Understanding the Structure of Speech Beyond Spectra
In the previous articles we gradually built the signal processing foundation of Speech AI.
Yesterday we took this perceptual representation and made it even more compact using Mel Frequency Cepstral Coefficients (MFCCs). MFCCs summarize the spectral envelope of speech, which largely reflects the shape of the vocal tract during speech production.
However, speech carries much more information than spectral envelopes. When humans speak we also communicate through pitch patterns, vocal tract resonances, and rhythm. These characteristics convey meaning, emotion, emphasis, and sometimes even grammatical structure.
Today we explore three fundamental properties of speech signals that go beyond spectral representations: pitch, formants, and prosody. These elements are especially important for languages like Yoruba, Hausa and Igbo, where variations in pitch directly change the meaning of words. Below is an example a an igbo word "akwa" meaning 3 different things, to cry, a cloth, an egg; all depending on how it is being said
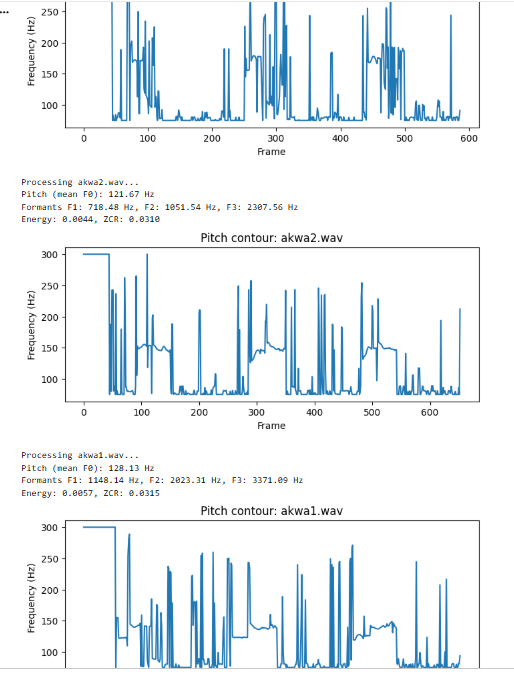
(https://colab.research.google.com/drive/119g2Y5CwvhOvHU9NOZEMcz6w-LYd-7Jd?usp=sharing)
Pitch: The Fundamental Frequency of the Voice
When humans produce voiced sounds, the vocal cords inside the larynx vibrate. This vibration periodically interrupts the airflow coming from the lungs, creating a repeating pressure pattern in the air.
The rate at which the vocal cords vibrate determines the fundamental frequency, usually written as F0 (pronounced “F zero”).
Fundamental frequency simply measures how many vibration cycles occur each second.
If the vocal cords vibrate 120 times per second, then the pitch of the sound is F0 = 120 Hz
Different speakers typically produce different pitch ranges. Adult male voices often fall roughly between 85 and 180 Hz. Adult female voices commonly range between about 165 and 255 Hz, while children often produce even higher pitch values.
The vibration of the vocal cords does not produce just a single frequency. Instead it produces a harmonic series. If the fundamental frequency is F0, additional frequencies appear at integer multiples of that value.
For example, if the fundamental frequency is 120 Hz, then energy also appears at:
120 Hz
240 Hz
360 Hz
480 Hz
These multiples are called harmonics. They form the source signal of voiced speech.
However, the sound we hear is not determined by pitch alone. As the harmonic signal travels through the vocal tract, it is filtered and shaped by the mouth, tongue, and lips. This filtering process is what gives speech its recognizable phonetic structure.
Why Pitch Matters in Speech
Pitch plays several roles in speech communication.
First, it contributes to intonation, which is the rise and fall of pitch across a sentence. Intonation can signal whether a sentence is a question or a statement.
Second, pitch helps convey emotion. Excited speech often has higher and more dynamic pitch patterns, while calm speech may have flatter pitch contours.
Third, pitch can carry lexical meaning in tonal languages.
Yoruba is a tonal language, meaning the pitch pattern of a word can change its meaning even if the consonants and vowels remain identical.
Consider the Yoruba word sequence involving the syllable “oko”.
The word ọkọ́ with a high tone refers to “husband”.
The word ọ̀kọ̀ with low tones refers to “farm”.
The word okò can refer to “vehicle”.
The difference between these words is not the consonants or vowels. The difference lies primarily in the pitch contour.
For this reason, accurately extracting pitch from speech signals is extremely important when building speech recognition systems for tonal languages.
Estimating Pitch from Speech
Although pitch originates from vocal cord vibration, it is not directly obvious from the waveform. Speech signals are complex and contain noise, harmonics, and non periodic components.
Pitch tracking algorithms attempt to estimate the fundamental frequency from the signal.
One classical approach is the autocorrelation method.
Autocorrelation works by measuring how similar a signal is to a delayed version of itself. If a signal repeats every T samples, then shifting the signal by T samples will produce a strong similarity.
Mathematically, the autocorrelation function can be written as: R(τ) = Σ x[n] x[n − τ]
Here x[n] is the signal and τ represents a time delay.
If a waveform repeats every 10 milliseconds, the autocorrelation function will show a peak at that delay. From the period T we can compute the fundamental frequency using: F0 = 1 / T
More advanced algorithms improve upon this idea. The YIN algorithm uses a difference function instead of correlation to reduce common pitch detection errors. Modern systems sometimes use neural network based approaches such as CREPE, which learn to estimate pitch directly from audio data.
The output of these algorithms is typically a pitch contour, which shows how the fundamental frequency changes over time.
Formants: Resonances of the Vocal Tract
Pitch describes the vibration of the vocal cords, but the human voice is shaped by something else as well. The vocal tract, which includes the throat, tongue, mouth, and nasal cavities, acts as a resonating acoustic filter.
When the harmonic sound produced by the vocal cords travels through the vocal tract, certain frequencies are amplified more strongly than others.
These amplified frequencies are called formants.
Formants appear as peaks in the spectral envelope of speech.
The first three formants are usually the most important and are labeled F1, F2, and F3.
Typical approximate ranges might be:
F1 between roughly 300 and 900 Hz
F2 between roughly 900 and 2500 Hz
F3 between roughly 2500 and 3500 Hz
The exact values depend on the position of the tongue and lips.
Formants play a crucial role in determining vowel identity. For example, the vowel sound “ee” as in “see” typically has a low first formant and a very high second formant. The vowel sound “ah” has a much higher first formant and a lower second formant.
Because of this, plotting F1 against F2 can often reveal the vowel space of a language.
Speech systems can estimate formants using techniques such as Linear Predictive Coding (LPC). LPC models the speech signal as the output of a filter that approximates the resonances of the vocal tract. By analyzing the coefficients of this filter, we can estimate where the resonant peaks occur.
Prosody: The Rhythm and Flow of Speech
While pitch and formants describe physical aspects of sound production, speech also contains patterns related to timing, stress, and emphasis. These patterns are collectively known as prosody.
Prosody includes properties such as speaking rhythm, pitch movement across phrases, variations in loudness, and differences in speech rate.
Prosodic cues help listeners interpret the structure and meaning of speech. A single sentence can convey different meanings depending on which word is emphasized or how the pitch rises and falls.
In computational speech processing, prosody is often captured using relatively simple features.
One common feature is energy, which measures the power of the signal in a short time frame. High energy typically corresponds to louder speech, while low energy often indicates pauses or softer sounds.
Another feature is the zero crossing rate (ZCR).
This measures how frequently the signal waveform crosses the zero amplitude line. Sounds such as “s” or “f” tend to have high zero crossing rates because they contain rapid oscillations, while vowel sounds usually have lower values.
Pitch contours also serve as important prosodic features because they capture the melodic pattern of speech over time.
Connecting the Full Speech Representation Pipeline
Across the last five days we have built a layered understanding of how speech signals are analyzed.
We began with raw air pressure vibrations that were sampled into a digital waveform. Using the Short Time Fourier Transform we converted this waveform into a time frequency representation known as a spectrogram.
We then modified that representation to reflect human hearing by introducing Mel frequency scaling and logarithmic amplitude compression. MFCCs further compressed this perceptual representation into compact features that capture the spectral envelope of speech.
Today we added three additional dimensions of speech information: pitch, formants, and prosody.
Pitch describes the vibration rate of the vocal cords. Formants capture the resonances of the vocal tract that shape vowel sounds. Prosody describes the rhythm, emphasis, and melodic patterns of speech.
Together, these elements provide a much richer description of spoken language.
Why These Features Matter for Speech AI
Machine learning models for speech must learn patterns that correspond to linguistic meaning. Spectral features such as MFCCs capture the overall shape of the vocal tract filter, which helps distinguish phonemes.
However, many linguistic cues lie beyond spectral envelopes. Pitch patterns carry tone in languages like Yoruba. Formants distinguish vowel qualities. Prosodic features capture emphasis, rhythm, and emotion.
By incorporating these features into speech processing pipelines, we can build systems that better reflect how humans actually produce and perceive spoken language.
Understanding these signal properties is a key step toward building speech technologies that work well not only for globally dominant languages, but also for underrepresented languages across Africa.