Abstract
With the explosion of user-generated content on social media platforms, understanding public sentiment at scale has become increasingly valuable for businesses, researchers, and policymakers. Tweets, in particular, are short and often unstructured, making them challenging to analyze using conventional natural language processing methods. This project addresses the challenge of accurately classifying tweet sentiments using modern deep learning approaches. The models aim to classify tweets into two sentiment categories: positive and negative. We compared the performance of traditional architectures such as LSTM with the state-of-the-art transformer-based models like BERT and BART, to determine the most effective approach for text-based sentiment analysis.
Methodology
The methodology was pretty straight forward - pre-process the data, train the models on the data, and then evaluate each of them.
Dataset
As mentioned before, we used the Sentiment140 dataset, which consisted of 1.6 million tweets labeled for sentiments: positive and negative. For the LSTM, we used the entire 1.6 million tweets data, for BERT we used 800,000 tweets data, and for BART we used 250,000 tweets data because of the computation and time constraints. But, transformer-based models are better at generalizing to NLP tasks due to pre-training, which gives them a general understanding of a language. So, you can just use a small portion of the dataset to fine-tune them. The batch sizes for the LSTM, BERT, and BART models were 256, 64, and 32. The sizes were selected based on a number of factors including computing constraints, performance testing, etc.
Pre-Processing
For pre-processing the data for the models, a simple data cleaning step took place first, which removed usernames, URLs, HTML entities, and unnecessary whitespace from the tweets using RegEx. Data was split into a ratio of 80/10/10. As the data was huge, we felt that a 70/15/15 or a 60/20/20 split would result in larger-than-necessary validation and test splits. So, we tried to allocate the maximum data possible for the training split. During the cleaning step, the sentiment labels were remapped to a binary-class format, the negative sentiment examples were mapped to 0 label, and the positive sentiment examples were mapped to 1 label.
Tokenization
Tokenization was performed differently for the transformer-based models and LSTM. For the LSTM model, Tensorflow’s Tokenizer and pad_sequences functions were used. For BERT and BART, Hugging Face's AutoTokenizer was used, with padding and truncation to a maximum sequence length, which we set to 128.
Model Architectures
LSTM (Long-Short Term Memory)
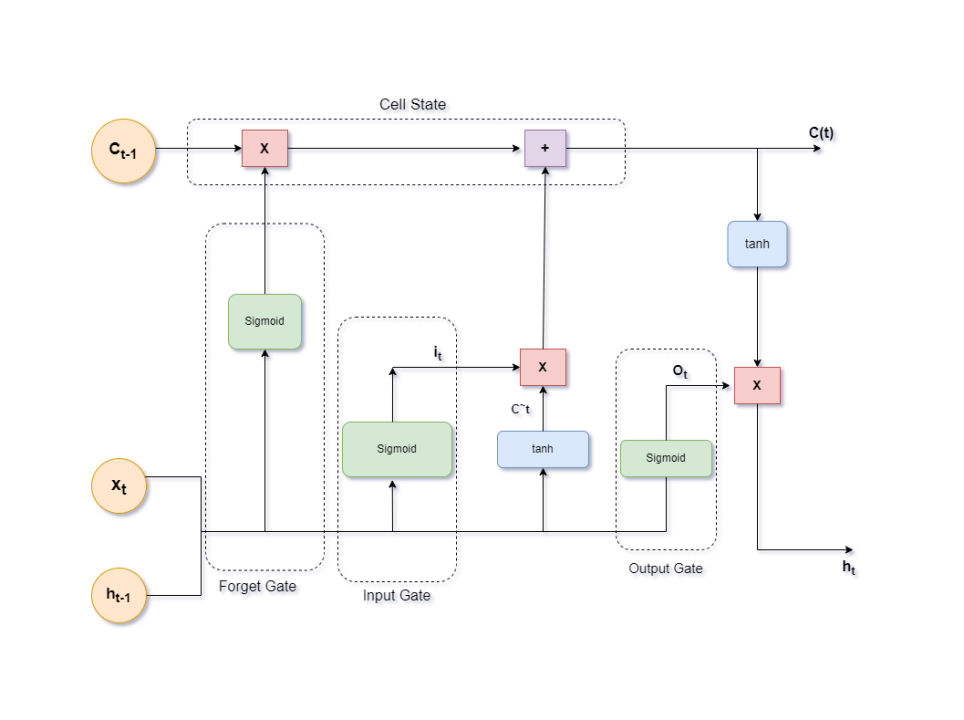
LSTMs are a type of recurrent neural network (RNN) that process sequences token-by-token, maintaining a memory cell that updates over time. Unlike traditional RNNs, LSTMs use gates (input, forget, and output) to control the flow of information, allowing them to capture long-term dependencies in text.
For sentiment analysis, the final hidden state of the LSTM (or an average/max pooling of all hidden states) is passed to a classification layer. While LSTMs were widely used before transformers, they often struggle with longer texts and lack parallelization, making them slower and less performant compared to BERT and BART.
We implemented a custom Bi-LSTM model, which we used as a baseline model to compare the performances of the Transformer-based models with. The model definition, training, and evaluation, all were done using TensorFlow due to ease-of-use:
lstm_model = Sequential([ InputLayer(shape=(500,)), Embedding(TOP_WORDS, 100), Bidirectional(LSTM(512, return_sequences=True, activation="tanh")), Dropout(0.5), Bidirectional(LSTM(256, activation="tanh")), Dropout(0.5), Dense(64, activation="relu"), Dense(1, activation='sigmoid'), ]) lstm_model.compile( loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'] ) lstm_history = lstm_model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=4, batch_size=256, verbose=1, )
The model contained an Embedding layer, 2 Bi-LSTM layers with 512 and 256 units each, Dropout layers to counteract overfitting, a dense layer with 6 neurons, and finally a sigmoid unit which classifies the data as positive or negative. The Bidirectional wrapper here allows an LSTM (or an RNN) to process sequences in both forward and backward directions, which allows it to capture context from both directions, leading to better performance. The downside is, it basically uses two LSTM models, one which processes input from left-to-right, and another that processes input from right-to-left. And since these models are not parallelizable, as they use information from previous states to process the current token, they dont scale very well compared to Transformers.
BERT (Bidirectional Encoder Representations from Transformers)
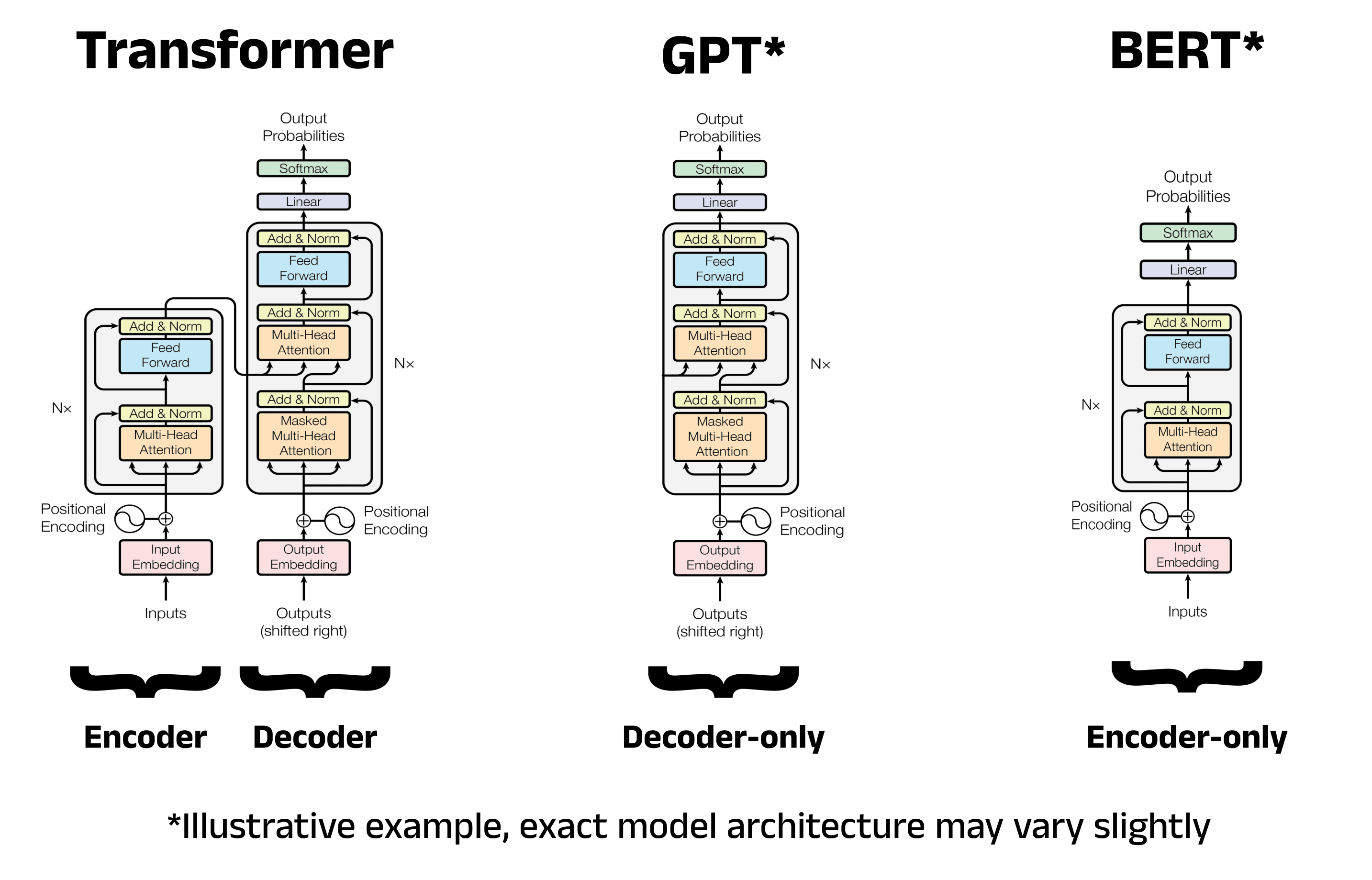
BERT is an encoder-only transformer model developed by Google. Unlike the original Transformer architecture which contains both Encoder and Decoder parts, BERT model only uses Encoder part, which consists of It processes input text in a fully bidirectional manner, meaning it considers both the left and right context of each token. This is achieved using self-attention layers that allow each token to attend to every other token in the input sequence. For sentiment analysis, the [CLS] token's output from the final encoder layer is used as a sentence representation and fed into a classification head (usually a simple feedforward layer) to predict the sentiment label.
As mentioned earlier, we used the distilled version of BERT, namely "DistilBERT", which we used through HuggingFace's Transformer library. The model training and evaluation was done using a custom loop which we created using PyTorch:
bert_model = AutoModelForSequenceClassification.from_pretrained(bert_checkpoint, num_labels=2) bert_model.to(device)
epochs = 3 learning_rate = 2e-5 total_steps = len(train_dataset) * epochs optimizer = AdamW(bert_model.parameters(), lr=learning_rate) scheduler = get_linear_schedule_with_warmup( optimizer, num_warmup_steps=0, num_training_steps=total_steps )
def train(model): model.train() predictions = [] true_labels = [] total_loss = 0 for batch in tqdm(train_dataset, desc="Training"): batch = {k: v.to(device) for k, v in batch.items()} optimizer.zero_grad() outputs = model(**batch) loss = outputs.loss total_loss += loss.item() logits = outputs.logits preds = torch.argmax(logits, dim=-1) predictions.extend(preds.cpu().numpy()) true_labels.extend(batch["labels"].cpu().numpy()) loss.backward() optimizer.step() scheduler.step() avg_loss = total_loss / len(train_dataset) accuracy = accuracy_score(true_labels, predictions) return avg_loss, accuracy def evaluate(model): model.eval() predictions = [] true_labels = [] total_loss = 0 with torch.no_grad(): for batch in tqdm(val_dataset, desc="Evaluating"): batch = {k: v.to(device) for k, v in batch.items()} outputs = model(**batch) loss = outputs.loss total_loss += loss.item() logits = outputs.logits preds = torch.argmax(logits, dim=-1) predictions.extend(preds.cpu().numpy()) true_labels.extend(batch["labels"].cpu().numpy()) avg_loss = total_loss / len(val_dataset) accuracy = accuracy_score(true_labels, predictions) return avg_loss, accuracy def test_evaluate(model): model.eval() predictions = [] true_labels = [] total_loss = 0 with torch.no_grad(): for batch in tqdm(test_dataset, desc="Testing"): batch = {k: v.to(device) for k, v in batch.items()} outputs = model(**batch) loss = outputs.loss total_loss += loss.item() logits = outputs.logits preds = torch.argmax(logits, dim=-1) predictions.extend(preds.cpu().numpy()) true_labels.extend(batch["labels"].cpu().numpy()) avg_loss = total_loss / len(test_dataset) y_true = np.array(true_labels) y_pred = np.array(predictions) accuracy = accuracy_score(y_true, y_pred) precision = precision_score(y_true, y_pred, average='weighted', zero_division=0) recall = recall_score(y_true, y_pred, average='weighted', zero_division=0) f1 = f1_score(y_true, y_pred, average='weighted', zero_division=0) try: roc_auc = roc_auc_score(y_true, y_pred) except ValueError: roc_auc = "Not applicable (non-binary classification)" print("\n--- Test Evaluation Metrics ---") print(f"Loss: {avg_loss:.4f}") print(f"Accuracy: {accuracy:.4f}") print(f"Precision (weighted): {precision:.4f}") print(f"Recall (weighted): {recall:.4f}") print(f"F1 Score (weighted): {f1:.4f}") print(f"ROC-AUC: {roc_auc}") print("\nClassification Report:") print(classification_report(y_true, y_pred))
train_loss_history = [] val_loss_history = [] train_acc_history = [] val_acc_history = [] for epoch in range(epochs): print(f"\nEpoch {epoch + 1}/{epochs}") train_loss, train_acc = train(bert_model) print(f"Train Loss: {train_loss:.4f}") print(f"Train Accuracy: {train_acc: .4f}") train_loss_history.append(train_loss) train_acc_history.append(train_acc) val_loss, val_acc = evaluate(bert_model) print(f"Eval Loss: {val_loss:.4f}") print(f"Eval Accuracy: {val_acc:.4f}") val_loss_history.append(val_loss) val_acc_history.append(val_acc)
BART (Bidirectional and Auto-Regressive Transformers)
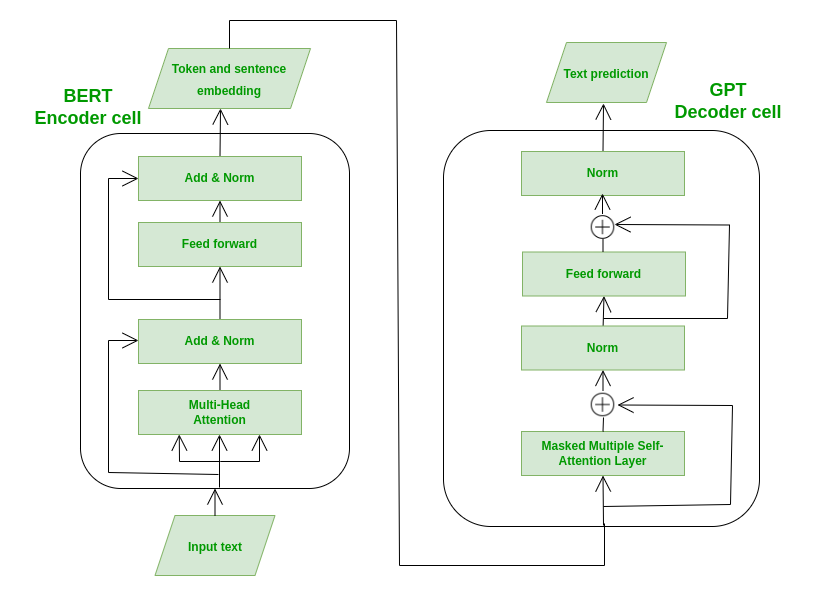
BART combines the strengths of both BERT and GPT by using a sequence-to-sequence architecture with an encoder-decoder structure. The encoder is similar to BERT and processes input bidirectionally, while the decoder is autoregressive like GPT, generating output token-by-token. While originally designed for text generation, BART is also effective for classification by feeding the encoder's output into the decoder and using the [EOS] token's representation for classification.
Again, we used the distilled version of BART through HuggingFace's Transformer library. The model training and evaluation was done using the custom loop which we used for BERT:
bart = BartForSequenceClassification.from_pretrained(bart_checkpoint, num_labels=2) bart.to(device)
epochs = 3 learning_rate = 2e-5 total_steps = len(train_dataloader) * epochs optimizer = AdamW(bart.parameters(), lr=learning_rate) scheduler = get_linear_schedule_with_warmup( optimizer, num_warmup_steps=0, num_training_steps=total_steps )
train_loss_history = [] val_loss_history = [] train_acc_history = [] val_acc_history = [] for epoch in range(epochs): print(f"\nEpoch {epoch + 1}/{epochs}") train_loss, train_acc = train(bart) print(f"Train Loss: {train_loss:.4f}") print(f"Train Accuracy: {train_acc: .4f}") train_loss_history.append(train_loss) train_acc_history.append(train_acc) val_loss, val_acc = evaluate(bart) print(f"Eval Loss: {val_loss:.4f}") print(f"Eval Accuracy: {val_acc:.4f}") val_loss_history.append(val_loss) val_acc_history.append(val_acc)
Training
We went with the distilled versions of BERT and BART, namely distilbert/distilbert-base-uncased and sshleifer/distilbart-cnn-12-6, which are publicly available on HuggingFace huge library of open-source models. For LSTM, we used TensorFlow to implement the model using the Sequential API and also added the Bidirectional wrapper so that the model can develop a deeper understanding of the text by getting information from the text by processing it left-to-right as well as right-to-left. For BERT and BART, we implemented a custom loop for training and evaluation using PyTorch. The LSTM model was trained for 4 epochs, the transformer-based models were trained for 3 epochs each.
Evaluation
All models were evaluated on the same metrics, which included Accuracy, Precision, Recall, F1-Score, and ROC-AUC Score and we also generated Classification Report using Scikit-Learn which included a class-wise breakdown of the metrics. Additionally, we visualized the model's Training and Evaluation losses to observe any overfitting.
Results
LSTM
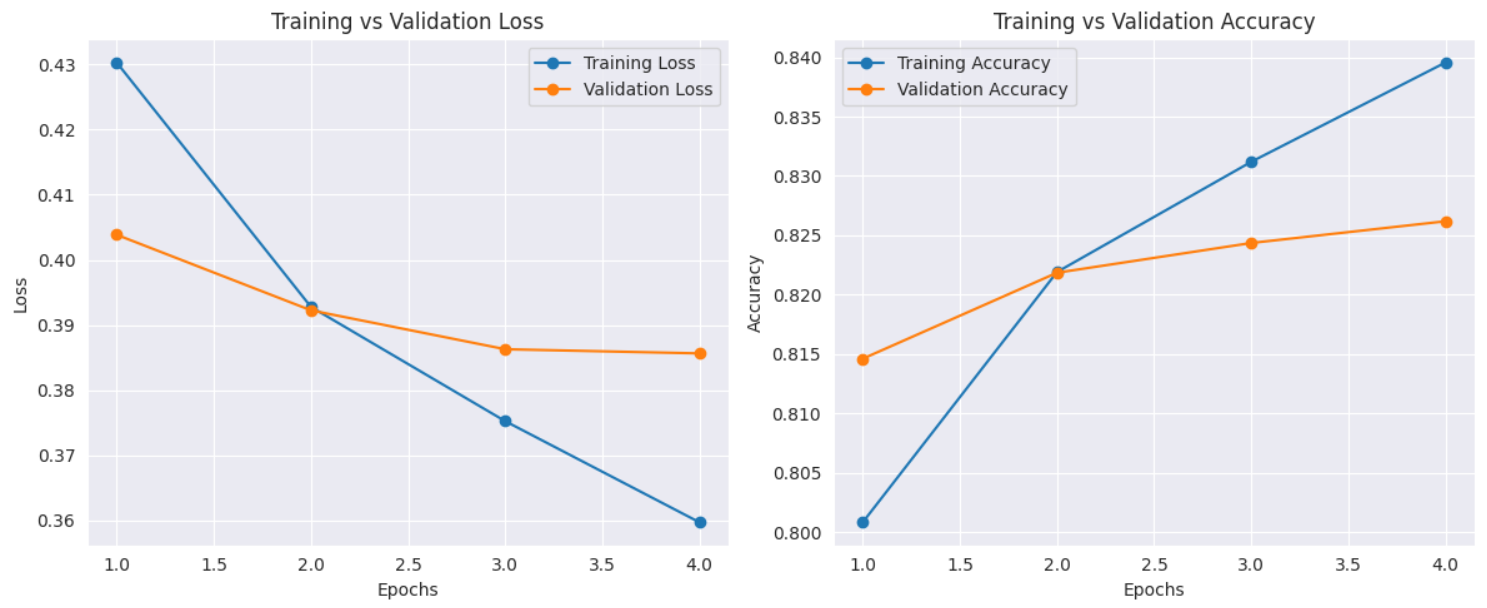
The Bi-LSTM model performed robustly as a baseline for the sentiment analysis task, achieving a weighted precision, recall, and F1-score of 0.8271, along with a ROC-AUC of 0.827. These metrics indicate that the model maintains a balanced and reliable performance across both classes. The training and validation curves show steady improvement without signs of overfitting, reflecting good generalization. The classification report further confirms consistent behavior across both positive and negative sentiments, with near-equal support:
--- Test Evaluation Metrics --- Loss: 0.3552 Accuracy: 0.8502 Precision (weighted): 0.8504 Recall (weighted): 0.8502 F1 Score (weighted): 0.8501 ROC-AUC: 0.8501568201690328 Classification Report: precision recall f1-score support 0 0.84 0.86 0.85 75018 1 0.86 0.84 0.85 74982 accuracy 0.85 150000 macro avg 0.85 0.85 0.85 150000 weighted avg 0.85 0.85 0.85 150000
BERT
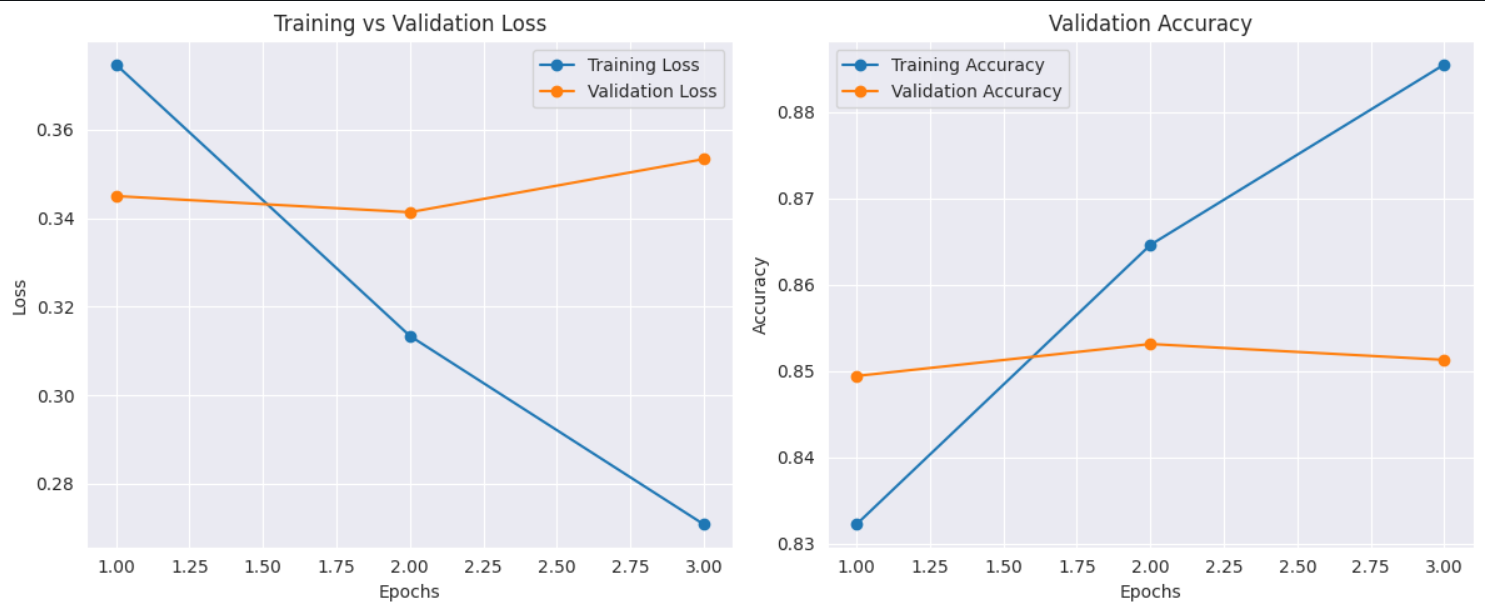
The BERT model demonstrated strong performance on the sentiment analysis task, achieving an overall accuracy of 85.02%, with weighted precision, recall, and F1-score all around 0.85, and a ROC-AUC of 0.85, indicating excellent class separation ability. The classification report confirms consistent performance across both sentiment classes, with balanced precision and recall. However, the training vs. validation plots suggest signs of overfitting, as training loss decreases steadily while validation loss begins to rise slightly after epoch 2, and validation accuracy plateaus or slightly drops. Despite this, the model significantly outperforms the Bi-LSTM baseline and showcases BERT’s strength in leveraging contextual information effectively for classification. Regularization or early stopping might further improve generalization.
--- Test Evaluation Metrics --- Loss: 0.3552 Accuracy: 0.8502 Precision (weighted): 0.8504 Recall (weighted): 0.8502 F1 Score (weighted): 0.8501 ROC-AUC: 0.8501568201690328 Classification Report: precision recall f1-score support 0 0.84 0.86 0.85 75018 1 0.86 0.84 0.85 74982 accuracy 0.85 150000 macro avg 0.85 0.85 0.85 150000 weighted avg 0.85 0.85 0.85 150000
BART
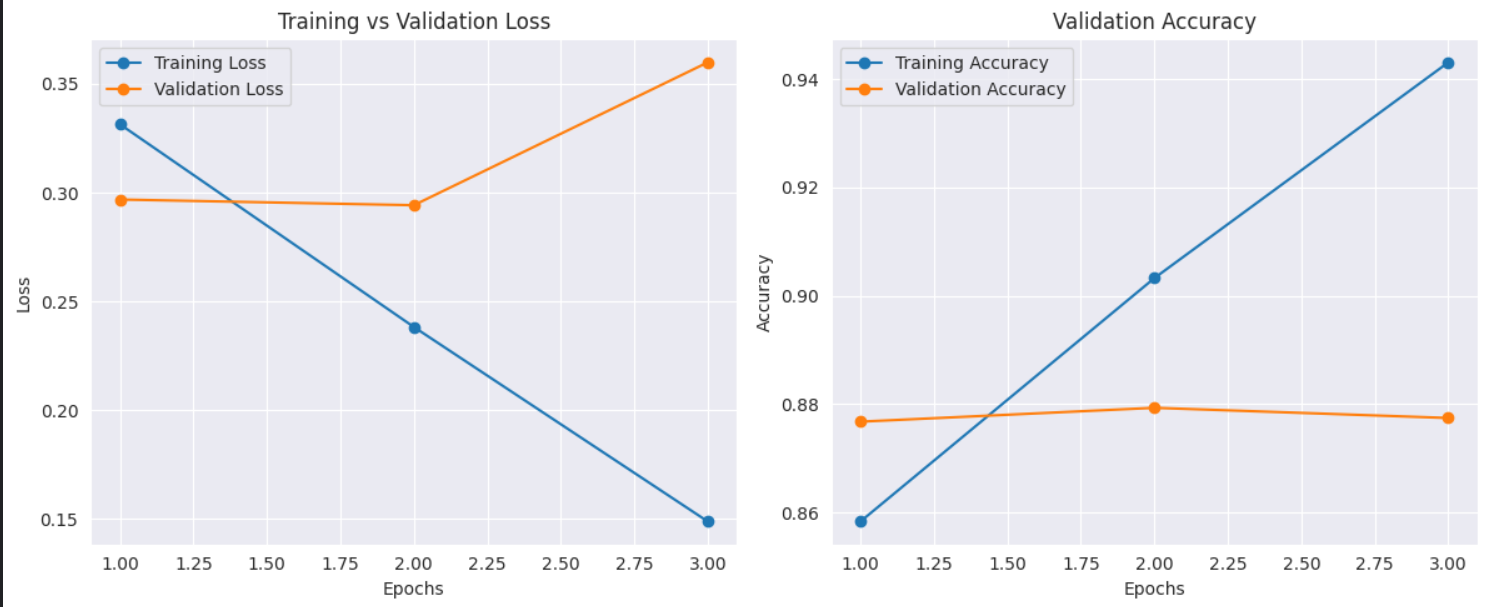
BART model demonstrates strong performance, as evidenced by the training and validation metrics. The training and validation loss curves show a steady decrease, indicating effective learning without significant overfitting, with the validation loss stabilizing around 0.20. Similarly, the accuracy curves reveal that both training and validation accuracy improve over epochs, reaching around 0.94 and 0.90, respectively. The test evaluation metrics further confirm the model's robustness, with an accuracy of 0.8775 and balanced precision, recall, and F1 scores (all around 0.88) for both classes. The ROC-AUC score of 0.8775 also indicates good discriminative power.
--- Test Evaluation Metrics --- Loss: 0.3669 Accuracy: 0.8775 Precision (weighted): 0.8778 Recall (weighted): 0.8775 F1 Score (weighted): 0.8775 ROC-AUC: 0.8774857168881531 Classification Report: precision recall f1-score support 0 0.87 0.89 0.88 12531 1 0.89 0.86 0.88 12469 accuracy 0.88 25000 macro avg 0.88 0.88 0.88 25000 weighted avg 0.88 0.88 0.88 25000
Conclusion
This project explored sentiment analysis using deep learning models, starting with a Bi-LSTM as a baseline and progressing to transformer-based architectures, BERT and BART. The Bi-LSTM model delivered solid baseline performance, while BERT significantly improved accuracy and contextual understanding. Ultimately, BART outperformed both, demonstrating the best overall generalization and robustness across all evaluation metrics. By leveraging the strengths of pre-trained transformer architectures, particularly BART’s encoder-decoder design, the project highlights the effectiveness of transfer learning in text classification tasks. These results reinforce the value of transformer models for nuanced NLP applications like sentiment analysis.