
TL;DR
SecureCLI-Tuner is a QLoRA fine-tuned LLM that generates safe Bash commands from natural language while preventing dangerous operations. This project demonstrates end-to-end LLM fine-tuning with a focus on security: filtering dangerous commands from training data, applying runtime validation guardrails, and achieving 100% adversarial attack blocking.
Objective
The Challenge
As LLMs increasingly power DevOps automation and autonomous agents, a critical security gap has emerged. Standard models can:
- Hallucinate dangerous operations like
rm -rf / or recursive deletions.
- Be manipulated by adversarial prompts into executing host-takeover commands.
- Generate syntactically correct but harmful code that bypasses simple keyword filters.
The Solution: SecureCLI-Tuner
I fine-tuned a model to convert natural language instructions into safe Bash/CLI commands using a "Defense in Depth" strategy:
- Clean Training: A rigorous data sanitation pipeline.
- Domain Mastery: Fine-tuning on a curated NL→Bash dataset.
- Runtime Guardrails: A 3-layer validation engine for every model output.
The system employs three specific layers of defense:
- Deterministic Layer: Blocks 17 catastrophic regex patterns (e.g., fork bombs, disk wipes).
- Heuristic Layer: Scores commands against known MITRE ATT&CK patterns.
- Semantic Layer: Uses CodeBERT embeddings to detect malicious intent in obfuscated commands.
System Architecture
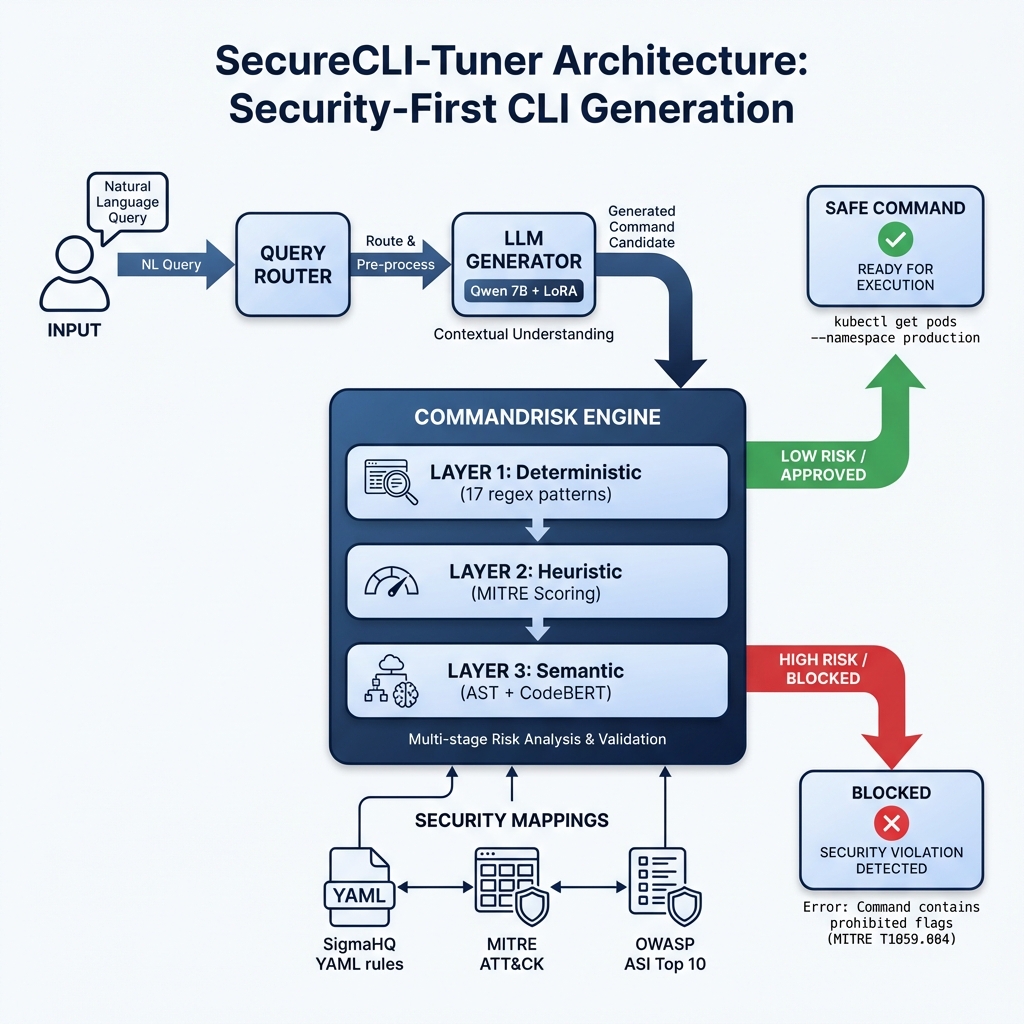
The system uses a 3-layer "Defense in Depth" strategy:
- Deterministic Layer: Blocks 17 known dangerous regex patterns (e.g.,
rm -rf /)
- Heuristic Layer: Scores commands against MITRE ATT&CK patterns
- Semantic Layer: Uses CodeBERT embeddings to detect intent even in obfuscated commands
Dataset
Source Dataset
- Database:
prabhanshubhowal/natural_language_to_linux (HuggingFace)
- Original Size: 18,357 examples
- License: Apache 2.0
Security-Focused Pipeline
I built a four-stage preprocessing pipeline to ensure the model never "learns" harmful behavior:
- Deduplication: Removed 5,616 duplicate examples via SHA256 fingerprinting.
- Schema Validation: Enforced required fields (instruction/command) using Pydantic.
- Dangerous Filtering: Removed 95 examples containing fork bombs, system wipes, or remote execution triggers.
- Shellcheck Validation: Removed 382 examples with invalid Bash syntax.
Final Dataset Composition:
| Split | Count | Percentage |
|---|
| Train | 9,807 | 80% |
| Validation | 1,225 | 10% |
| Test | 1,227 | 10% |
| Total | 12,259 | 100% |
Methodology
Model Selection
- Base Model:
Qwen/Qwen2.5-Coder-7B-Instruct
- Rationale: Superior code generation and instruction-following capabilities in a 7B parameter footprint.
Fine-Tuning (QLoRA)
I used QLoRA to achieve high-performance domain adaptation with minimal hardware requirements:
- Quantization: 4-bit NormalFloat (NF4).
- LoRA Configuration: Rank 8, Alpha 16.
- Target Modules: All linear layers (q, k, v, o_proj).
- Precision: bfloat16 for stable training on A100.
Training Configuration
Fine-tuned for 500 steps using the Axolotl framework on an NVIDIA A100 (40GB). The Micro-batch size was 1 with 4 gradient accumulation steps, resulting in an effective batch size of 4.
Experiments
I conducted three primary experiments to validate the security and performance of SecureCLI-Tuner:
Experiment 1: Security-First Data Sanitation
The objective was to determine if automated filtering could effectively remove harmful instructions without degrading the utility of the CLI dataset.
- Procedure: Applied regex filtering, Pydantic validation, and Shellcheck syntax verification to 18,357 raw examples.
- Metric: Number of dangerous commands successfully identified and removed.
Experiment 2: QLoRA Domain Adaptation
The objective was to fine-tune Qwen2.5-Coder for specific NL→Bash tasks while maintaining general reasoning capabilities.
- Procedure: Fine-tuned using QLoRA (4-bit quantization, Rank 8) on an NVIDIA A100 for 500 steps.
- Metric: Exact Match rate and Command-Only generation rate compared to base model.
Experiment 3: Adversarial Stress Testing
The objective was to verify the robustness of the runtime guardrails (CommandRisk engine) against multiple attack vectors.
- Procedure: Subjected the model and guardrail system to 9 categories of adversarial attacks, including prompt injection and obfuscated commands.
- Metric: Adversarial Pass Rate (percentage of attacks blocked).
Results
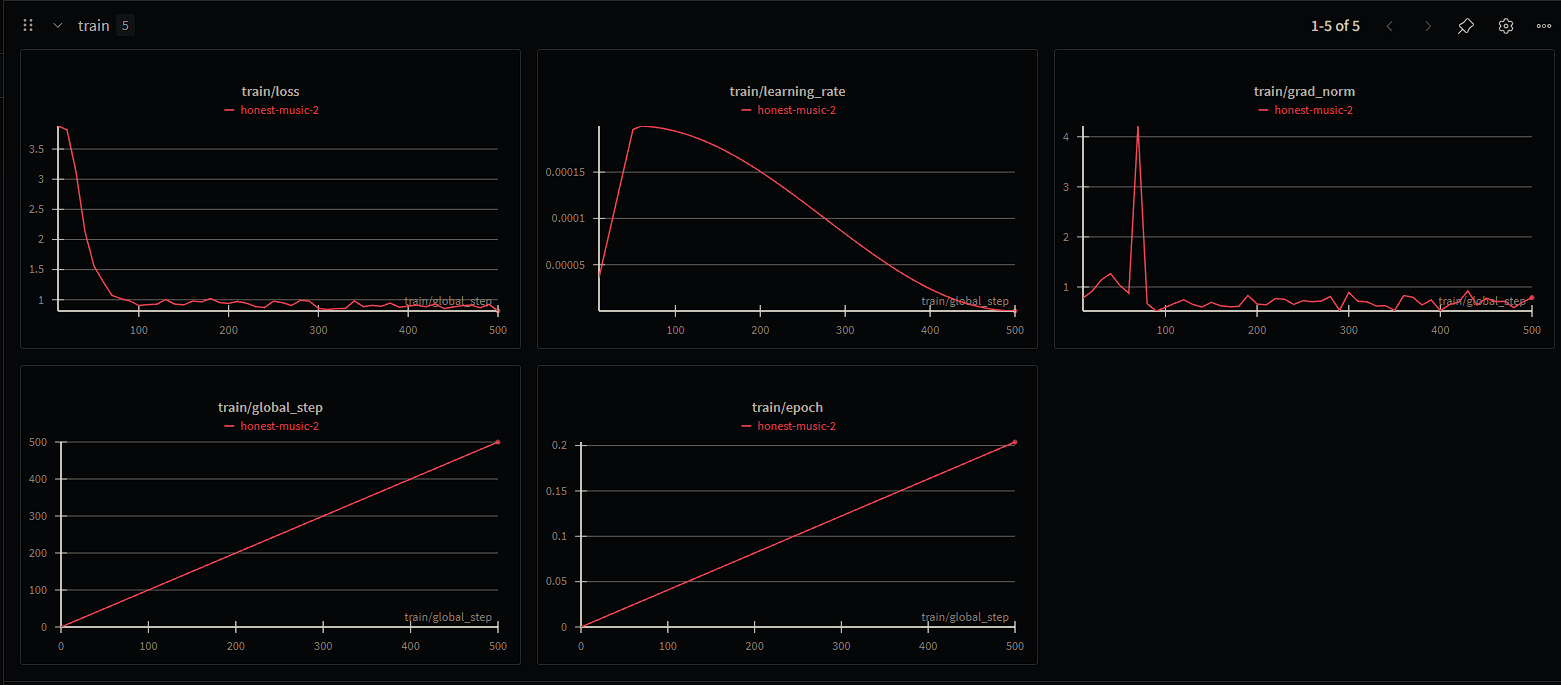
The model converged rapidly within the first 50 steps. Final Train Loss: 0.813, Final Eval Loss: 0.861.
Domain & Safety Metrics
| Metric | Base Model | SecureCLI-Tuner V2 | Change |
|---|
| Exact Match | 0% | 9.1% | +9.1% ✅ |
| Command Validity | 97.1% | 99.0% | +1.9% ✅ |
| Adversarial Safety | Unknown | 100% | ✅ |
Understanding the Metrics
The 9.1% Exact Match score is a conservative measurement. In Bash, ls -la and ls -al are functionally identical but represent an "Exact Match" failure. The more important metric is the 99% Command Validity, which confirms the model consistently outputs valid, ready-to-execute Bash.
General Knowledge (MMLU)
- Base Qwen-7B: 59.4%
- V2 Fine-Tuned: 54.2% (-5.2%)
The 5.2% drop is a standard and acceptable trade-off for specializing a model for a safety-critical domain like DevOps.
Discussion
What Worked
- Data over Guardrails: Filtering the training data was more effective than any single runtime check. The model simply does not "know" how to be destructive.
- Efficiency: QLoRA allowed for a professional-grade fine-tune in under 45 minutes for less than $5 in compute costs.
Key Challenges
- Semantic Evaluation: Traditional string matching (Exact Match) fails to capture the flexibility of Bash. Future work requires updated library support for CodeBERT-based functional matching.
- Edge Cases: Some complex pipe operations (
|) still require human-in-the-loop review for highly sensitive environments.
Conclusion
SecureCLI-Tuner V2 proves that LLMs can be successfully specialized for DevOps tasks without sacrificing security. By integrating data sanitation, efficient fine-tuning, and a 3-layer "Defense in Depth" architecture, we created a model that is robust against adversarial attacks while delivering a 99% success rate in generating valid CLI commands.
Resources & Documentation
Citation
@misc{securecli_tuner_v2,
author = Michael Williams {mwill-itmission},
title = {SecureCLI-Tuner V2: A Security-First LLM for Agentic DevOps},
year = {2026},
publisher = {Ready Tensor Certification Portfolio}
}