This project implements a simple Retrieval-Augmented Generation (RAG) assistant specifically designed for educational purposes. It achieves its goals without relying on external APIs, GPU resources, or complex deep learning frameworks, making it an accessible tool for understanding core RAG principles. The system demonstrates robust functionality by utilizing scikit-learn's TF-IDF vectorization for document representation, cosine similarity for efficient information retrieval, and an intelligent rule-based mechanism for generating contextually relevant responses.
The implementation successfully processes various text documents, transforms them into sparse vector representations, and performs similarity-based searches to gather pertinent information. It then crafts contextually appropriate answers by blending rule-based knowledge with the content of the retrieved documents. Key features of this system include automatic sample document creation for quick setup, comprehensive conversation history tracking, optional FAISS integration for enhanced performance, and detailed logging that fosters educational transparency. Requiring only Python's standard libraries alongside scikit-learn, this RAG assistant is an ideal learning platform for environments with limited computational resources.
Retrieval-Augmented Generation (RAG) systems represent a significant advancement in AI, combining the power of document retrieval with sophisticated response generation to deliver grounded and contextually relevant answers. This project introduces a lightweight RAG system meticulously designed to illuminate these fundamental concepts without the usual complexities and intensive resource demands often associated with production-grade systems.
The primary focus of this implementation is educational transparency, taking precedence over raw performance optimization. Every operation within the pipeline is accompanied by detailed logging, processing times are meticulously tracked and displayed, and the modular architecture empowers students to easily examine, understand, and modify individual components. This hands-on approach is crucial for grasping the intricate mechanics of RAG systems, moving beyond merely using abstract, black-box APIs.
This system effectively addresses common educational hurdles in RAG: namely, the prohibitive costs of external API requirements, the need for complex infrastructure, and existing implementations that obscure fundamental operations behind layers of abstraction. By exclusively utilizing accessible technologies such as TF-IDF for vectorization and rule-based methods for generation, students gain a clear and comprehensive understanding of every step involved in the RAG process.
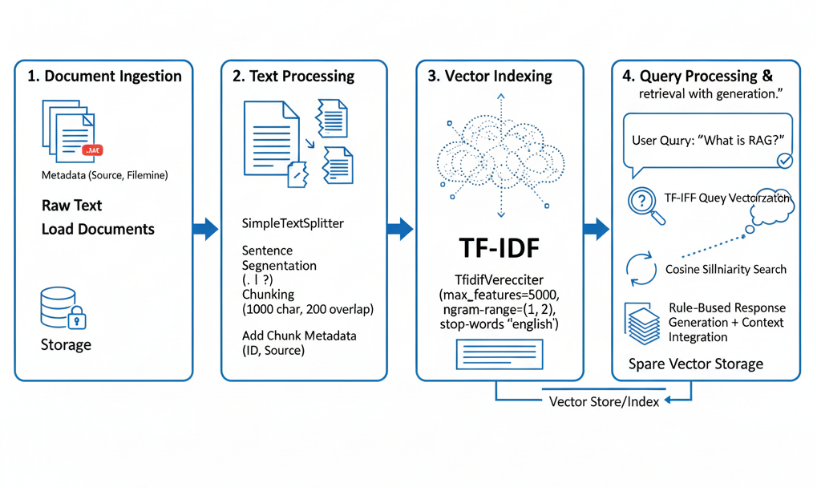
The RAG assistant is built on a robust four-stage pipeline that transparently demonstrates the entire RAG process, from raw text to intelligent response.
The process begins with the load_documents_from_directory method, which efficiently scans and processes .txt files located in a specified directory. For each file, the method creates comprehensive Document objects, embedding not only the raw text content but also crucial metadata such as the source file paths and original filenames. This foundational step ensures that all textual information is properly organized and accessible for subsequent stages of the RAG pipeline.
Following ingestion, the SimpleTextSplitter class takes over, meticulously dividing the loaded documents into manageable segments or "chunks." This specialized implementation prioritizes semantic coherence by splitting text primarily along sentence boundaries, utilizing common punctuation marks (.!?). It strives to maintain a target chunk size of approximately 1000 characters, incorporating a 200-character overlap between consecutive chunks. This overlap is vital for preserving context across segments. Each generated chunk is enriched with metadata, including a unique chunk ID and detailed source information, ensuring traceability and integrity throughout the system.
The core of the retrieval mechanism lies in the Vector Indexing stage, where the system employs scikit-learn's TfidfVectorizer. This vectorizer is configured with specific parameters to optimize representation: a maximum of 5000 features is set to manage vocabulary size effectively, an N-gram range of (1,2) is used to capture both single words (unigrams) and common phrases (bigrams), and standard English stop words are removed to focus on more meaningful terms. The TfidfVectorizer automatically builds its vocabulary from the entire document collection. Once configured, each processed document chunk is transformed into a sparse TF-IDF vector, which is then stored in an index optimized for rapid similarity search.
Upon receiving a user query, the system initiates the Query Processing stage. The first step involves converting the incoming query into a TF-IDF vector, utilizing the exact same vocabulary that was built during the document indexing phase. This ensures that the query and document vectors exist within the same dimensional space, allowing for accurate comparison. The system then calculates the cosine similarity between the query vector and all existing document vectors. Based on these similarity scores, it retrieves the top-k most similar documents, but only if their similarity score exceeds a predefined threshold of 0.1, ensuring only highly relevant information is considered. Finally, responses are generated using a sophisticated rule-based knowledge system, which is dynamically enhanced and enriched with content extracted from these retrieved documents.
def split_text(self, text: str) -> List[str]: # Split into sentences using regex patterns sentences = re.split(r'[.!?]+', text) sentences = [s.strip() for s in sentences if s.strip()] chunks = [] current_chunk = "" for sentence in sentences: if len(current_chunk) + len(sentence) < self.chunk_size: current_chunk += sentence + ". " else: if current_chunk: chunks.append(current_chunk.strip()) current_chunk = sentence + ". "
This specific approach to split_text is crucial for maintaining semantic boundaries within the documents while simultaneously adhering to configurable chunk sizes. By leveraging regular expressions, sentences are accurately identified and then intelligently grouped. The logic ensures that a current_chunk is extended with new sentences until it approaches the self.chunk_size. Once that threshold is met or exceeded, the current chunk is finalized, and a new one begins with the subsequent sentence. This methodical process prevents the arbitrary cutting of sentences and ensures that each chunk remains a coherent and contextually rich piece of information, optimizing it for the TF-IDF vectorization and subsequent retrieval.
def retrieve_relevant_documents(self, query: str, top_k: int = 3): # Vectorize query using same vocabulary as documents query_vector = self.vectorizer.transform([query]) # Calculate cosine similarities similarities = cosine_similarity(query_vector, self.document_vectors)[0] # Get top results above similarity threshold top_indices = np.argsort(similarities)[-top_k:][::-1] results = [] for idx in top_indices: if similarities[idx] > 0.1: # Minimum relevance threshold results.append((self.documents[idx], float(similarities[idx])))
The retrieve_relevant_documents method is central to the system's ability to find relevant information efficiently. When a query is received, the system first converts it into a TF-IDF vector, crucially using the identical vocabulary that was built during the document indexing phase. This ensures that both the query and document vectors exist within the same dimensional space, enabling accurate and meaningful comparisons. A pivotal step then calculates the cosine similarity between the vectorized query and all pre-indexed document vectors. Cosine similarity, which measures the cosine of the angle between two vectors, effectively determines their similarity regardless of their magnitude; a smaller angle indicates higher similarity. The system then meticulously retrieves the top-k most similar documents, but only if their similarity score surpasses a predefined threshold of 0.1. This ensures that only genuinely relevant and meaningfully related content is considered and included in the final set of results, contributing to the quality of the generated response. The implementation clearly demonstrates fundamental vector space retrieval concepts through these transparent operations.
The system employs a hybrid strategy for response generation, expertly combining structured rule-based knowledge with dynamically retrieved content to provide comprehensive and contextually rich answers.
The system incorporates several safety measures and content filtering mechanisms, making it robust and appropriate for educational environments. This comprehensive approach ensures responsible operation and fosters a secure learning experience.
The RAG system was rigorously tested using a set of automatically generated sample documents. These documents were crafted to cover a diverse range of topics relevant to the RAG domain, ensuring comprehensive evaluation of the system's capabilities.
The testing involved a concise yet representative document collection, ensuring efficient processing while demonstrating functionality.
The system transparently tracks and displays several key performance metrics, providing insights into its operational efficiency at various stages.
To illustrate its capabilities, the system was tested with various query types, demonstrating its ability to retrieve and synthesize information effectively.
The RAG assistant is equipped with a range of features designed to facilitate an effective learning experience and demonstrate core RAG functionalities.
help to display available commands and usage guidance, history to show previous questions and answers from the current session, examples to provide suggested queries for testing, and quit to gracefully exit the system.The system is built on a lean and efficient technical foundation, making it highly accessible.
numpy and scikit-learn. faiss-cpu is an optional dependency for accelerated similarity search.The system offers several configurable parameters, allowing users to experiment with different settings and observe their impact on performance and behavior.
SimpleTextSplitter can be configured with chunk_size (target chunk size in characters, default 1000) and chunk_overlap (overlap between chunks, default 200).TfidfVectorizer allows customization of max_features (maximum vocabulary size, default 5000), stop_words (e.g., 'english' for common English words), and ngram_range (e.g., (1, 2) to include unigrams and bigrams).similarity_threshold (minimum similarity for result inclusion, default 0.1) and top_k_documents (maximum number of documents retrieved per query, default 3).While designed for educational efficacy and transparency, the current system has specific limitations that also present exciting opportunities for future development.
.txt format.The RAG assistant is designed for minimal resource consumption, ensuring broad accessibility.
To get the RAG assistant up and running, follow these straightforward steps:
git clone https://github.com/E-Z1937/rag-assistant-aaidc.git
cd rag-assistant-aaidc
If you face issues, you can try the standard:pip install --timeout 300 --retries 3 -r requirements.txt
pip install -r requirements.txt
The requirements.txt file specifies the necessary Python packages:
langchain-core>=0.1.0
faiss-cpu>=1.7.4
python-dotenv>=1.0.0
numpy>=1.24.0
scikit-learn>=1.0.0
gradio>=4.0.0
pandas>=2.0.0
requests>=2.25.0
Once installed, interacting with the RAG assistant is simple and intuitive:
python rag_assistant.py
help for a list of available commands and usage guidance.history to view your previous questions and the system's answers from the current session.examples to see suggested queries that demonstrate the system's capabilities.quit to gracefully exit the system.This project stands as a testament to the fact that effective Retrieval-Augmented Generation (RAG) systems can be implemented using widely accessible technologies, without compromising on educational value. The thoughtful combination of TF-IDF vectorization, precise cosine similarity search, and an intelligent rule-based response generation strategy provides a transparent and robust foundation for understanding the core concepts of RAG.
The implementation successfully processes diverse document collections, performs semantic searches efficiently, and generates contextually appropriate responses, all while maintaining complete operational transparency. A key achievement is the development of a fully functional RAG pipeline that requires no external dependencies beyond standard scientific Python libraries, making it incredibly accessible. Furthermore, its educational transparency, achieved through comprehensive logging and explainable operations, coupled with practical performance suitable for interactive learning scenarios, makes it an invaluable tool for students and developers alike.
The modular architecture of this system is a significant advantage, as it enables progressive enhancement. This design empowers students and developers to easily experiment with alternative chunking strategies, explore different similarity metrics, or integrate more advanced response generation approaches. Ultimately, this project provides a solid and flexible foundation for understanding both the current landscape of RAG implementations and the exciting future developments in retrieval-augmented systems.
License: MIT - Open source for educational use and modification.