Single Object Detection
Table of contents
Abstract
Single Object Detection is a core technique in computer vision aimed at recognizing and localizing a single object within an image or video frame. This approach is widely applicable in fields such as surveillance, medical diagnostics, autonomous navigation, and robotics. By focusing on only one object, the computational complexity is reduced, making it suitable for real-time or resource-constrained environments.
Methodology
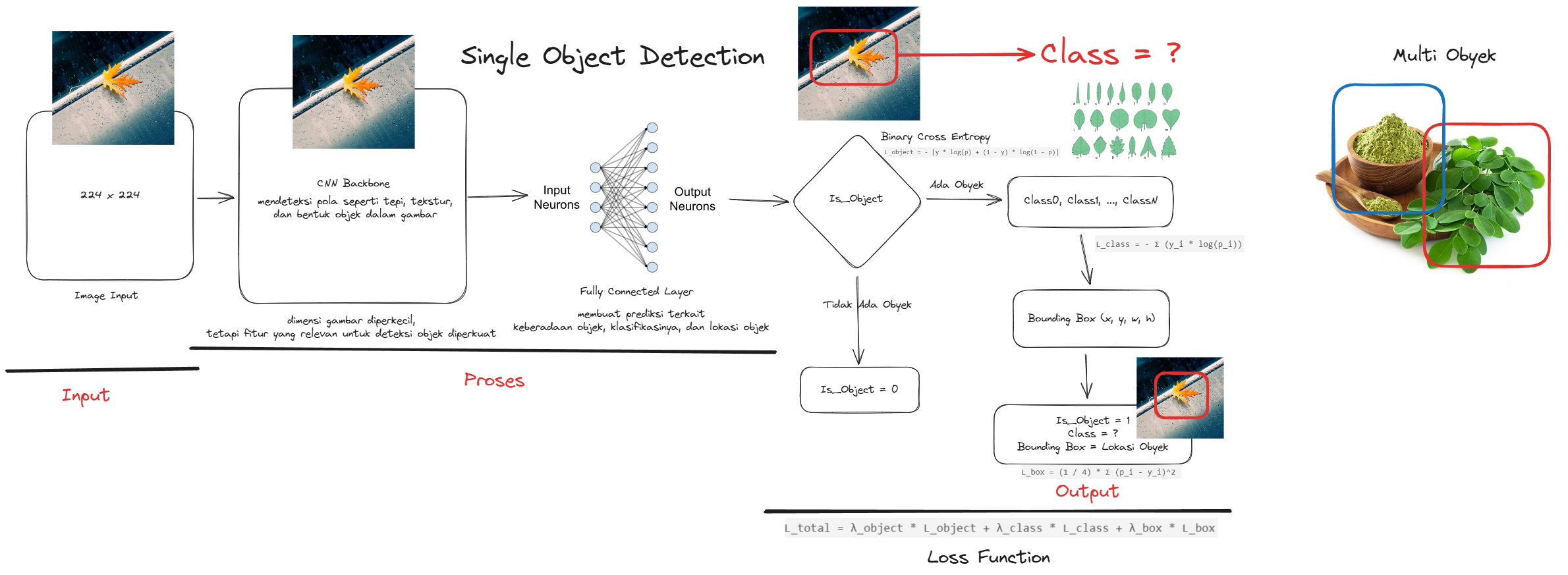
The object detection process consists of several key steps, as visualized in the diagram above:
-
Input Image
The system receives a static or dynamic image input (e.g., from a camera or uploaded file). -
Preprocessing
This step involves image normalization, resizing, and noise reduction to optimize it for the model. -
Object Detection
The preprocessed image is fed into a pre-trained deep learning model (e.g., YOLO, SSD, or Faster R-CNN) that predicts the presence and class of the object. -
Bounding Box Drawing
A rectangle (bounding box) is drawn around the predicted object, indicating its location. -
Output Visualization
The final image is rendered with bounding boxes and labels for user interpretation.
Tools and Platforms
- Ngrok: Tunnels localhost applications for remote access testing.
- Hoppscotch: Easy-to-use API testing tool for evaluating endpoints.
- Base64 to Image Converter: Converts base64 strings into downloadable image formats.
Results
The system successfully detects a single object in input images and returns annotated outputs with bounding boxes and classification labels. This process can be deployed using lightweight server tools and tested via API platforms.
A full implementation example, including diagram and codebase, can be accessed via the GitHub repository below:
🔗 https://github.com/Muhammad-Ikhwan-Fathulloh/Single-Object-Detection