BigQuery has a RAG system using vector search. To see how good this vector search is
I decided to build a RAG system with BigQuery using a chat framework called Slack Bolt.
First, install gcloud using curl.
curl -sSL https://sdk.cloud.google.com | bash && exec -l $SHELL && gcloud init
Then, log in with gcloud.
gcloud auth login
To set the project ID in the gcloud command-line tool, you need to replace {project_id} with your actual Google Cloud project ID.
You can find your Project ID on the Google Cloud Welcome page.
※Check welcome google cloud
The correct command is:
gcloud config set project PROJECT_ID
For example, if your project ID is my-awesome-project-123, you would run:
gcloud config set project my-awesome-project-123
This command sets the active Google Cloud project for all subsequent gcloud commands.
Next, you will set up Application Default Credentials (ADC).
gcloud auth application-default login
This completes the setup. / The setup is now complete.
Set the PROJECT_ID environment variable.
export PROJECT_ID=`gcloud config list --format 'value(core.project)'` && echo $PROJECT_ID
To run the Slack app, you need to set the following environment variables with your Slack app credentials. You can create a Slack app and obtain these tokens from the Slack API: Applications page.
export SLACK_APP_TOKEN= export SLACK_BOT_TOKEN= export SLACK_SIGNING_SECRET=
Create WebPageSummarizer app on Slack.
WebPageSummarizer and select your workspace.Signing Secret. Copy it and set it as the SLACK_SIGNING_SECRET environment variable.app_mentions:readchat:writeim:readchannels:historygroups:historyim:historympim:historyhttps://your-domain.com/slack/events (you will need to set up a server to handle this).app_mentionmessage.channelsmessage.groupsmessage.immessage.mpimAPP_ENVIRONMENT is an environment variable that changes the execution state of the application. If a value other than prod is set, the Slack application will be launched in Socket Mode.
In this case, we will set APP_ENVIRONMENT to dev.
export APP_ENVIRONMENT=dev
export USE_MODEL_NAME=text-embedding-005 export USE_TEXT_MODEL_NAME=gemini-2.0-flash
To use BigQuery for storing and retrieving web page summaries, you need to set the following environment variables for the BigQuery dataset and table.
export BQ_DATASET=web_page_summarizer export BQ_TABLE=web_page_summaries
Create the BigQuery dataset and table using the following commands:
bq --project_id $PROJECT_ID mk --dataset $BQ_DATASET bq --project_id $PROJECT_ID mk --table $BQ_DATASET.$BQ_TABLE
cd docker pip install -r requirements.txt
python app.py
@WebPageSummarizer What are the new AI-powered tools announced at Google Cloud Next '25? https://iret.media/150057
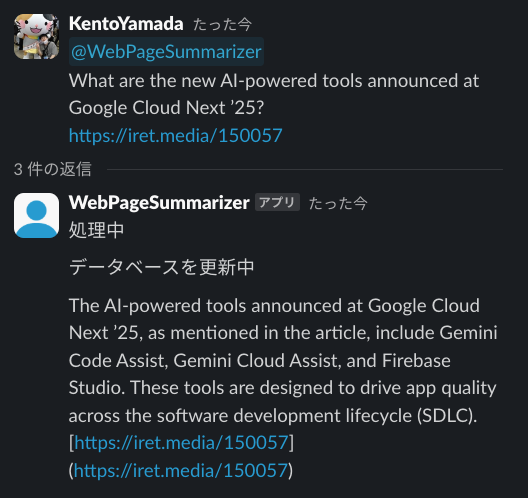
This project demonstrates how to build a Slack bot that utilizes BigQuery's vector search capabilities for retrieving and summarizing web page content. By following the steps outlined above, you can set up your own Slack app, configure it to interact with BigQuery, and deploy it to Google Cloud. This setup allows for efficient retrieval of information and provides a foundation for further enhancements and features in your Slack bot.
As the amount of data increases, BigQuery's vector search tends to take more time. This is because a larger dataset requires more processing time for searches.
To address this, you can classify data into appropriate tables or use agents with MCP or A2A to narrow down the search scope based on content.
Specifically, consider the following approaches:
Data Classification: Divide data into different tables by category to narrow the search scope. For example, store news articles, blog posts, and product reviews in separate tables.
Use of Indexes: BigQuery allows you to create indexes on tables, which can speed up searches on specific columns. Setting indexes on frequently searched columns is especially effective.
Query Optimization: Optimize your queries to reduce search time. For example, select only the necessary columns, add filtering conditions, or use subqueries to reduce the amount of data processed.
Partitioning: Partition data by time or other criteria to reduce the amount of data searched. This allows you to search only the data that matches a specific period or condition.
Use of Agents: Create agents using MCP (Multi-Cloud Platform) or A2A (Agent-to-Agent) to narrow the search scope based on specific content. This enables searching only the most relevant data for a user's query.
Caching: Implement caching mechanisms to store frequently accessed data, reducing the need for repeated searches in BigQuery.