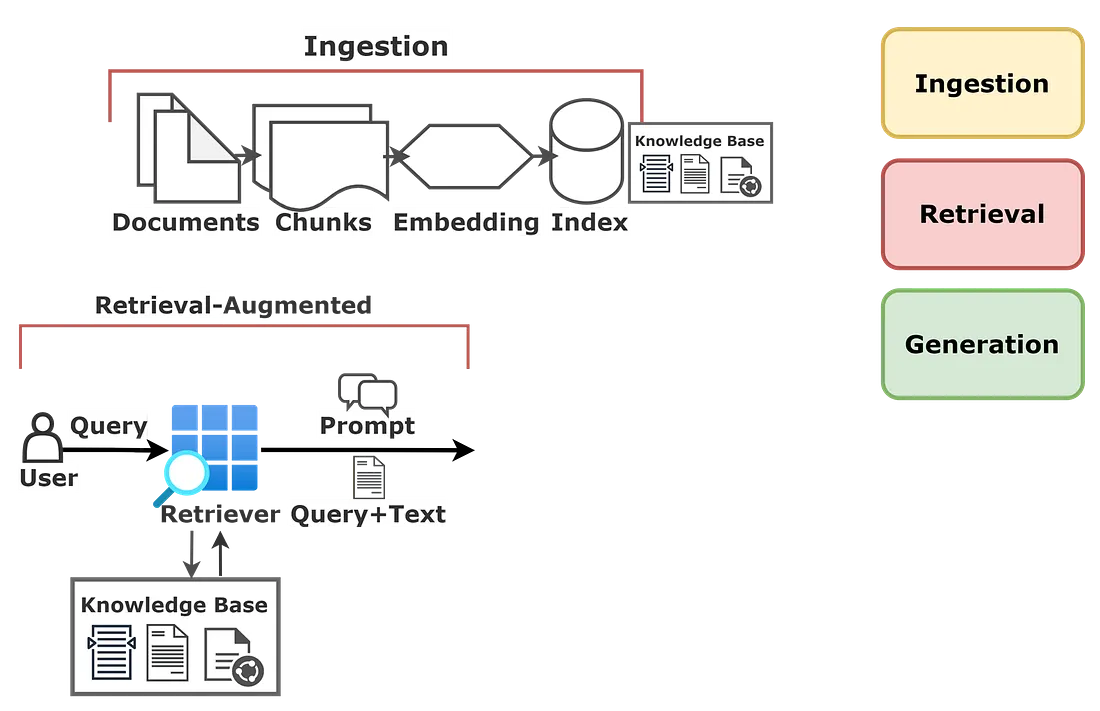
This document presents the technical architecture for a compact, production-ready Retrieval-Augmented Generation (RAG) system. It details the essential components required to answer user queries that are grounded in a private document corpus. The system architecture is designed for accuracy and scalability, featuring a chunk-based vector DB for retrieval, a robust system prompt to constrain the Groq LLM, and a summarization-based memory manager to maintain conversational coherence.
The purpose of this publication is to provide a technical blueprint for a robust, production-grade Retrieval-Augmented Generation (RAG) system. This document outlines the core architecture, component responsibilities, and data flows necessary to build a service that can answer questions by retrieving relevant information from a specified document corpus. This publication is an Applied Solution Showcase, focusing on the technical architecture, implementation methodology, and key engineering decisions for building this system.
Large Language Models (LLMs) are powerful but often "hallucinate" or invent information. This makes them unreliable for tasks requiring high factual accuracy based on specific, private knowledge (e.g., enterprise documentation, legal texts, or technical manuals). A RAG system mitigates this risk by augmenting the LLM with a retrieval step. Before answering a query, the system finds relevant passages from a trusted document corpus and passes them to the LLM as context. This grounds the LLM's response in verifiable facts, significantly improving accuracy and allowing the system to cite its sources.
This section details the technical components and their responsibilities. The design emphasizes a separation of concerns, making the system easier to build, maintain, and scale.
The single entry point for all end-user interaction. Receives user requests (handling both single-turn queries and conversational chat). Manages authentication and authorization (e.g., API keys, user tokens). Enforces rate limiting to protect system resources. Logs requests and responses for telemetry and monitoring.
An asynchronous (offline) process responsible for populating the knowledge base. Accepts raw documents in various formats (PDF, HTML, TXT, etc.). Normalizes and cleans the text content. Splits large documents into smaller, semantically meaningful chunks. Computes vector embeddings for each chunk using a chosen embedding model. Writes the chunk embeddings and their corresponding text/metadata to the Vector DB.
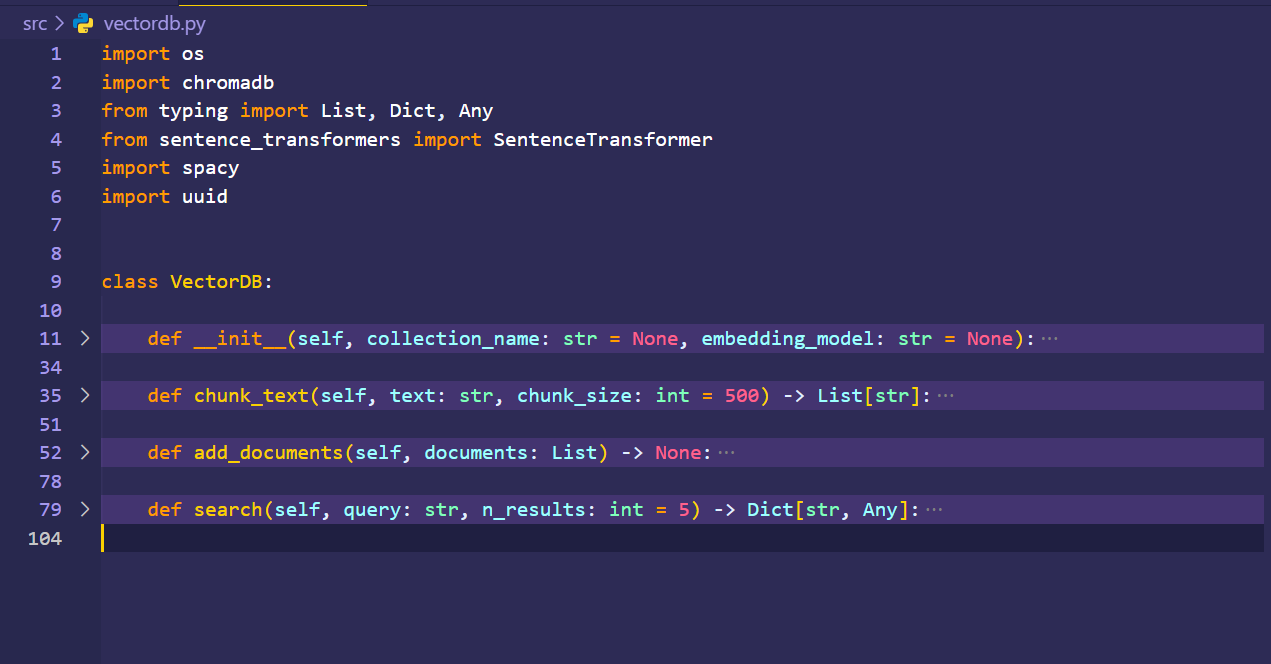
The core knowledge base of the system, storing all document chunks. Stores document chunk embeddings and associated metadata (e.g., source document, page number). Provides efficient k-Nearest Neighbor (k-NN) search to find chunks semantically similar to a query. Supports metadata filtering to narrow search results (e.g., "find answers only in 'document_X.pdf'").
The service that fetches relevant context from the Vector DB. Receives the user's query and generates a query embedding. -Executes the semantic search against the Vector DB. Returns the top-K most relevant document chunks, often with their relevancy scores.
A critical logic component that builds the final prompt for the LLM. Builds the prompt from multiple sources. A strong directive that constrains the LLM's behavior (e.g., "You are a helpful assistant. Answer ONLY based on the provided context...").The document chunks from the Retriever. The conversation summary and recent messages from the Memory Manager. The user's latest question. Manages the token budget by truncating or prioritizing context to fit within the LLM's context window.
A dedicated client for interfacing with the high-speed Groq API. Sends the fully assembled prompt to the Groq LLM API. Receives the generated text response. Handles API-specific logic, such as connection retries and timeouts.
A stateful service (e.g., using Redis) that maintains conversational context. Stores recent raw interactions (user message, LLM answer) for each session. Asynchronously (or on-demand) uses the LLM to create a running summary of the conversation. Provides both the recent messages and the compressed summary to the Context Assembler, enabling long-term coherence without exceeding the token limit.
A final step to clean and format the LLM's raw output. Parses the LLM response to add citations (linking the answer to the source document chunks). Enforces safety rules or content moderation.
This section describes how the components interact during primary operations.
A user uploads a document (e.g., manual.pdf) via the API Layer. The Ingestion Pipeline picks up the document. The pipeline splits the document into 50 chunks. It generates an embedding for each chunk. Each chunk (text, metadata, and embedding) is written to the Vector DB.
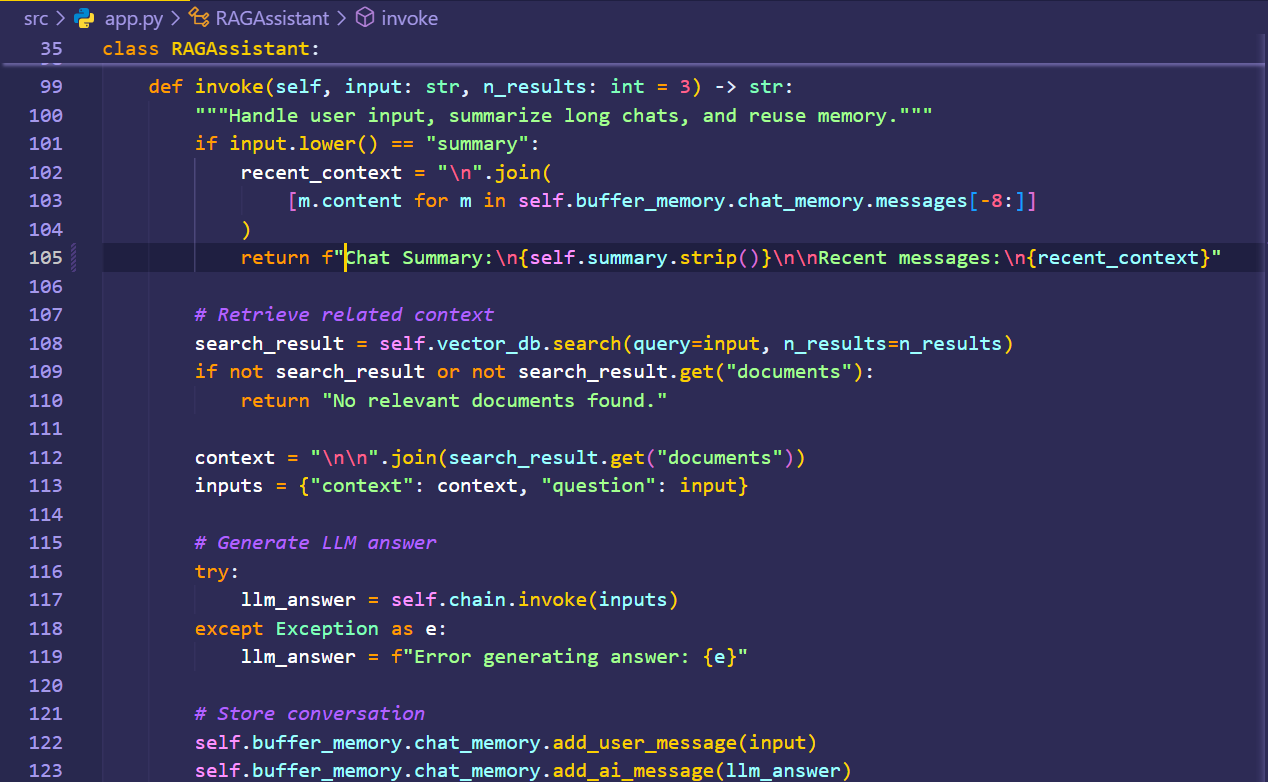
A user sends a query: "How do I reset the frobnicator?" via the API Layer. The Retriever generates an embedding for this query and fetches the top 3 relevant chunks from the Vector DB. The Memory & Summarization Manager is queried. It provides the most recent raw messages and the current conversation summary (e.g., "User asked what a frobnicator is..."). The Context Assembler builds the final prompt, including the system prompt, summary, recent messages, retrieved chunks, and the new query. The Groq LLM Connector sends this prompt to the Groq API. The API Layer returns the final, formatted answer to the user. -The Memory & Summarization Manager saves this new interaction and updates its summary.
The Context Assembler builds the final prompt, including the system prompt and the new query. The Groq LLM Connector sends this complete prompt to the Groq API. The LLM responds. The Post-Processor validates the response and adds citation metadata. The API Layer returns the final, formatted answer to the user. The Memory & Summarization Manager saves this new interaction and updates its summary.
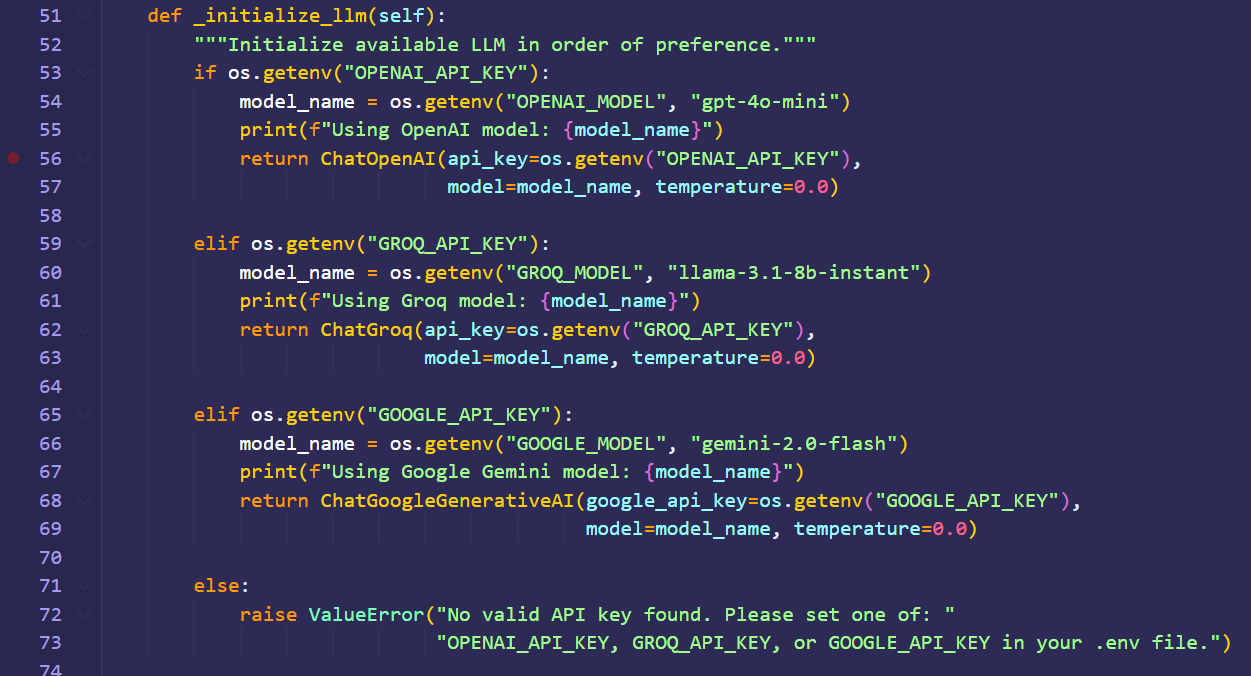
LLM is selected based on the available api key. The implementation is given below.
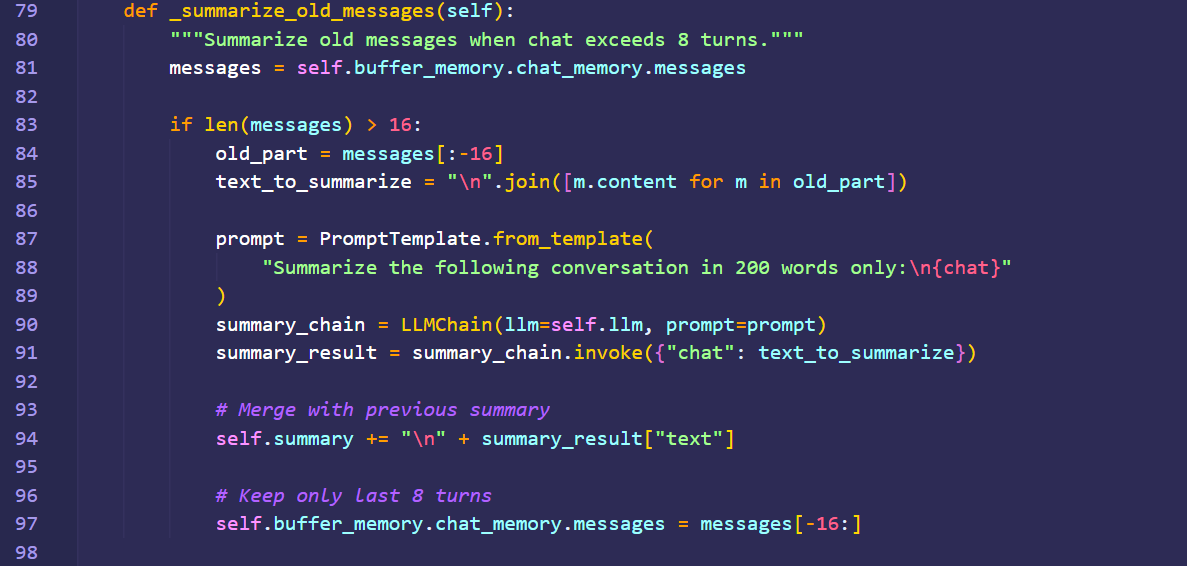
To maintain conversational context over a long interaction, this system employs a memory summarization technique. Instead of just storing the last few messages, the Memory & Summarization Manager actively condenses the history. After an interaction, the user's query and the LLM's full response are processed. The system uses an LLM to create or update a running summary of the conversation. This compressed summary, which captures the key entities and topics discussed, is then saved. In subsequent turns, this summary is passed back to the Context Assembler along with the most recent raw messages, allowing the RAG system to remember the entire conversation's history without exceeding the LLM's token limit.
Regular updates are performed every 2–3 weeks to ensure the system incorporates the latest improvements, bug fixes, and compatibility updates with LLMs and vector store libraries.
Users can access support through the project’s GitHub repository, dedicated email support at
malikshahzaibkharal1199@gmail.com
Planned releases include incremental improvements to the retrieval-augmented generation (RAG) system, optimization of embeddings, integration with new LLM models, and performance enhancements. Updates will focus on bug fixes and optimizations.
The embedding model used is sentence-transformers/all-MiniLM-L6-v2, chosen for its ability to generate high-quality semantic embeddings while maintaining low computational cost and fast inference times, making it ideal for real-time applications. Its compact size ensures efficient storage and enables rapid vector similarity searches within the RAG pipeline. This model is particularly effective for semantic similarity searches across document collections, as its dense embeddings capture contextual relationships between sentences, improving the accuracy of retrieval for the RAG assistant and producing more relevant and precise responses.
The vector store used is ChromaDB, selected for its simplicity, support for local storage, and cost-effectiveness. ChromaDB enables persistent vector storage directly on the local filesystem, allowing easy deployment without relying on cloud infrastructure. Furthermore, it provides fast indexing and querying capabilities, ensuring low-latency retrieval, which is essential for real-time conversational systems like the RAG assistant.
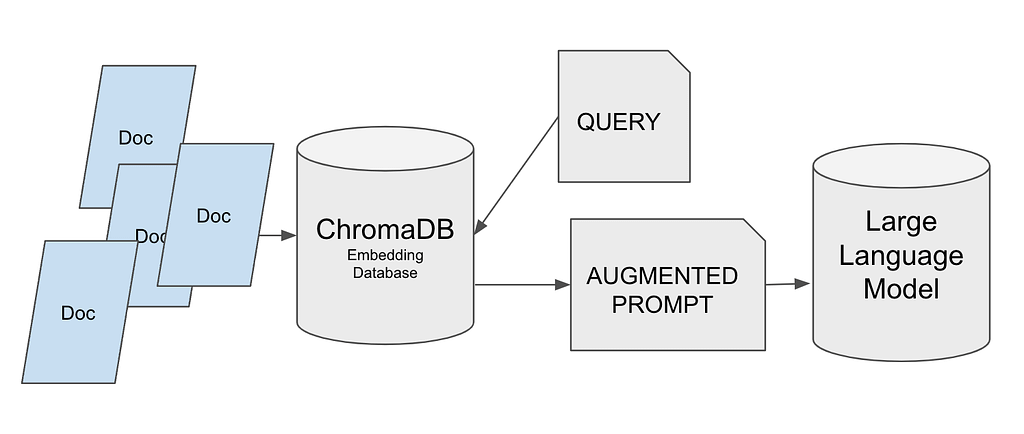
The LLM used is Groq LLM ,chosen for its high throughput, low latency, and cost efficiency compared to other large language models. It is optimized for rapid inference, ensuring faster response times in real-time applications, making it ideal for interactive systems where user experience depends on quick responses. Additionally, Groq LLM offers competitive pricing while delivering high-quality generative capabilities and can efficiently handle multiple concurrent requests without performance degradation, providing excellent scalability for production environments.

A simple "fixed-size" chunking method may split text in awkward places (e.g., mid-sentence), reducing the quality of retrieved context. The "Top-K" retrieval is not perfect. It may miss relevant context (low recall) or include irrelevant context (low precision), which can confuse the LLM. The conversation summary may be slightly out-of-date if it is generated asynchronously, which could briefly impact coherence in a rapid-fire conversation.
Implement strategies like sentence-aware or agentic chunking to create more semantically coherent context blocks .Add a "re-ranker" model after the Retriever to re-score the top-K chunks for a more nuanced relevance, improving precision. Implement logic to break down complex user queries ("compare X and Y") into multiple, simpler sub-queries for the retrieval system.