Before we build voice clones, ASR systems, or deploy AI that understands Yoruba tones… we must first answer a deceptively simple question: What is sound and how does a machine hear it?
Without the understanding of the physics of sound, our Speech AI intuition will be weaker. Even if modern deep learning handles raw waveforms end-to-end, knowing why the signal looks the way it does will make debugging and research much easier.
We will see what sound really is, How we hear sound, How sounds are digitalized.
Sound is not an MP3 or WAV file, those are just data. Real sound exists in the physical world.
“Sound is movement” But movement of what? Air
More precisely: Sound = vibration of air pressure over time

Let’s break down each term:
How Vibration Produces Sound
When something vibrates:
So when you hit a drum or clap your hands you are essentially disturbing the air pressure which is actually vibrating air molecules which in turn vibrates surrounding air molecules(how it travels) like a ripple in water.
Important: The air molecules themselves don’t move far; the pressure wave moves through them, like a ripple in water.
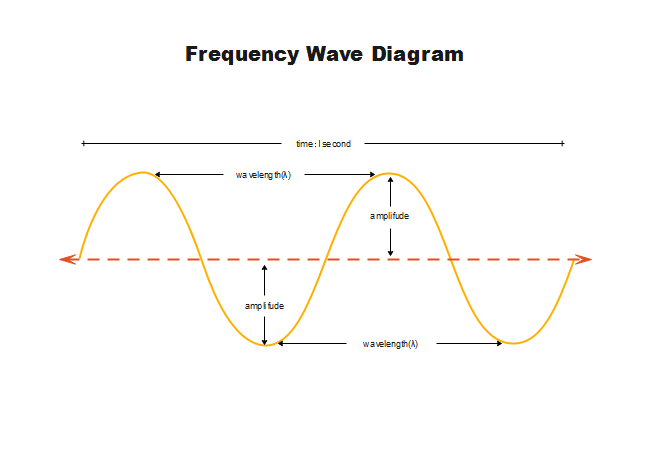
Example: When you speak, your vocal cords vibrate about 100–300 times per second (Hz), giving your voice its pitch.
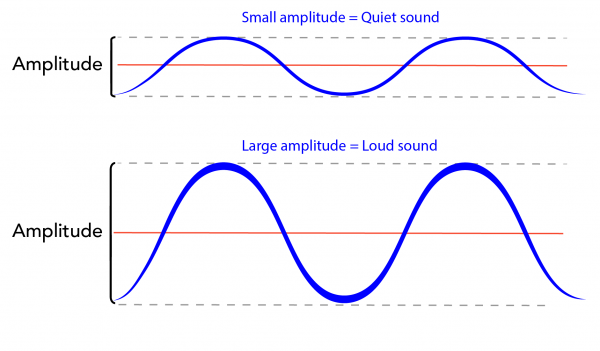
Think of it as: The difference between whispering and shouting.
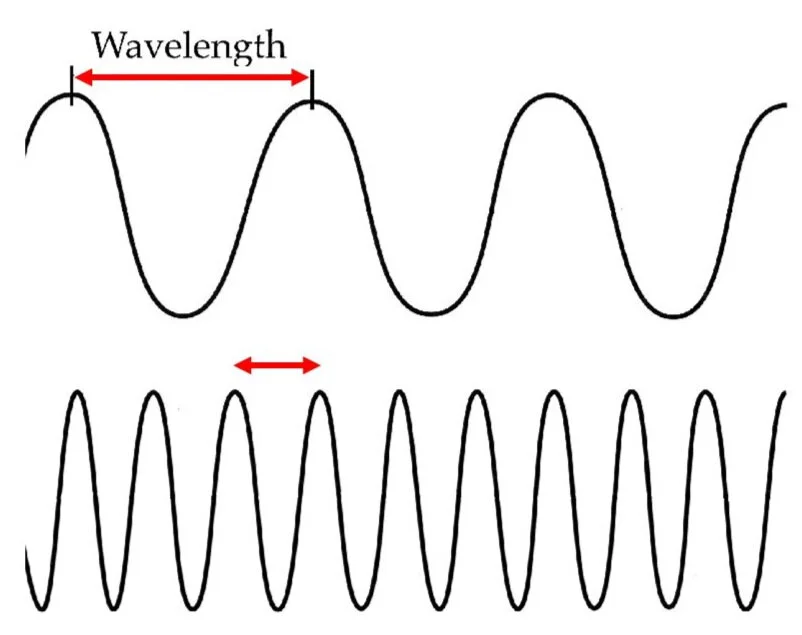
Think of it as: The “spacing” of the sound waves traveling through air.

Think of it as: The “color” or “texture” of the sound, what makes your voice or an instrument recognizable.
Note: A good way to understand this better is trying out this interactive tool https://academo.org/demos/virtual-oscilloscope/
Key idea: The eardrum vibrates exactly like the air pressure waves that hit it—high pressure → pushes eardrum in, low pressure → pulls it out.
Digitalization is the process of turning the continuous vibrations of air into numbers that a machine can process. Think of it as translating the language of air pressure into the language of computers.
But computers do not understand: air, pressure, smooth motion. Computers understand Numbers.
So the question becomes: How do we turn smooth air vibrations into numbers? This is what digitalization does. Digitalization translates: Air pressure → Measurements → Numbers → Binary
Digitizing sound involves three major transformations:
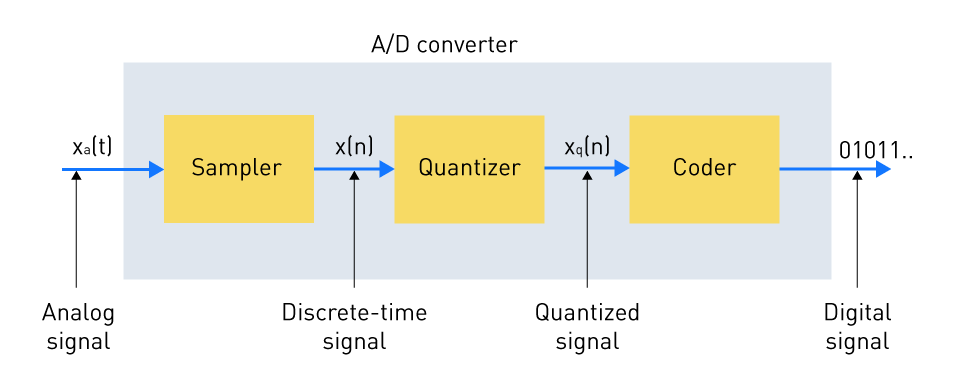
Let’s go step by Step.
Real motion is continuous, If someone waves their hand, the motion flows smoothly.
But a video is NOT continuous motion. A video is many pictures taken quickly. Example: If you take 24 pictures per second and play them fast…
Your brain sees: smooth motion even though it's just snapshots.
So: Real motion → snapshots → video
Sound is Recorded the same way. Real sound is continuous air vibration
Air is moving smoothly all the time but a computer cannot capture every single moment, So instead… We take snapshots of air pressure just like a camera takes snapshots of motion.
Sound Sampling = Audio Snapshots
At tiny moments in time we ask: “How much is the air pushed right now?” So instead of storing the whole smooth wave… We store measurements. Like:
| Time | Air Pressure |
|---|---|
| t₁ | 0.3 |
| t₂ | 0.6 |
| t₃ | -0.2 |
| t₄ | -0.5 |
This becomes a list of values which describes the sound.
If we take 16,000 snapshots every second, just like: 24 frames/sec = video, here we do 16,000 samples/sec = audio
That means 16,000 Hz sampling rate which means that we check the air pressure 16,000 times every second. If we sample too slowly… We miss the shape of the vibration, just like how taking 1 photo per second cannot capture fast motion.
Nyquist Rule: This is the law that governs whether machines hear correctly… or hallucinate noise. It states that to capture a frequency, you must sample at least 2× that frequency.
Using video analogy: To capture motion smoothly, you must take at least 2 pictures per movement.
Same for sound, to capture a frequency F, you must sample at least 2F times per second. This is the Nyquist Rule
Human speech goes up to about 8,000 Hz, meaning air may vibrate 8,000 times per second. So to capture that properly, we must sample at least 2 × 8,000 = 16,000 samples/sec. That is why Speech systems use 16,000 Hz sampling rate.
If We Sample Too Slowly? Let’s say sound vibrates 8,000 times per second but we only sample 9,000 times per second we don’t capture enough detail. It’s like trying to film a fast fan with a slow camera. The motion looks wrong, this error is called Aliasing. Aliasing happens when sound is distorted, high-frequency sounds pretend to be lower ones so machines then misunderstand tone.

Imagine we sampled sound at one moment and got Air pressure = 0.623748292. This is a very precise real-world value but computers cannot store infinite precision, they must round it.
So intead of storing 0.623748292 we might store 0.62, that rounding is Quantization. So now Smooth reality → stepped values
In real life, air pressure can take any value. But in digital systems, we only allow certain loudness levels.
Example: Few Loudness Steps (Low Bit Depth)
Let’s imagine our system only allows 4 loudness levels. So instead of storing any value between 0 and 10… We only allow:
| Step | Allowed Value |
|---|---|
| 1 | 0 |
| 2 | 3.3 |
| 3 | 6.6 |
| 4 | 10 |
Now suppose real sound arrives:
| Real Loudness | Stored Value |
|---|---|
| 1.2 | 0 |
| 2.9 | 3.3 |
| 5.0 | 6.6 |
| 7.1 | 6.6 |
| 9.6 | 10 |
Notice: Small differences disappear
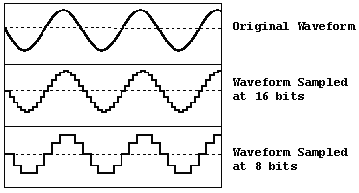
Example: 5.1 and 6.4 both become 6.6, So the smooth waveform becomes jagged. This causes Robotic sound, Telephone-like quality, Loss of subtle details. This error is called Quantization Noise
Example in Real Situations
More Loudness Steps = Better Sound
Now imagine instead of 4 steps… We allow 65,536 steps (16-bit audio)Now:
| Real Loudness | Stored Value |
|---|---|
| 4.21 | 4.209 |
| 4.44 | 4.441 |
| 4.62 | 4.621 |
Almost identical. So the digital sound feels smooth again.
Bit Depth = Number of Loudness Steps
Bit depth controls how many steps exist:
| Bit Depth | Loudness Levels |
|---|---|
| 2-bit | 4 levels |
| 3-bit | 8 levels |
| 8-bit | 256 levels |
| 16-bit | 65,536 levels |
| 24-bit | 16+ million levels |
More levels = smaller rounding = more natural sound
After quantization, we now have something like this:
| Time | Quantized Loudness |
|---|---|
| t₁ | 2.3 |
| t₂ | 1.8 |
| t₃ | -0.6 |
| t₄ | -2.0 |
But computers still cannot store these directly. Computers only understand 0 and 1
So we must translate each loudness level into binary. This final translation is called Encoding.
Remember: 16-bit gives us 65,536 possible loudness steps. So internally, the system labels them like:
| Loudness Step | Level Number |
|---|---|
| Lowest | 0 |
| Next | 1 |
| Next | 2 |
| ... | ... |
| Highest | 65,535 |
So instead of storing: "Air pressure = 0.62" We store: Level = 42,918
Now the computer translates: 42,918 → into 16-bit binary. Example: 42,918 = 1010011110100110
This is what actually gets stored. So the sound becomes:
| Time | Loudness Level | Binary Stored |
|---|---|---|
| t₁ | 42,918 | 1010011110100110 |
| t₂ | 31,220 | 0111101000100100 |
| t₃ | 12,004 | 0010111011010100 |
Now the sound is fully digital.
Full Pipeline Recap
Real Sound → Smooth vibration
Real Example: 16,000 Hz Audio
If we record speech: Sampling rate = 16,000 samples/sec, Bit depth = 16 bits
Each second becomes: 16,000 numbers. Each number uses: 16 binary digits. So 1 second of audio = 16,000 × 16 bits = 256,000 bits ≈ 32 KB per second. That’s why audio files have size. They are literally binary pressure snapshots.
Intuition
“Sound begins as vibration, disturbs air pressure, travels as a wave, is interpreted by our ears and brain, and can be captured or reproduced digitally as numbers.”
Summary
Quick Links