Smart RAG Document Assistant for Contextual Question Answering.
Professional RAG Document Assistant

Introduction
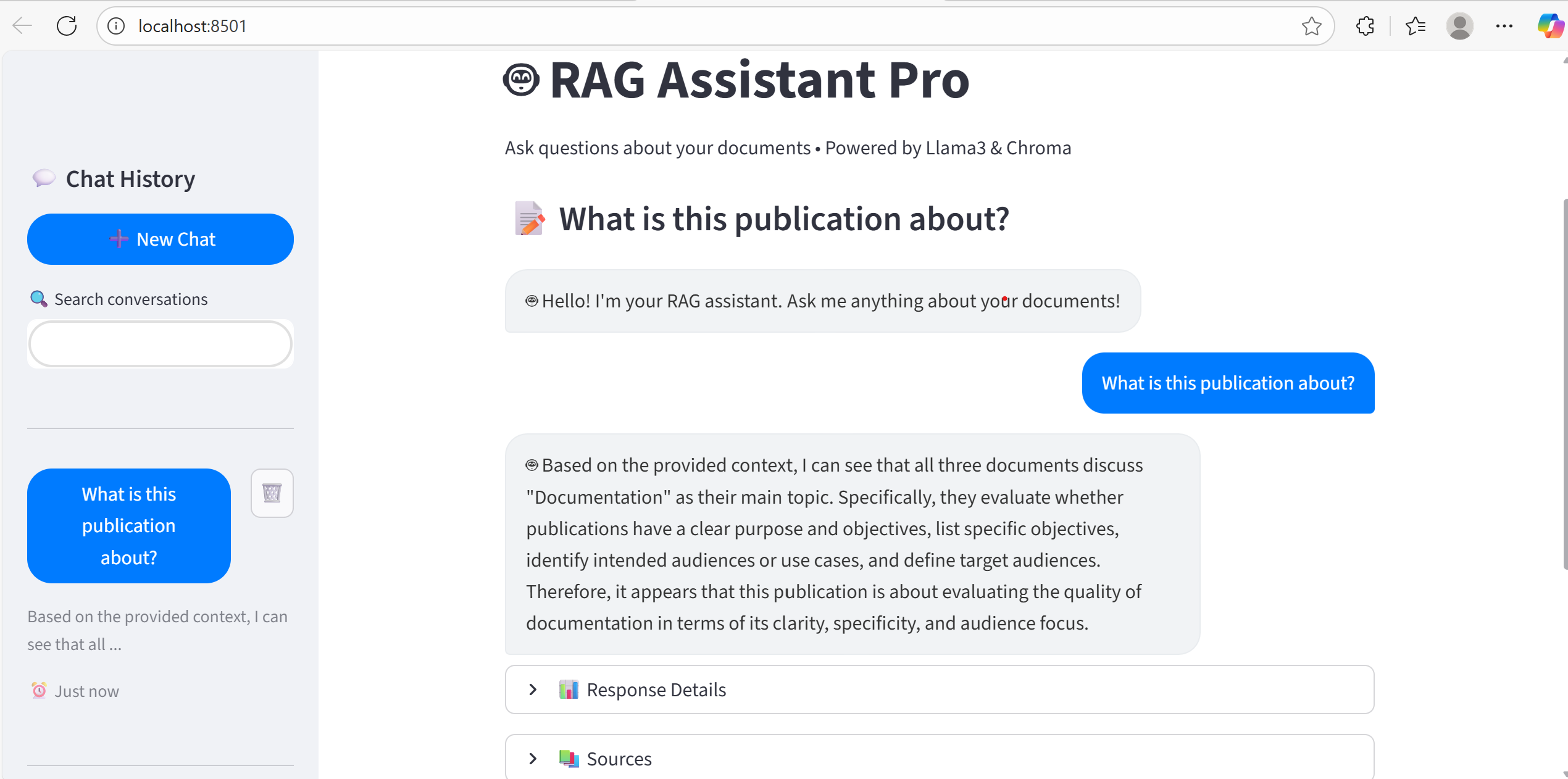
The RAG Document Assistant is an AI-powered system designed to make large document collections searchable and understandable. Instead of manually reading through hundreds of pages, users can simply ask questions and receive clear, context-aware answers.
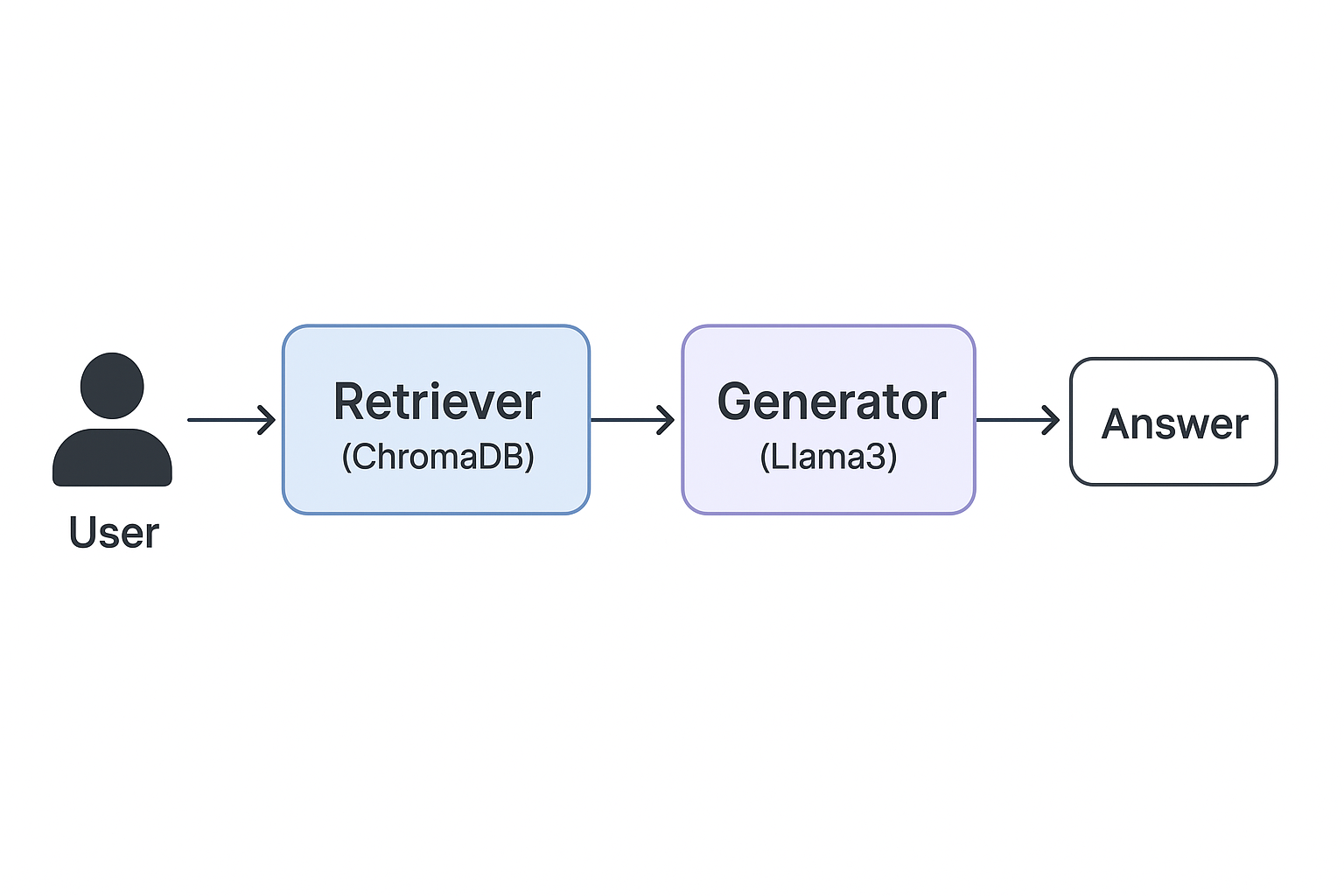
This assistant is built using a Retrieval-Augmented Generation (RAG) pipeline, which combines two powerful AI capabilities:
Retrieval: Finding the most relevant passages from documents using vector search.
Generation: Using a language model to answer the user’s question based on the retrieved content.
The goal of this project is to demonstrate how modern AI tools like LangChain, ChromaDB, and Ollama can be combined to create an intelligent, privacy-friendly, and production-ready assistant.
Methodology
The development process followed three main stages:
Document Processing
Input: mydoc.json containing 35+ documents (≈882KB).
Each document was split into small text chunks for better retrieval.
Embeddings were generated using the nomic-embed-text model.
The resulting vectors were stored in ChromaDB, a high-performance vector database.
Retrieval-Augmented Generation Pipeline
A retriever was configured to search top-3 most relevant chunks for each query.
Ollama Llama3 was used as the local language model to generate answers.
Contextual filtering ensures that out-of-scope questions are flagged (e.g., asking “What is the capital of Kenya?” when documents are about CPUs).
User Interfaces
Command-Line Interface (CLI) for quick testing.
Web Interface (Streamlit) with a professional ChatGPT-style design.
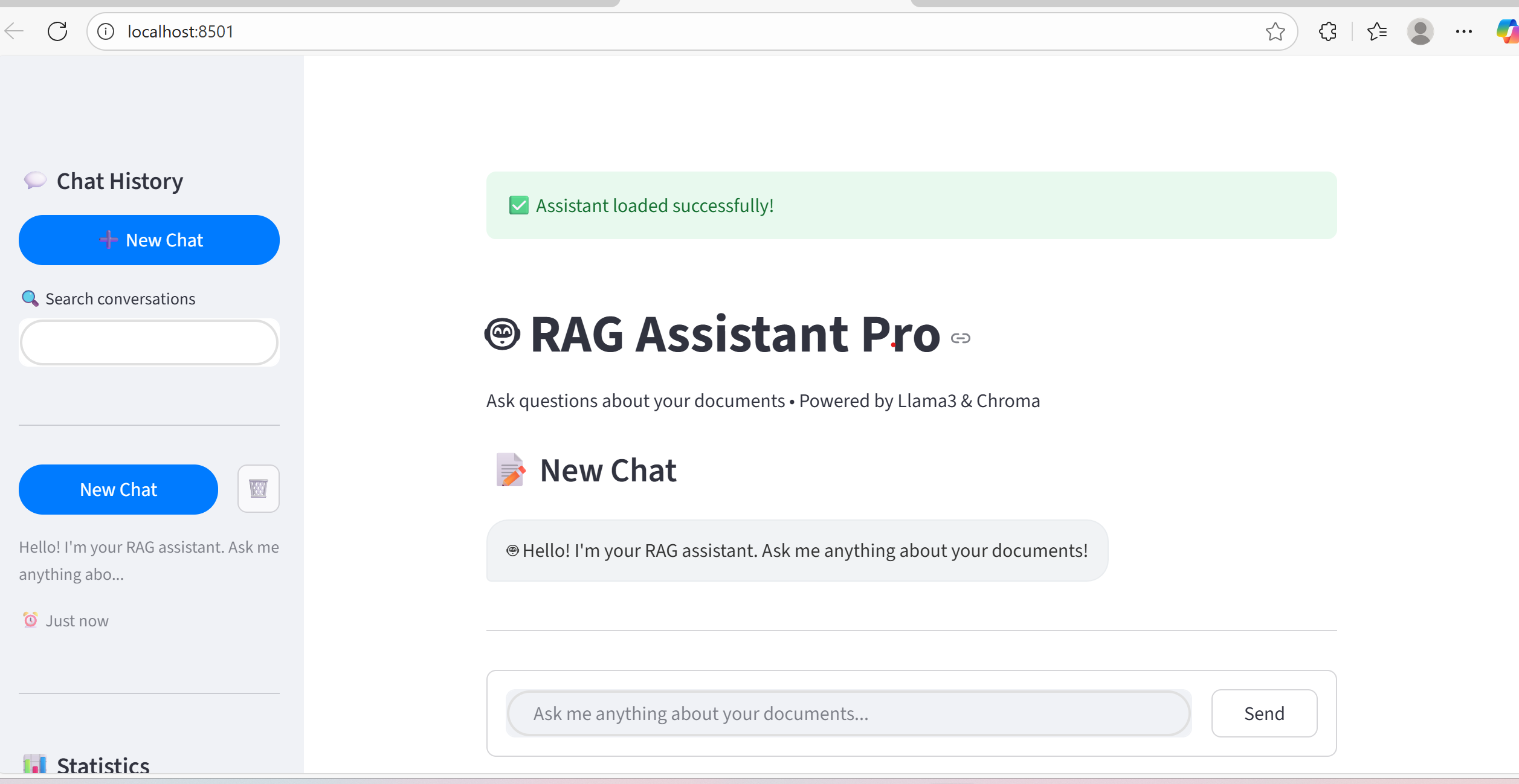
Features include conversation history, multi-chat management, real-time typing indicators, and export options.
Results
The final system demonstrates strong performance and professional usability:
Corpus Coverage: 35 documents successfully ingested → 1,783 searchable chunks.
Query Accuracy: Retrieves semantically relevant answers with citations.
Response Speed: ~2–5 seconds on CPU; faster with GPU.
Educational Value: Clear example of how RAG systems are engineered for real-world applications.
User Experience: Modern web app with a clean, interactive interface.
Example queries tested:
“What is this publication about?” → returns clear summaries.
“What models or tools were used?” → identifies Llama3, ChromaDB, LangChain.
“What limitations are mentioned?” → highlights challenges in clarity and organization.
Overall, the project achieves the core objective of making documents searchable, understandable, and interactive through an advanced AI-driven assistant.