This project presents a production‑ready multi‑agent AI system designed to analyse seismic datasets published by the Italian National Institute of Geophysics and Volcanology (INGV).
Built with LangGraph, Cohere LLM, Jina / MiniLM embeddings, and Qdrant, the system transforms raw seismic data into structured knowledge, automatically generated reports, and reliable question‑answering outputs.
The focus of this work is not only multi‑agent intelligence, but engineering qualities required for real‑world deployment: robustness, deterministic behaviour, traceability, automated testing, and usability for non‑technical users.
Seismic datasets are often large, heterogeneous, and noisy. Analysts and researchers must manually inspect data, extract meaningful patterns, validate metadata, and generate reports—tasks that are time‑consuming and error‑prone. This project addresses the challenge by introducing an agent‑oriented AI pipeline that: understands seismic datasets structurally, enriches them semantically, validates outputs scientifically and produces coherent, ready‑to‑use documentation.
The system follows a LangGraph‑based orchestration model, where each agent performs a clearly defined task and cooperates through a shared, deterministic state.
| Agent | Responsibility |
|---|---|
| Dataset Analyzer | Inspects and structures the input dataset to build a foundational understanding. |
| Embedding Agent | Generates semantic embeddings used for similarity search and knowledge extraction. |
| Content Improver | Enhances the clarity, structure, and readability of the text. |
| Metadata Recommender | Proposes metadata, labels, and structural annotations for enriched context. |
| QA Agent | Answers analytical or data‑driven queries using processed information. |
| QA Reviewer | Validates, refines, and ensures quality of answers generated by other agents. |
| Article Generator | Produces final articles or reports synthesising all processed information. |
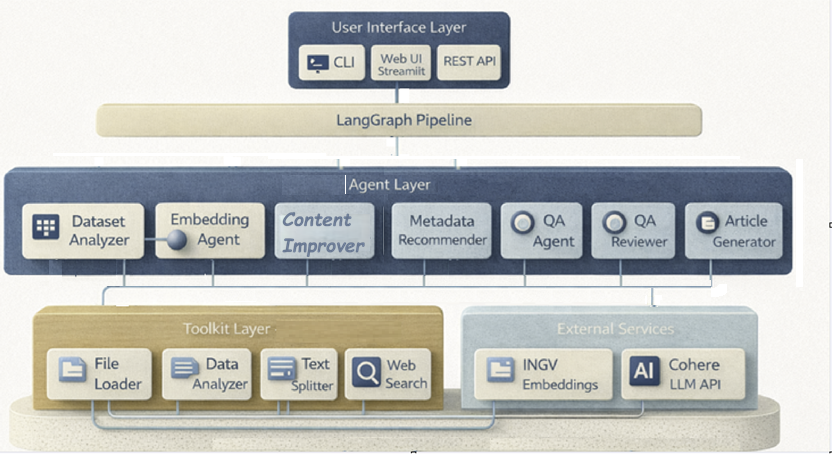
The architecture shows a multi-level system in which user interaction occurs through different interfaces, such as the CLI, Streamlit, or a REST API, which queries LangGraph, which coordinates the flow of operations involving a set of collaborating agents. These agents are responsible for analysing the dataset and generating embeddings; others improve the content, suggest metadata, or handle question answering and reviewing answers. Each agent has a specific role and contributes to transforming, enriching, or validating the information. To support this, the Tool layer provides essential tools such as file upload, data analysis, text splitting, and web search, which feed agents with structured inputs. The architecture integrates with external services, including the embedding files INGV makes available on its website and the Cohere LLM APIs. These services add advanced semantic analysis. The entire system then operates as a coordinated chain, with each layer collaborating to produce high-quality, intelligent outputs.
The Dataset Analyser Agent is the entry point of the entire seismological pipeline. It is responsible for examining an INGV dataset, managing both directories and ZIP archives, and automatically identifying the files in TXT format of the official seismic catalogues. Once the files have been extracted, the agent reads the contents line by line, recognises the standard INGV columns, and filters out invalid or incomplete rows. Transform each event into a structured record with geophysical fields, including magnitude, depth, coordinates, event type, and authorial metadata. During processing, it verifies data consistency and identifies anomalies. When finished, it produces a complete statistical summary, including the minimum, maximum, and average magnitude; min/max/avg depth; and the total number of valid events. It also returns the entire list of extracted events, the number of files processed, and the path of the normalised dataset. Its output becomes the solid foundation on which the other agents in the multi-agent pipeline are grafted.
The Embedding Agent is responsible for transforming each INGV seismic event into a semantic vector representation for intelligent search. Upon launch, the agent verifies that the Qdrant collection dedicated to events exists; if it does not, it automatically creates it with the correct carrier size. Each event is converted into short, informative text that summarises magnitude, location, depth, event type, and essential metadata. These texts are then processed locally through the MiniLM model of SentenceTransformers, a fast and effective solution even in an offline environment. The generated embeddings are grouped into small batches to avoid exceeding payload limits and optimise memory usage. Next, the agent constructs vector points complete with descriptive payloads and inserts them into Qdrant in controlled micro-batches. Once the collection is populated, the agent allows you to perform semantic searches of similar events, either based on another event or on a free-text query. This enables exploratory analysis, clustering, and intelligent queries on earthquake characteristics.
The Metadata Recommender Agent analyses the already processed seismic dataset and generates intelligent metadata that enriches the geophysical content provided by INGV. Starting from the list of events and the statistical values extracted from the Dataset Analyser, the agent builds a series of synthetic titles that best represent the extent and intensity of the seismic sequence. It then produces a one-sentence summary, useful for compact descriptions in reports or information systems. In parallel, it generates thematic tags based on magnitude, average depth, and characteristic locations such as Campi Flegrei, Etna, or the Apennines, allowing rapid classification of the dataset. The agent also elaborates reasoning, i.e., a textual explanation of the choices made and the seismological classification of the data. The goal is to provide a set of metadata that is clear, consistent, and immediately usable by Content Improver, Reviewer, and Article Generator in the multi-agent pipeline. In this way, the agent contributes to the scientific and narrative contextualization of seismic information.
The Content Improver Agent intervenes after the seismic dataset has been analysed and enriched with metadata, aiming to transform raw numbers and values into clear, readable, and technically accurate text. Starting from the statistical summary (min/max/average magnitude, min/max/average depth, number of events) and the metadata suggested by the Metadata Recommender, the agent builds a concise description that presents the entire dataset in a fluid, understandable way. It integrates the main information into a coherent paragraph, explaining the variability in magnitude, the distribution of hypocentral depths, and the geographical spread of the INGV-recorded events. The result is improved text that is ready to be used in reports, UI panels, or as the basis for the introductory section of the final seismological article. The agent also returns a summary of metadata usage and the number of events processed, enabling subsequent steps in the pipeline to track context.
The Reviewer Agent serves as the scientific validator for the entire INGV seismic dataset, assessing its quality, reliability, and completeness. After receiving the events processed by the Dataset Analyzer and any enhanced text from the Content Improver, it performs a series of structured checks to identify critical errors, missing fields, and inconsistencies in geophysical values. In particular, it analyses the presence of fundamental fields such as time of origin, coordinates, magnitude, and depth, verifying that they are always available and correctly formatted. It also identifies numerical anomalies such as out-of-range depth or unrealistic magnitude, and produces targeted alerts to be submitted to the user or to the next steps in the pipeline. In addition to checks, it calculates a dataset health score by penalising serious problems, warnings, and missing fields. The Reviewer also produces recommendations and potential improvement actions, ranks them by priority, and facilitates the dataset review. This assessment is the foundation for the QA Agent and for generating the final report.
The QA Agent is the agent dedicated to answering questions about INGV seismic data, integrating semantic search and LLM generation. When the agent receives a question from the user, it first performs a vector search in Qdrant using the Embedding Agent to identify the most relevant events based on the query's semantic content. Starting from the results, it builds a synthetic scientific context, reporting key information such as magnitude, depth, coordinates, location, and type of event for each event. This context is then transformed into a specialised geophysical prompt, designed to guide the LLM model towards precise answers consistent with real data. The agent then uses the Cohere model to generate a concise, scientific, evidence-based response from the dataset. The QA Agent thus allows you to query the entire seismic archive in natural language, obtaining explanations, summaries, and targeted information on the most significant events. It is a fundamental component to make the dataset searchable intelligently and immediately.
The Article Generator Agent is the component of the pipeline responsible for producing complete seismological articles, scientific reports, and other informative content based on INGV data. Use an advanced LLM model to transform the results generated by other agents — dataset analysis, metadata, reviews, and summaries — into structured, clear, publish-ready text. The agent receives context consisting of seismic statistics, magnitude ranges, spatial distributions, and any user inputs, such as requests for weekly reports or analysis of specific areas. Based on these elements, it builds a detailed prompt that guides the LLM model towards a formal and scientific style, dividing the content into coherent sections and subsections.
A lightweight Streamlit‑based interface abstracts the system’s internal complexity and presents agent capabilities through a guided, user‑friendly workflow. The UI allows users to provide inputs such as a dataset, and then follow the multi‑agent pipeline step by step. Each stage displays structured outputs, including intermediate embeddings, recommendations, improvements, and final generated content. The interface also provides validation feedback, error notifications, and clear status indicators, ensuring transparency throughout the pipeline. At the end of the workflow, the interface assembles all validated outputs into a coherent scientific‑style article generated by the Article Generator. This final report is presented in a clean, readable layout, ready for export or further review. Through this design, the UI opens the system to researchers, analysts, and non‑technical users alike, enabling advanced multi‑agent capabilities through a simple, guided experience.
Resilience improvements ensure the earthquake‑processing pipeline remains stable even when dealing with noisy data, missing parameters, or inconsistent INGV feeds. The system now applies backoff‑based retry logic when remote seismic data endpoints fail or return incomplete TXT payloads, preventing abrupt interruptions. Structured error propagation makes every failure explicit, enabling agents and the Streamlit UI to respond predictably rather than silently discarding information. Early‑exit detection stops the workflow immediately when essential seismic fields—such as magnitude, depth, or coordinates—are absent, avoiding the generation of misleading outputs. All user‑provided notes and textual inputs are sanitised to prevent malformed strings from contaminating downstream agents. Deterministic state management ensures reproducible behaviour across multiple runs, even under fluctuating network conditions or intermittent INGV availability. Together, these upgrades enable the system to gracefully handle real‑world seismological data and deliver reliable, scientifically valid results under a variety of environmental and data‑quality constraints.
A dedicated automated test suite validates tools, pipeline logic, keyword extraction, and end-to-end execution. Mocked at file INGV calls ensure functionality without external dependency. Tests also verify that human edits flow through the state and influence final outputs, guaranteeing correctness and enabling maintainability for iterative development.
| Layer | Tools |
|---|---|
| Language | Python 3.10+ |
| Orchestration | LangGraph (0.0.x) – multi‑agent workflow engine |
| Text Pipeline | LangChain (0.1.x) – text utilities, tool integration |
| LLM / AI | Cohere API (5.20.0) – generation, analysis |
| Embeddings | MiniLM & Sentence‑Transformers – local embedding fallback |
| Vector DB | Qdrant (local, 1.6.0) – vector search and storage |
| UI | Streamlit – lightweight web interface |
| HTTP / I/O | requests, file loader utilities |
| Environment | python‑dotenv – configuration & secrets |
| Podman | Deployment environment |
| Testing | pytest |
| Clients | cohere SDK, qdrant‑client |
| Output | Scientific reports, structured analysis, agent‑generated content |
├── agents/ # 7 specialized agents (INGV)
│ ├── dataset_analyzer.py # Analysis of seismic datasets (INGV formats)
│ ├── embedding_agent.py # Embedding on geophysical & retrieval data
│ ├── metadata_recommender.py # Metadata suggestion (event, magnitude...)
│ ├── content_improver.py # Improved event descriptions
│ ├── reviewer.py # Scientific validation & scoring
│ ├── qa_agent.py # Q&A on INGV earthquakes
│ └── article_generator.py # Generation of seismological reports/studies
│
├── tools/ # 5 support tools
│ ├── file_loader.py # Dataset upload
│ ├── text_splitter.py # Chunking technical texts (800 tokens / 100 overlap)
│ ├── data_analyzer.py # Structural analysis of seismological datasets
│ ├── web_search.py # Integration with public data (INGV, EMSC, USGS)
│ ├── test_ingv_embeddings.py # Test embedding (INGV vector service)
│ ├── test_qdrant.py # Vector database test
│ └── benchmark_performance.py # Benchmark pipeline/LLM
│
├── orchestrator/ # Flow orchestration
│ ├── langgraph_flow.py # Pipeline LangGraph
│ └── simple_pipeline.py # Simplified alternative pipeline
│
├── tests/ # componets test
│ ├── test_ingv_agents.py # Agents test
│ ├── test_tools_ingv.py # Tools test
│ └── test_validators_ingv.py # Validator Test
│
├── config/
│ └── config.py # Service Configurations (INGV API, Cohere, Qdrant)
│
├── data/
│ └── sample_earthquakes/ # Dataset INGV
│
├── main.py # Entry point CLI
├── app.py # GUI
├── requirements.txt # Requirements
├── .env # Environment variable templates
├── earthquakes.kube.yaml # Podman Services (Qdrant, API, LLM)
├── Dockerfile # Docker app
├── LICENSE # License
└── README.md # Project documentation
🧿 1. Retrieval Stability Assessment
The system was tested with multiple seismic input files to verify consistent extraction under varying data conditions. When endpoints were unreachable or files were not found, the pipeline activated controlled retries and fallback mechanisms. These checks confirmed stable degradation behaviour and safe handling of retrieval failures.
🔄 2. Multi‑Agent Coordination Performance
Repeated executions of the seismic analysis pipeline confirmed that agents consistently maintained shared context, correctly incorporated upstream refinements, and produced logically aligned downstream outputs. These tests validated reliable handoff, stable state transitions, and coherent reasoning across the entire multi‑agent chain.
🛠️ 4. Fault Handling & Robustness
The pipeline was tested against invalid URLs, missing seismic datasets, and temporary API interruptions. It responded with clear logs, controlled retries, and explicit termination messages, demonstrating strong resilience and awareness of failure conditions.
🧭 5. Usability Assessment
Non‑technical users tested the Streamlit interface and were able to run the full earthquake‑analysis workflow without touching the command line. The guided layout and structured panels enabled them to follow each step and ultimately obtain a complete, automatically generated scientific-style report.
✅ 6. Automated Consistency Checks
A suite of automated tests verifies that each agent executes correctly and that the orchestration behaves deterministically across all seismic‑analysis workflows. The validation also confirms the accuracy of extracted features and ensures that human‑in‑the‑loop signals propagate reliably through every stage of the pipeline.
podman machine init --now --user-mode-networking
podman machine start
podman build -t earthquake-agent .
podman play kube earthquakes.kube.yaml
The improved system delivered stable performance, recovered smoothly from failure scenarios, and preserved user‑provided edits throughout the entire seismic‑analysis pipeline. Both CLI and browser‑based workflows produced clear, actionable outputs, with all automated tests confirming full operational readiness. Feedback loops enhanced the clarity of the generated scientific reports, and usability tests showed successful adoption, even among users unfamiliar with multi‑agent systems.
The text and images in this document were created with the support of Microsoft Copilot. The author, Rosaria Daniela Scattarella, transfers to Engineering Ingegneria Informatica S.p.A. all economic rights relating to such contents, including reproduction, modification, distribution, and commercial use. © 2026 Engineering Ingegneria Informatica S.p.A. – All rights reserved.
This project developed from a conceptual earthquake-analysis pipeline into a deployable, production-ready system focused on robustness, traceability, and user-driven control. Its strength lies not in adding more agents, but in engineering the existing architecture to behave like dependable software: measurable, diagnosable, steerable, resilient, and easy to operate. Through orchestration design, UI support, and fault-tolerance strategies, the system now meets real-world expectations for agentic AI and demonstrates readiness for professional use.