations toward neural representation learning.
Earlier techniques relied on carefully designed features such as:
- MFCCs
- pitch
- formants
- spectral descriptors
Self-supervised learning shifts this responsibility to the model itself.
Instead of manually designing features, we allow the model to discover them automatically from large collections of speech data.