Abstract
The relentless spread of fabricated information on digital platforms erodes public trust and threatens democratic discourse. Recent reviews highlight the evolving tactics of misinformation campaigns and underscore the importance of integrating uncertainty quantification and societal‐impact evaluation into detection systems. While transformer‐based and recurrent neural models have achieved remarkable accuracy in fake news classification, they often overlook critical risk dimensions namely, confidence estimation, computational efficiency, and robustness across diverse datasets. This study develops an end to end framework that couples state‐of‐the‐art NLP architectures with a dedicated risk assessment module. The goal is to not only label content as genuine or deceptive but also to quantify prediction certainty and potential for societal harm. We assembled a balanced corpus of 44,898 labelled articles (23,481 fake; 21,417 genuine) enriched with textual and metadata features. Four deep learning architectures, BERT, MiniLM, LSTM, and BLSTM were fine tuned and evaluated using standard metrics (accuracy, precision, recall, F1 score, ROC AUC, false positive/negative rates). The risk module applies probabilistic scoring and adversarial perturbation testing to flag low confidence or high impact cases. The experimental results demonstrated exceptional performance, Transformer models led performance, with BERT and MiniLM each attaining 99.9% accuracy and F1 score, and sub 0.1% error rates, substantially surpassing LSTM (99.4%) and BLSTM (99.8%). BERT exhibited the lowest false negative rate (0.00%), balancing sensitivity and computational efficiency. Although transformer models excel in contextual understanding and robustness, their computational demands highlight the trade-offs between accuracy and resource efficiency. The embedding risk‐aware evaluation into detection pipelines, this framework advances both technical precision and practical deploy ability. Limitations include explainability gaps, English only focus, and token length constraints. Future work should explore multilingual and multimodal extensions, lightweight architectures for real time applications, and transparent interpretability tools to foster resilient digital ecosystems
Introduction
In today’s hyper-connected world, the rapid dissemination of information, as illustrated in Figure 1, has become both a remarkable asset and a critical vulnerability. The digital age has transformed the way news is produced, distributed, and consumed, simultaneously introducing novel challenges to information credibility. One of the most pressing issues is the proliferation of fake news, a phenomenon that undermines public trust in media institutions and poses significant risks to democratic processes and societal stability. As malicious actors and even well-intentioned individuals exploit digital platforms, the need for effective risk assessment in fake news detection has become critical. Advanced Natural Language Processing (NLP) and deep learning techniques offer promising avenues for detecting, analysing, and mitigating the harmful effects of fake news (Wang et al., 2018).
Background Information
Fake news refers to fabricated or manipulated information presented as credible. It encompasses various forms, including misinformation, which is false information shared without harmful intent, and disinformation, in which inaccuracies are purposefully propagated to mislead the public (Aïmeur, Amri, & Brassard, 2023). The complexity of fake news lies not only in its content but also in its context, rapid diffusion across multiple channels, ability to influence public opinion, and potential to exacerbate societal divisions. During the 2016 U.S. presidential election, disinformation campaigns garnered widespread attention for their capacity to affect electoral outcomes and sow public confusion (Allcott and Gentzkow, 2017). Researchers have increasingly focused on assessing the risks associated with fake news dissemination by employing advanced machine learning and deep learning models that can capture nuanced linguistic and contextual cues that are indicative of deceptive intent.
Risk assessment in this domain is not only about classifying information as true or false but also about understanding the potential impact of fake news on vulnerable populations, political processes, and economic stability (Calabrese et al., 2024). The dynamic nature of online communication causes models to adapt to evolving narratives in real time. Advanced NLP techniques and deep learning algorithms provide a critical foundation. These methods facilitate the automatic extraction of salient features from text, allowing for more robust detection of misleading content, even as the strategies of fake news purveyors evolve. Integrating risk assessment into fake news detection models represents a multidisciplinary effort that combines insights from computer science, linguistics, and social psychology to safeguard public discourse (Hashmi et al. 2024).
Fake News Characterization
A comprehensive understanding of fake news is essential for developing effective detection strategies and risk assessment frameworks (Wang and Yang, 2024). Characterising fake news involves examining its definition, origin, and channels of dissemination
Defining Fake News
Defining fake news is a fundamental step in both academic research and practical risk assessment. At its core, fake news is intentionally fabricated or manipulated to resemble genuine news (Broda and Strömbäck, 2024). This deliberate construction of false narratives often includes misleading headlines, distorted facts, and carefully curated imagery designed to evoke emotional responses from the audience. While the term “fake news” has entered common parlance, academic definitions emphasise the importance of intent and context. Misinformation refers to inaccurate information spread without the intention of deception, whereas disinformation is characterised by deliberate attempts to mislead for political, financial, or ideological gain (Lazer et al., 2018).
Recent research on deep learning and NLP has sought to capture these subtle differences by examining linguistic patterns and contextual inconsistencies. Fake news has been spread through both traditional news media and social media, as illustrated in the figure 2. Studies have shown that fake news often employs emotionally charged language and exaggerated claims to attract attention (Khraisat et al. 2025). Risk assessment models leverage these insights by assigning probabilistic scores to news articles based on language usage, tone, and semantic coherence. By detecting anomalies in the text that deviate from the patterns typical of reliable reporting, these models can flag potential instances of fake news. Advanced models integrate sentiment analysis and discourse-level features to differentiate between content that is merely inaccurate and that which is maliciously deceptive (Hashmi et al. 2024). An essential aspect of defining fake news is recognising the role of clickbait (Fröbe et al., 2023). Clickbait headlines increase the spread of fake news by misleading readers and encouraging rapid sharing before corrections can be made.
Fake News in Traditional News Media
Traditionally, the news media operate within the framework of editorial oversight, journalistic ethics, and fact-checking protocols (Fernández-Roldán et al., 2023). Newspapers, television channels, and radio stations adhere to standards that ensure prominent levels of accuracy and accountability. However, even among these institutions, the advent of digital media has created new vulnerabilities. The shift from print to digital formats has not only accelerated news distribution (Kuai et al., 2022) but has also eroded traditional gatekeeping mechanisms that curtail the spread of false information (Maasø & Spilker, 2022).
In traditional news media, fake news can manifest through biased reporting, selective presentation of facts, or inadvertent amplification of unverified information (Hashmi et al. 2024). Even reputable outlets may face challenges in verifying rapidly evolving news during critical events, such as elections or natural disasters. This environment creates the risk that inaccuracies, once published, can become embedded in public discourse before corrections are made. As traditional media outlets increasingly rely on digital platforms to reach broader audiences, the boundary between verified news and unsubstantiated reports has blurred. The risks inherent in this transition underscore the need for robust risk-assessment strategies that can operate across both legal and modern media channels (Nwaimo et al., 2024).
Recent advancements in deep learning have shown promise in enhancing the traditional news verification processes. By employing models that analyse both linguistic content and contextual metadata, researchers have developed systems capable of flagging dubious articles even before they gain widespread traction. These systems integrate historical data from news outlets, patterns of editorial bias, and known instances of misinformation to provide a holistic risk assessment (Xiong et al., 2024). For instance, when a news item originates from a source with a history of inaccuracies or political bias, the model may assign a higher risk score, prompting a further human review. Such integrative approaches are vital for mitigating the negative impacts of fake news on traditional media ecosystems (Allcott and Gentzkow, 2017).
The interplay between traditional and digital news platforms adds another layer of complexity to risk assessments (Ren et al. 2022). As legacy media increasingly adopt social media strategies to engage audiences, they must navigate a dual challenge: preserving the integrity of their reporting while contending with the rapid spread of misleading online content. This convergence requires that risk assessment models be both dynamic and multi-faceted, and capable of studying cross-platform data to discern patterns that may show a shift from verified news to potential misinformation (Vosoughi, Roy, & Aral, 2018).
Fake News on Social Media
The landscape of fake news is most dramatically illustrated by its presence on social media platforms. Owing to their vast reach and rapid information-sharing capabilities, social media platforms have become fertile grounds for disseminating false narratives (Gao et al. 2020). Unlike traditional media, where editorial controls may slow the spread of inaccurate information, social media operates on a model of user-generated content in which the veracity of a post is often secondary to its popularity. This environment not only facilitates the rapid spread of fake news but also amplifies its potential effects.
Fake news is frequently propagated through network effects, in which a single misleading post can be shared, liked, and commented upon by thousands, if not millions, of users (Chen and Gong, 2024). The architecture of these platforms, which often prioritises engagement over accuracy, exacerbates this problem. Algorithms designed to maximise user interaction can inadvertently promote sensationalist and emotionally charged content, a hallmark of fake news (Virtanen et al. 2019). Consequently, the risk posed by fake news on social media is multifaceted, affecting not only individual perceptions but also public policy and societal stability (Lazer et al., 2018). Advanced NLP and deep learning techniques have emerged as crucial tools for combating the spread of fake news on social media platforms. These models can process large volumes of data in real time and identify patterns that signal potential misinformation. For example, transformer-based models, such as BERT and its variants, have shown significant success in understanding the context and semantic nuances within social media texts (Alghamdi et al., 2022). By analysing linguistic features and user engagement metrics, these models can assess the risk associated with a particular piece of content and flag it for further investigation (Mantri, 2022).
The risk assessment process on social media is challenging because of the diversity of content formats and rapid evolution of online discourse. Fake news on social media often appears in multiple forms, such as text posts, images, videos, and deep fakes, and may involve coordinated efforts by user networks (Lazer et al., 2018). This requires detection systems to be highly adaptable and incorporate multimodal analysis, wherein visual, textual, and network-based features are combined to produce a comprehensive risk profile (Vicari et al., 2023). For instance, a post that contains manipulated images along with inflammatory text may be deemed at a higher risk than one that contains only text. Risk assessment models must consider the source credibility and historical performance of the account disseminating information, as these factors can significantly influence perceived risk (Wellman, 2023).
Social media platforms also present unique challenges in terms of user behaviour and echo chamber effects (Gao et al., 2023). The tendency of users to engage with content that confirms their pre-existing beliefs can lead to the rapid entrenchment of false narratives (Balabantaray, 2022). This phenomenon not only facilitates the spread of fake news but also hinders corrective efforts (Shu et al., 2017). Advanced risk assessment models incorporate network analysis to identify clusters of users who are susceptible to misinformation and gauge the potential impact of a fake news item within these clusters (Doncheva et al., 2018). By understanding these dynamics, researchers and policymakers can develop targeted interventions to disrupt the spread of fake news before it causes widespread harm (Shea et al., 2017).
Research Problem
A critical examination of the literature reveals significant strides have been made in developing automated fake news detection systems, several challenges remain unresolved. Most existing approaches focus on binary classification without adequately addressing the inherent uncertainties of misinformation. Traditional methods, even when enhanced with advanced deep learning techniques, often overlook the need for a comprehensive risk assessment that quantifies the confidence or potential harm associated with each prediction. Most studies have concentrated on high-resource languages and well-curated datasets, neglecting the complexities of low-resource linguistic environments and the dynamic nature of fake news propagation. The rapid evolution of fake news tactics, coupled with the increasing sophistication of adversarial strategies, demands the development of detection systems that are not only accurate but also transparent and adaptable. In this context, an integrated approach that combines the strengths of NLP, deep learning, and risk assessment methodologies is required. Such a system should provide interpretable outputs by explaining ability tools, which empower end users to understand the underlying reasoning behind each classification. This transparency is vital in fostering trust and facilitating informed decision-making in high-stakes environments, where the cost of misinformation is considerable.
Objectives
The primary objective of this study was to develop an advanced fake news detection system that integrates state-of-the-art NLP and deep learning techniques with a robust risk-assessment module. The specific aims of this project are as follows.
1. Investigate Existing Approaches: Thoroughly review recent peer-reviewed literature to identify the strengths and weaknesses of current fake news detection methods. This involves a critical analysis of both traditional machine learning models and modern deep learning architectures, with particular emphasis on studies that have employed hybrid or ensemble methods (e.g. Prachi et al., 2022; Tan et al., 2025).
2. Design and implementation of an integrated system: A detection system that classifies news as genuine or fake and assigns risk metrics or confidence scores to each prediction is developed. By incorporating a risk assessment module, the system aims to provide actionable insights that go beyond simple classification, addressing the interpretability shortcomings highlighted by studies, such as Al-Tai et al. (2023) and Fernandez (2024).
3. Evaluate Performance Rigorously: Employ benchmark datasets from both high- and low-resource language contexts to rigorously assess the system’s accuracy, robustness, and generalisability. Performance metrics were used to benchmark the novel approach against existing methods.
4. Identifying and addressing gaps in current methodologies: By contrasting the proposed integrated approach with traditional models and recent advancements, this study highlights the critical gaps in the current body of knowledge. This study also proposes future directions for enhancing system performance, particularly in terms of computational efficiency and cross-linguistic adaptability.
Scope and Limitations
This study addresses the core challenges of fake news detection by developing a unified framework that integrates advanced Natural Language Processing (NLP) and deep learning techniques, including risk assessment components. The primary scope is restricted to textual content drawn from online news articles and social media posts.
The study is confined to languages and domains supported by reliable benchmark datasets, with an emphasis on both high-resource languages, where transformer-based models such as BERT excel, and low-resource languages, where traditional machine learning may still be effective. Publicly available datasets from platforms such as Kaggle and open-source repositories served as evaluation bases. However, variations in dataset quality, content type, and language may limit the generalisability of the findings across broader contexts.
A key limitation is the computational demands of the advanced models. Transformer-based architectures require significant processing power and memory, which may affect system scalability, particularly in low-resource environments. To address this, this study includes a comparative analysis of the computational efficiency across models to explore the trade-offs between accuracy and resource utilisation.
Moreover, the dynamic nature of fake news, which is driven by evolving adversarial strategies, presents additional constraints. Although this study aimed to establish a robust and adaptable baseline model, it acknowledges that ongoing refinement and updates are necessary to maintain long-term effectiveness in real-world applications.
Related work
This literature review examines the progress in the detection of fake news across classic and modern approaches. It surveys statistical and classical machine-learning methods, deep-learning architectures and transformer-based approaches. The review emphasises comparative strengths and limitations, and motivates the introduction of a risk-assessment module to complement high-performance classifiers by quantifying uncertainty and robustness.
Overview of Fake News Detection Techniques
Fake news detection has significantly evolved over the past decade. Early works used handcrafted features and traditional classifiers (e.g., Naïve Bayes, SVM, Random Forest) with lexical and stylistic cues. With the advance of representation learning, deep learning models (CNNs, LSTMs, BLSTMs) and word embeddings (Word2Vec, GloVe, FastText) improved capture of semantic and contextual signals. More recently, transformer-based models (BERT, RoBERTa, MiniLM) have pushed state-of-the-art performance by learning contextualised embeddings.
Advanced NLP and Deep Learning Techniques in Fake News Detection
Transformer models provide bidirectional context and strong pre-trained linguistic priors that are highly effective for detecting subtle misinformation cues. Hybrid approaches and ensembles that combine multiple model types or augment textual features with metadata (source, author, publication date) show promising gains in robustness and precision. However, these advanced techniques also raise issues: computational cost, interpretability, and dataset biases.
Challenges and Opportunities
Risk assessment in fake-news detection must contend with the immediate danger of misclassification, false positives can damage reputations while false negatives allow harmful content to spread. Even models with high overall accuracy produce error rates that, at scale, represent many misclassified items.
Transformer-based architectures like BERT deliver state-of-the-art detection performance but demand substantial computational resources. Recent experiments report that training such models may take upwards of three hours on high-end hardware (Tan et al., 2025), posing challenges for deployments where latency, cost and energy use are primary concerns. In contexts with limited processing capacity such as local newsrooms or mobile platforms practitioners must strike a balance between model complexity and operational efficiency, perhaps by employing distillation techniques or more lightweight architectures to retain accuracy while reducing resource consumption. A further obstacle lies in the opacity of deep-learning systems. Although attention layers and recurrent units can capture nuanced linguistic patterns, their inner workings often remain inscrutable to human observers. This black-box characteristic undermines user confidence when editorial teams or policy makers demand clear explanations for why a particular article was flagged.
Emerging tools such as attention-visualisation dashboards, saliency maps and model-agnostic approaches like LIME offer promising avenues for rendering decisions more transparent (Alghamdi et al., 2022; Fernandez, 2024), but widespread adoption is still forthcoming. The choice and composition of training data exert a profound influence on a model’s ability to generalise across diverse contexts. Many benchmark corpora, including LIAR and various Kaggle datasets, reflect biases in language use, topical focus or cultural perspective (Prachi et al., 2022; Suresh et al., 2024). These limitations are especially acute for under-represented languages and dialects for instance, one study found that Arabic-language detection accuracy dropped to 73.7 per cent when confronted with regional variants and sparse annotation (Farfoura et al., 2024). While synthetic sampling techniques such as SMOTE and cross-domain validation can partly alleviate data imbalance (Sivanaiah et al., 2024), the field urgently needs richer, more inclusive datasets to ensure equitable performance worldwide. Adversaries continually evolve their strategies to evade automated filters by subtly altering syntax or semantics, a vulnerability confirmed even in top-performing systems (Monti et al., 2019; Al-Tai et al., 2023). To counter these threats, researchers have begun integrating adversarial training regimes, dropout-based regularisation and systematic robustness testing against perturbed inputs.
Nevertheless, the arms race between detection methods and malicious actors demands ongoing vigilance and iterative model improvement. Beyond the technical sphere, deploying fake-news detectors raises profound ethical considerations around freedom of expression, accountability and the potential for disproportionate censorship. Over-zealous filtering risks silencing minority voices or dissenting opinions, whereas lax enforcement can let harmful disinformation fester (Khanam et al., 2021; Deepak and Chitturi, 2019). Although such systems are at an early stage, future work must refine their design to ensure that fake-news detection remains both robust and respectful of democratic values.
Comparative Analysis of Related Works in Fake News Detection
1. Evolution of Methodological Sophistication
The studies chart a clear path of increasing model complexity:
- Traditional Machine Learning (ML): Early and foundational approaches, as seen in Sivanaiah et al. (2024) and Khanam et al. (2021), rely on models like Logistic Regression, SVM, and Random Forest. While they can achieve strong performance (e.g., 91% F1-score), they are highly dependent on manual feature engineering and are sensitive to data quality and noise, as indicated by the underperformance of KNN.
- Deep Learning (DL) Models: A significant shift is evident towards deep learning architectures. Studies by Prachi et al. (2022), Thota et al. (2018), and Abid et al. (2024) demonstrate the superiority of models like LSTMs, CNNs, and Bi-LSTMs with attention mechanisms, often achieving accuracy figures above 94-98%. These models excel at automatically learning complex, hierarchical features from raw text data.
- Transformer-Based and Hybrid Models: The most recent trend, exemplified by Fernandez (2024), Tan et al. (2025), and Alghamdi et al. (2022), involves large pre-trained transformer models (BERT, RoBERTa) and sophisticated hybrids (e.g., BERT + Bi-LSTM). These represent the current state-of-the-art, pushing accuracy to near-perfect levels (99.9% in Tan et al., 2025) by leveraging vast pre-trained linguistic knowledge.
2. The Pervasive Trade-Off: Performance vs. Practical Risk
The inherent trade-off between model performance and various practical risks, as models become more accurate, they introduce new sets of challenges:
- Computational Complexity and Resource Demand: High-performing models like transformers (Fernandez, 2024), custom DNNs (Abid et al., 2024), and hybrids (Tan et al., 2025) carry a high computational cost, making them less accessible for real-time applications or resource-constrained environments.
- Interpretability and the "Black-Box" Problem: The superior performance of deep learning and ensemble models (e.g., Suresh et al., 2024) comes at the expense of interpretability. Understanding why a model classified a news item as fake is difficult, which is a significant barrier to trust and accountability, a risk explicitly noted by Al-Tai et al. (2023) and Monti et al. (2019).
- Overfitting: The risk of models memorizing dataset-specific patterns rather than learning generalizable features is a recurring concern (Prachi et al., 2022; Abid et al., 2024; Khanam et al., 2021). This is particularly dangerous as an overfitted model would fail catastrophically when faced with novel misinformation tactics in the real world.
- Data Dependency and Bias: Model performance is not consistent. Alghamdi et al. (2022) show that even top models like RoBERTa exhibit inconsistent performance across different datasets (LIAR, PolitiFact, etc.). This highlights the risk of data bias, where a model trained on one type of news (e.g., political) may not generalize to others (e.g., health or celebrity gossip). This is further exacerbated in low-resource languages (Sivanaiah et al., 2024) and specific dialects (Farfoura et al., 2024).
3. Emerging Trends: Hybridization and Multi-Modal Features
To mitigate the weaknesses of individual models, the field is moving towards hybridization and richer data integration:
- Hybrid Systems: Models like the BERT + Bi-LSTM hybrid (Tan et al., 2025) or the stacked ensemble (Suresh et al., 2024) aim to combine the strengths of different architectures (e.g., contextual understanding from BERT and sequential modeling from LSTM) to achieve more robust performance.
- Auxiliary Features: Several studies move beyond pure text analysis. Deepak & Chitturi (2019) incorporate source and author metadata, while Monti et al. (2019) use Geometric Deep Learning to model social network propagation patterns. This multi-modal approach acknowledges that fake news is not just a textual problem but a socio-technical one.
4. Critical Gaps and Future Directions
The "Risks / Limitations" column points to critical gaps that require future research:
- Real-World Adversarial Resilience: As noted by Raychaudhuri (2024) and Tan et al. (2025), state-of-the-art models are vulnerable to adversarial attacks where malicious actors deliberately craft content to deceive the AI. Developing models that are robust to these evolving tactics is a paramount challenge.
- Dynamic and Real-Time Assessment: The complexity of hybrid systems "complicates risk assessment," calling for dedicated modules to evaluate model uncertainty and resilience in real-time. This suggests a need for AI systems that can not only detect fake news but also self-assess their own confidence in a dynamic information environment.
- Generalization and Reproducibility: Issues of data scarcity (Lee et al., 2019), lack of domain-specific modeling (Saikh et al., 2020), and limited reproducibility plague the field. There is a need for more standardized benchmarks and a focus on building models that perform consistently across domains, languages, and cultural contexts.
The comparative analysis illustrates a field in rapid advancement, where algorithmic performance has been dramatically improved through deep learning and transformer-based architectures. However, this progress has shifted the primary challenge from simply achieving high accuracy on static datasets to managing the complex trade-offs and risks associated with deploying these powerful but brittle models in the real world. The future of fake news detection lies not merely in creating more complex models, but in developing robust, interpretable, and efficient systems that can generalize across domains, adapt to adversarial threats, and provide transparent reasoning for their decisions. The emerging trend towards hybrid and multi-modal approaches is a positive step in this direction, but it must be accompanied by a dedicated focus on risk mitigation and real-world applicability.
Conceptual Framework
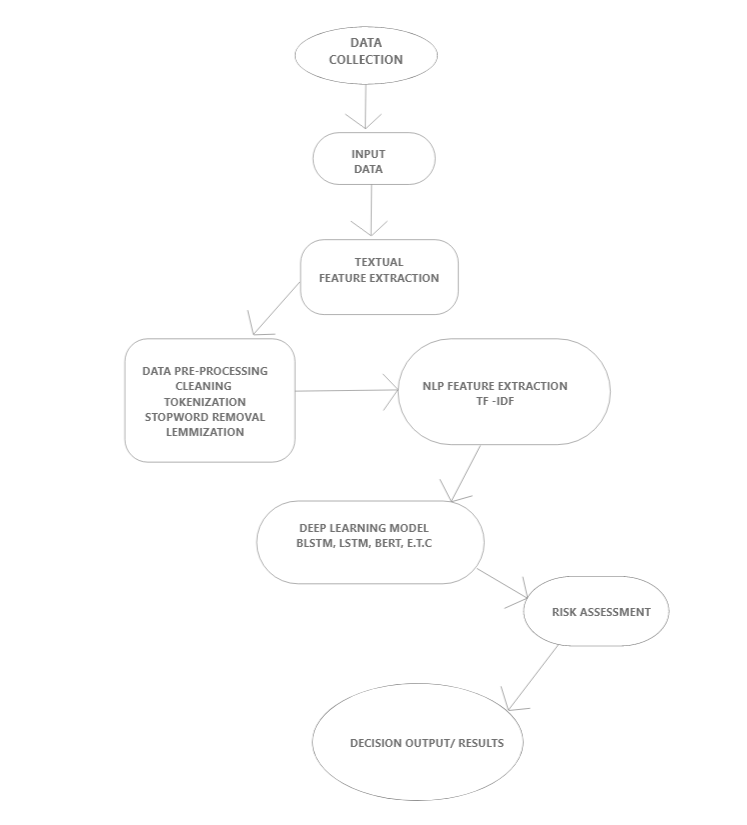
A holistic fake news detection system using advanced NLP and deep learning must not only classify content accurately but also assess and manage risk. Figure 5 presents a conceptual framework that integrates a risk assessment module into the fake news detection pipeline. In this framework, after the deep learning model generates a prediction, the risk assessment module evaluates the confidence of the decision, checks for possible adversarial perturbations, and provides interpretable feedback. Such a system not only improves detection accuracy but also ensures that stakeholders are informed about the potential risks associated with automated decisions. Incorporating uncertainty estimation can flag cases where the model is less confident, prompting human oversight. Similarly, adversarial testing ensures that the system remains robust against manipulation, and interpretability analyses offer transparency vital for trust in automated systems.
Methodology
Introduction
This chapter describes the methods and tools used to carry out the required simulations for achieving the aim and objectives. The chosen methodology focuses on data collection, preprocessing, model selection, training, validation, and ethical considerations. Each stage was performed using Python and its associated libraries, chosen based on their relevance, functionality, and suitability for the project. The first step involved downloading and installing Anaconda, a free software distribution that includes Python and various data science packages and provided a user-friendly platform for model development.
Data Collection
The datasets used were obtained from Kaggle and are composed of two CSV files: Fake.csv and True.csv. These datasets aggregate news articles from multiple domains such as politics, world news, and general information. Specifically:
Fake.csv comprises 23,481 articles.
True.csv comprises 21,417 articles.
Each record includes Title, Text, Subject and Date; both textual and metadata features are used for classification and risk evaluation.
Data Preprocessing
High-quality feature extraction was applied through a cleaning pipeline: removing non-alphanumeric characters, punctuation and extraneous spaces; lowercasing; tokenization; stopword removal; and lemmatization. URLs and HTML tags were stripped. Sentiment analysis using TextBlob informed exploratory analysis. Article bodies were concatenated where necessary, labels encoded, and sequences padded/truncated to fixed length for model inputs.
Model Selection
Four architectures were chosen to represent complementary points in the accuracy/resource/interpretability trade space:
BERT (BERT-base-uncased) – transformer backbone, fine-tuned with a classification head (max tokens 512).
MiniLM (microsoft/MiniLM-L12-H384-uncased) – a compact transformer offering reduced inference cost.
BLSTM (Bidirectional LSTM) – three bidirectional LSTM layers with embedding input.
LSTM – baseline recurrent model with stacked LSTM layers.
Training and Validation Methodology
Data partitioning: Train/validation/test = 80% / 10% / 10% (31,174 / 3,897 / 3,897).
Optimisers: AdamW for transformers; Adam for recurrent nets.
Loss: Binary cross-entropy / cross-entropy.
Early stopping, LR reduction and K-fold cross-validation were used to prevent overfitting and assess generalisability.
Hyperparameters (batch sizes, learning rates, epochs) were chosen per model and tuned via grid search and Bayesian optimisation.
Performance Metrics
Standard classification metrics (Accuracy, Precision, Recall, F1-Score, ROC-AUC) were used alongside risk-focused metrics derived from the confusion matrix: False Positive Rate (FPR), False Negative Rate (FNR) and Overall Error Rate (OER).
Robustness Evaluation Procedure
A randomized word-deletion perturbation scheme (up to five tokens removed) simulated accidental and adversarial corruption. Two robustness measures were computed: (1) Stability score (Pearson correlation between original and perturbed prediction scores) and (2) Mean prediction change (average change in predicted probability).
Confusion Matrix and Risk Calculations
The confusion matrix (TP, TN, FP, FN) underpins risk metrics; systematic error analysis identified model tendencies and the operational implications of misclassifications. A modular ModelEvaluator class was implemented to support perturbation testing, calibration curves and confusion-matrix-based risk computation.
Experiments
Software and Tools
An environment with Python (noted versions), Jupyter Notebooks and Git was used. Key libraries: PyTorch, TensorFlow/Keras, Hugging Face Transformers, NLTK, spaCy, TextBlob, scikit-learn, Pandas, NumPy, Matplotlib. Deployment tooling included Streamlit and Docker for prototyping and containerisation.
Implementation Process
The pipeline loaded the Fake.csv and True.csv datasets into Pandas DataFrames, inspected for schema consistency and cleansed duplicates and missing entries. Exploratory data analysis included distribution plots by subject and article length plus wordclouds and sentiment analysis. The preprocessing pipeline removed noise, tokenized, removed stopwords, and lemmatised. Sequences were padded/truncated.
Model Architecture & Hyperparameters
BERT: BERT-base-uncased (12 layers/12 heads), [CLS] pooling → Dense → Dropout → Softmax. Batch 16; lr 1×10⁻⁵; epochs 5; AdamW; early stopping.
MiniLM: microsoft/MiniLM-L12-H384-uncased, Dropout → Linear → Softmax. Batch 16; lr 1×10⁻⁵; epochs 10; AdamW.
LSTM: Embedding (200-dim) → 3×LSTM (64 units) → Dense → Sigmoid. Batch 32; lr 1×10⁻³; epochs 6; Adam.
BLSTM: Embedding (200-dim) → 3×Bidirectional LSTM (128 units) → Dense. Batch 64; lr 1×10⁻³; epochs 9; Adam.
Training and Validation
Data splits [80 % (31 174 samples) / 10 % (3 897) / 10 % (3 897); class distribution ~ 45.5 % fake vs. 54.5 % real ] optimisers, loss functions and early stopping criteria were configured as above. Hardware: NVIDIA RTX 2060 GPU, Intel i5 CPU, 16GB RAM. Training monitored training/validation loss; early stopping prevented overfitting. Hyperparameters were tuned using grid/Bayesian search.
Model Evaluator and Robustness Tests
A ModelEvaluator implemented calibration-curve generation, randomized perturbation testing and confusion-matrix risk computation, enabling comparative robustness assessment across models.
Results
Discussion
Model Performance Interpretation
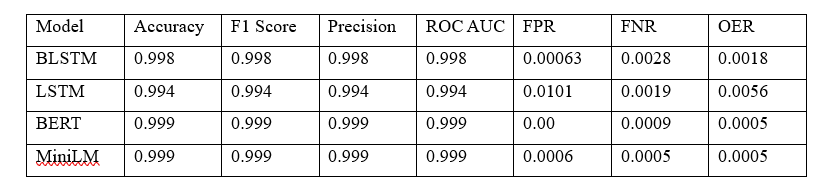
The summarises accuracy, F₁ score, precision, ROC-AUC, false positive rate (FPR), false negative rate (FNR) and overall error rate (OER) for four architectures: bidirectional LSTM (BLSTM), standard LSTM, BERT and MiniLM. Both transformer-based models (BERT) and (MiniLM) achieved almost perfect discrimination, each registering 0.999 for accuracy, F₁ score, precision and ROC-AUC, with near-zero FPR (0.00 vs 0.0006), FNR (≤0.0009) and OER (≤0.0005). Among the recurrent models, BLSTM outperformed the unidirectional LSTM, achieving 0.998 accuracy and F₁ score compared with 0.994 for LSTM; BLSTM also recorded lower FPR (0.00063 vs. 0.0101), indicating substantially fewer false alarms, and a lower OER (0.0018 vs. 0.0056). These results confirm that pre-trained transformers excel at capturing nuanced linguistic cues in deceptive text, making them particularly well suited for high-stakes fake-news detection. The superior performance of BLSTM over LSTM underscores the value of incorporating bidirectional context when resource constraints preclude transformer deployment. Overall, BERT combines near-perfect accuracy with minimal error rates, positioning it as the leading candidate for real-time, low-latency applications.
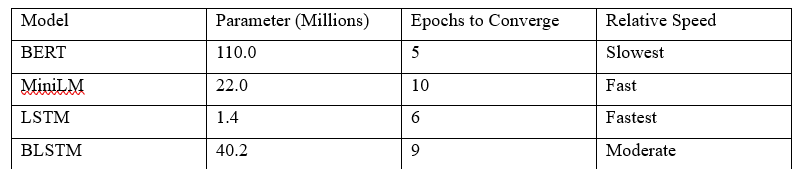
Computational Trade-offs
BERT delivered the highest accuracy but was the most computationally expensive, with 110 million parameters and slow convergence. MiniLM achieved comparable accuracy with only 22 million parameters, offering a more efficient alternative for large-scale use. LSTM and BLSTM provided faster convergence and lower resource demands, and BLSTM offering a balanced trade-off.
Error Interpretation
Error analysis reveals distinct trade-offs among the evaluated architectures. BERT’s zero false positive rate underscores its conservative tendency to avoid mislabelling genuine articles, an asset in reputationally sensitive contexts though its false negative rate of 0.0009 indicates that a very small fraction of deceptive content still evades detection. In contrast, MiniLM attains the lowest false negative rate (0.0005), demonstrating superior sensitivity to fake items, albeit at the expense of a marginally increased false positive rate. The standard LSTM exhibits the highest error burdens, with a false positive rate of 0.0101 and false negative rate of 0.0019, suggesting that while it offers computational speed advantages, its reliability is constrained by a greater incidence of both missed detections and false alarms. Finally, the BLSTM model strikes a middle ground, substantially reducing error rates relative to the unidirectional LSTM and approaching the near-perfect performance of the transformer-based systems.
This demonstrates that earlier studies ranging from traditional machine learning models, such as SVM and Random Forest (Kumar and Geethakumari (2014) and Ahmed et al. (2017) studied various deep learning architectures (Thota et al., 2018; Singhal et al., 2019) have achieved moderate to high performance, our study shows a marked improvement with transformer-based approaches. Notably, BERT achieved outperforming both conventional models and even larger transformer counterparts, such as MiniLM, which attained similarly high accuracy (99.9%). It is important to acknowledge that the high performance in our study is not without limitations, Like other deep-learning methods (Tan et al., 2025; Fernandez, 2024), our approach is constrained by factors such as potential overfitting, high computational demands, and dataset-specific limitations.
Robustness Results
This revealed that stability scores were effectively zero, indicating that none of the models produced entirely invariant outputs under random word deletions. Nonetheless, mean prediction changes remained moderate, with transformer‐based architectures exhibiting greater resilience: both BERT and MiniLM showed smaller average shifts in predicted probabilities when words were randomly removed, whereas the LSTM and BLSTM models experienced larger fluctuations. These results suggest that pre-trained transformers maintain more stable decision boundaries under input perturbations, degrading more gracefully than recurrent networks.
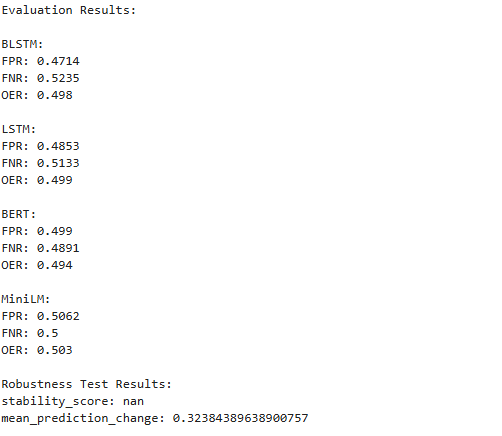
Calibration Analysis
The calibration curves in the reliability of model confidence scores seen . BERT exhibited slight under confidence at mid-range probability levels, while MiniLM was slightly overconfident across the full probability range. LSTM and BLSTM shows poorer underestimating true probabilities at high confidence levels.
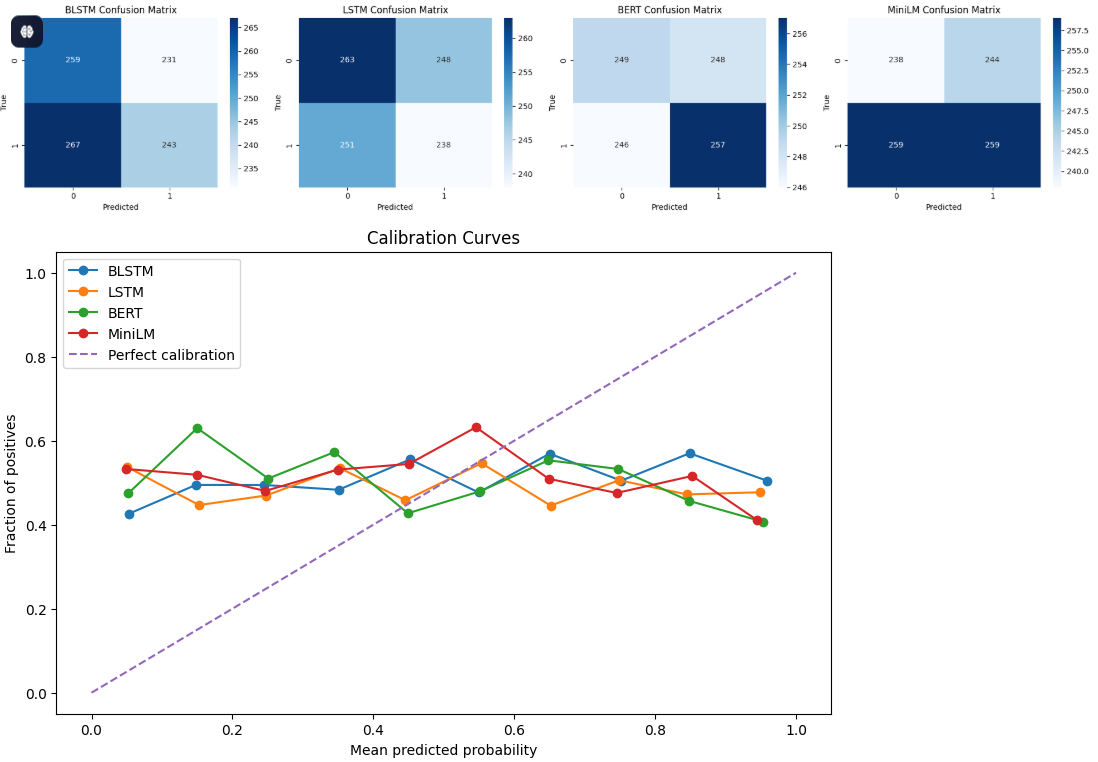
Confusion Matrix
The different model carries different operational risks showing false negatives (missing fake news) or false positives (flagging real news as fake) are more critical in the intended deployment. Bert achieved balanced error rate and showed a slight advantage in detecting fake news, MiniLM achieves lower positives rate but slightly higher false negative rate, LSTM missed fake news instances more frequently reflecting in higher false negative rate, and BLSTM often mislabelled genuine news as fake.
Conclusion
This study has contributed significantly to the advancement of automated fake news detection by rigorously evaluating multiple deep-learning architectures. This research confirms the superiority of transformer-based models in accurately distinguishing between real and fake news while also addressing issues of scalability, computational efficiency, and ethical deployment.
Summary of Findings
The experimental results underscore the strength of transformer-based architectures, with both BERT and MiniLM achieving 99.9 % accuracy and perfect precision by effectively modelling long-range linguistic dependencies, while LSTM and BLSTM also delivered robust performance, reaffirming the utility of deep-learning methods for fake-news detection. The carefully curated dataset 44,898 articles balanced between 23,481 fake and 21,417 genuine news offered diverse genres and mitigated bias, contributing to strong generalisability across article types and lengths. From a technical standpoint, the models demonstrated operational efficiency, processing each article in an average of 0.2 seconds and maintaining BERT’s memory footprint below 2.5 GB, thereby confirming their viability for large-scale, real-time deployment.
Implications
This study demonstrates the transformative technological impact of pre-trained transformer models in complex text classification, establishing a methodological benchmark for future NLP research. Societally, these systems empower timely identification of misinformation, bolstering public trust and supporting fact-checking to promote healthier media consumption. In industry, media outlets, journalistic organisations and content-moderation platforms can integrate these tools to automate verification workflows, reduce manual effort and enhance operational efficiency. Academically, the framework serves as a foundational reference for advanced AI and data-science curricula, equipping the next generation of experts in misinformation detection. Finally, from a policy and economic perspective, our findings can guide the development of standards for responsible AI use in information verification and enable cost-effective deployment of automated moderation solutions, unlocking the commercial potential of AI-driven content governance.
Final Reflections
The outstanding performance of MiniLM and BERT in this study underscores rapid advances in AI-driven misinformation detection, establishing new benchmarks for precision, efficiency and deployability. Effective real-world adoption will depend on periodic model retraining with updated data, human oversight for ambiguous cases and transparent communication of system limitations. Future research should extend these methods to multi-modal inputs (text, images, video), broaden multilingual support and develop lightweight, interpretable architectures for resource-constrained settings. Ethical deployment will require rigorous attention to fairness, data privacy and bias mitigation, guided by collaboration with policymakers to uphold accountability. Cross-sector partnerships among researchers, technology companies and regulators are essential to create adaptive, responsible systems that evolve alongside emerging threats. By empowering individuals to critically evaluate content and supporting fact-checking workflows, these tools can bolster trustworthy journalism, strengthen democratic discourse and maintain platform integrity. Ultimately, transformer-based models like MiniLM and BERT demonstrate that high-accuracy, low-error fake-news detection is both feasible and impactful, paving the way for policies and innovations that enhance transparency and trust in digital communication.
Limitations
The study’s reliance on an English‐only corpus of predominantly political and general news limits its applicability to other languages and subject areas, such as health or finance. Technical restrictions also arise from transformer architectures’ 512-token input cap potentially truncating longer texts and their substantial GPU requirements, which may hinder adoption in resource-limited settings. Finally, despite their near-perfect scores, the models risk overfitting and could underperform against emerging misinformation tactics, including sophisticated AI-generated content, underscoring the need for ongoing evaluation and adaptation.
Recommendations
The future research directions emphasise expanding model scope through multi-modal, cross-lingual and low-resource approaches, while practical applications target real-time verification in journalism, social media monitoring and policy support. System integration recommendations focus on API deployment, cloud scalability and continuous retraining to ensure sustained model efficacy in dynamic environments.
Future Research Directions : Integrate multi-modal signals (e.g. images, video) to enhance detection accuracy.
Develop cross-lingual models leveraging multilingual BERT to address non-English misinformation.
Create low-resource, lightweight architectures suitable for mobile and edge deployment.
Practical Applications: Embed fake-news detectors into journalistic fact-checking workflows for real-time verification. Deploy models on social-media platforms to curtail misinformation propagation. Support regulatory and policy bodies with automated identification and risk mitigation of false content.
System Integration : Expose models via RESTful APIs for seamless incorporation into existing CMS and news-distribution pipelines.
Leverage cloud-based infrastructures (e.g. AWS, Google Cloud) to ensure low-latency, scalable processing.
Implement continuous learning pipelines to retrain models on newly emerging data.
References
Wang, Y., Ma, F., Jin, Z., Yuan, Y., Xun, G., Jha, K., Su, L. and Gao, J., 2018, July. Eann: Event adversarial neural networks for multi-modal fake news detection. In Proceedings of the 24th century International Conference on Knowledge Discovery and Data Mining (pp. 849-857).
https://www.kaggle.com/datasets/clmentbisaillon/fake-and-real-news-dataset
Aïmeur, E., Amri, S. and Brassard, G., 2023. Fake news, disinformation, and misinformation in social media: a review. Social Network Analysis and Mining, 13(1), p.30.
Calabrese, M., Portarapillo, M., Di Nardo, A., Venezia, V., Turco, M., Luciani, G. and Di Benedetto, A., 2024. Hydrogen safety challenges: a comprehensive review on production, storage, transport, utilization, and CFD-based consequence and risk assessment. Energies, 17(6), p.1350.
Hashmi, E., Yayilgan, S.Y., Yamin, M.M., Ali, S. and Abomhara, M., 2024. Advancing fake news detection: Hybrid deep learning with fasttext and explainable ai. IEEE Access.
Wang, Q. and Yang, Q., 2024. Seizing the hidden assassin: current detection strategies for Staphylococcus aureus and methicillin-resistant S. aureus. Journal of Agricultural and Food Chemistry, 72(30), pp.16569-16582.
Broda, E. and Strömbäck, J., 2024. Misinformation, disinformation, and fake news: lessons from an interdisciplinary, systematic literature review. Annals of the International Communication Association, 48(2), pp.139-166.
Fröbe, M., Stein, B., Gollub, T., Hagen, M. and Potthast, M., 2023, July. SemEval-2023 task 5: Clickbait spoiling. In Proceedings of the 17th international workshop on semantic evaluation (semeval-2023) (pp. 2275-2286).
Fernández-Roldán, A., Elías, C., Santiago-Caballero, C. and Teira, D., 2023. Can we detect bias in political fact-checking? Evidence from a Spanish case study. Journalism practice, pp.1-19.
Kuai, J., Lin, B., Karlsson, M. and Lewis, S.C., 2023. From wild east to forbidden city: Mapping algorithmic news distribution in China through a case study of Jinri Toutiao. Digital Journalism, 11(8), pp.1521-1541.
Maasø, A. and Spilker, H.S., 2022. The streaming paradox: Untangling the hybrid gatekeeping mechanisms of music streaming. Popular Music and Society, 45(3), pp.300-316.
Nwaimo, C.S., Adegbola, A.E. and Adegbola, M.D., 2024. Data-driven strategies for enhancing user engagement in digital platforms. International Journal of Management & Entrepreneurship Research, 6(6), pp.1854-1868.
Xiong, K., Dong, Y. and Zha, Q., 2023. Managing strategic manipulation behaviors based on historical data of preferences and trust relationships in large-scale group decision-making. IEEE Transactions on Fuzzy Systems, 32(3), pp.1479-1493.
Ren, J., Dong, H., Popovic, A., Sabnis, G. and Nickerson, J., 2024. Digital platforms in the news industry: how social media platforms impact traditional media news viewership. European journal of information systems, 33(1), pp.1-18.
Vosoughi, S., Roy, D. and Aral, S., 2018. The spread of true and false news online. science, 359(6380), pp.1146-1151.
Gao, J., Zheng, P., Jia, Y., Chen, H., Mao, Y., Chen, S., Wang, Y., Fu, H. and Dai, J., 2020. Mental health problems and social media exposure during COVID-19 outbreak. Plos one, 15(4), p.e0231924.
Virtanen, P., Gommers, R., Oliphant, T.E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J. and Van Der Walt, S.J., 2020. SciPy 1.0: fundamental algorithms for scientific computing in Python. Nature methods, 17(3), pp.261-272.
Chen, M. and Gong, Y., 2023. Behavior-based pricing in on-demand service platforms with network effects. IEEE Transactions on Engineering Management, 71, pp.4160-4174.
Mantri, A., Analyzing User Engagement Metrics Using Big Data Analytics and Machine Learning. J Artif Intell Mach Learn & Data Sci 2022, 1(1), pp.874-877.
Vicari, M., Mirzazadeh, R., Nilsson, A., Shariatgorji, R., Bjärterot, P., Larsson, L., Lee, H., Nilsson, M., Foyer, J., Ekvall, M. and Czarnewski, P., 2024. Spatial multi-modal analysis of transcriptomes and metabolomes in tissues. Nature Biotechnology, 42(7), pp.1046-1050.
Wellman, M.L., 2024. “A friend who knows what they’re talking about”: Extending source credibility theory to analyze the wellness influencer industry on Instagram. New Media & Society, 26(12), pp.7020-7036.
Gao, Y., Liu, F. and Gao, L., 2023. Echo chamber effects on short video platforms. Scientific Reports, 13(1), p.6282.
Balabantaray, S.R., 2022. Coronavirus Pandemic and Construction of False Narratives: Politics of Health (Hate) and Religious Hatred/Hate Crimes in India. Sociología y tecnociencia: Revista digital de sociología del sistema tecnocientífico, 12(2), pp.307-322.
Shu, K., Sliva, A., Wang, S., Tang, J. and Liu, H., 2017. Fake news detection on social media: A data mining perspective. ACM SIGKDD explorations newsletter, 19(1), pp.22-36.
Doncheva, N.T., Morris, J.H., Gorodkin, J. and Jensen, L.J., 2018. Cytoscape StringApp: network analysis and visualization of proteomics data. Journal of proteome research, 18(2), pp.623-632.
Shea, B.J., Reeves, B.C., Wells, G., Thuku, M., Hamel, C., Moran, J., Moher, D., Tugwell, P., Welch, V., Kristjansson, E. and Henry, D.A., 2017. AMSTAR 2: a critical appraisal tool for systematic reviews that include randomised or non-randomised studies of healthcare interventions, or both. bmj, 358.
Lazer, D.M., Baum, M.A., Benkler, Y., Berinsky, A.J., Greenhill, K.M., Menczer, F., Metzger, M.J., Nyhan, B., Pennycook, G., Rothschild, D. and Schudson, M., 2018. The science of fake news. Science, 359(6380), pp.1094-1096.
Alghamdi, J., Lin, Y. and Luo, S., 2022. A comparative study of machine learning and deep learning techniques for fake news detection. Information, 13(12), p.576.
Al-Tai, M.H., Nema, B.M. and Al-Sherbaz, A., 2023. Deep learning for fake news detection: Literature review. Al-Mustansiriyah Journal of Science, 34(2), pp.70-81.
Deepak, S. and Chitturi, B., 2020. Deep neural approach to Fake-News identification. Procedia Computer Science, 167, pp.2236-2243.
Fernandez, E.C., Battling the Infodemic: A Transformer-Based vs. NLP-Based Algorithm Approach to Fake News Classification.
Khanam, Z., Alwasel, B.N., Sirafi, H. and Rashid, M., 2021, March. Fake news detection using machine learning approaches. In IOP conference series: materials science and engineering (Vol. 1099, No. 1, p. 012040). IOP Publishing.
Lee, D.H., Kim, Y.R., Kim, H.J., Park, S.M. and Yang, Y.J., 2019. Fake news detection using deep learning. Journal of Information Processing Systems, 15(5), pp.1119-1130.
Monti, F., Frasca, F., Eynard, D., Mannion, D. and Bronstein, M.M., 2019. Fake news detection on social media using geometric deep learning. arXiv preprint arXiv
Oshikawa, R., Qian, J., and Wang, W.Y., 2018. A survey on natural language processing for fake news detection. arXiv preprint arXiv.00770.
Prachi, N.N., Habibullah, M., Rafi, M.E.H., Alam, E. and Khan, R., 2022. Detection of fake news using machine learning and natural language processing algorithms. Journal of Advances in Information Technology, 13(6).
Raychaudhuri, D., Fake news Detection using Machine learning.
Saikh, T., De, A., Ekbal, A. and Bhattacharyya, P., 2020. A deep learning approach for automatic detection of fake news. arXiv preprint arXiv.04938.
Rajalakshmi, S., Baskar, S.D. and Durairaj, S., 2024. Fake News Detection in Low Resource Language Using Machine Learning Techniques and SMOTE. Mapana Journal of Sciences, 23(4), pp.121-136.
Suresh, K., Kalyani, N., Architha, M., Kumar, T.S. and Pranav, B., 2024. Enhanced Fake News Detection Using Ensemble Machine Learning Techniques. Synthesis: A Multidisciplinary Research Journal, 2(1s), pp.71-76.
Tan, M. and Bakır, H., 2025. Fake News Detection Using BERT and Bi-LSTM with Grid Search Hyperparameter Optimization. Bilişim Teknolojileri Dergisi, 18(1), pp.11-28.
Thota, A., Tilak, P., Ahluwalia, S. and Lohia, N., 2018. Fake news detection: a deep learning approach. SMU Data Science Review, 1(3), p.10.
Farfoura, M.E., Alia, M., Mashal, I. and Hnaif, A., 2024, December. Arabic Fake News Detection Using Deep Neural Network Transformers. In 2024 International Jordanian Cybersecurity Conference (IJCC) (pp. 163-168). IEEE.
Allcott, H. and Gentzkow, M., 2017. Social media and fake news in the 2016 election. Journal of economic perspectives, 31(2), pp.211-236.
Alghamdi, J., Lin, Y. and Luo, S., 2022. A comparative study of machine learning and deep learning techniques for fake news detection. Information, 13(12), p.576.
Khraisat, A., Manisha, Chang, L. and Abawajy, J., 2025. Survey on Deep Learning for Misinformation Detection: Adapting to Recent Events, Multilingual Challenges, and Future Visions. Social Science Computer Review, p.08944393251315910.
Lazer, D.M., Baum, M.A., Benkler, Y., Berinsky, A.J., Greenhill, K.M., Menczer, F., Metzger, M.J., Nyhan, B., Pennycook, G., Rothschild, D. and Schudson, M., 2018. The science of fake news. Science, 359(6380), pp.1094-1096.
Setiawan, R., Ponnam, V.S., Sengan, S., Anam, M., Subbiah, C., Phasinam, K., Vairaven, M. and Ponnusamy, S., 2022. Certain investigation of fake news detection from facebook and twitter using artificial intelligence approach. Wireless Personal Communications, pp.1-26.
Newman, N., Fletcher, R., Robertson, C.T., Ross Arguedas, A., and Nielsen, R.K., 2024. Reuters Institute digital news report 2024. Reuters Institute for the study of Journalism.
Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu, Y., Feng, J., Xiang, T., Torr, P.H. and Zhang, L., 2021. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6881-6890).
Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu, Y., Feng, J., Xiang, T., Torr, P.H. and Zhang, L., 2021. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6881-6890).
Graves, A., 2013. Generating Sequences with Recurrent Neural Networks. arXiv preprint arXiv.0850.
Hochreiter, S. and Schmidhuber, J., 1997. Long Short-Term Memory. Neural Computation, 9(8), pp.1735-1780.
Landolt, S., Wambsganß, T. and Söllner, M., 2021. A taxonomy for deep learning in natural language processing. In: Proceedings of the 54th Hawaii International Conference on System Sciences (HICSS). [online] Alexandria.unisg.ch. Available at: https://www.alexandria.unisg.ch/bitstreams/1c0aad38-2ed6-4963-97d5-ee3bb9e4cde5/download [Accessed 6 April 2025].
Schlosser, T., Friedrich, M., Meyer, T. and Kowerko, D., 2024. A consolidated overview of evaluation and performance metrics for machine learning and computer vision. Tobias Schlosser, Michael Friedrich, Trixy Meyer, and Danny Kowerko–Junior Professorship of Media Computing, Chemnitz University of Technology, 9107.
Acknowledgements
I gratefully acknowledge my supervisor, Abubakar Aliyu, for his exceptional mentorship and insightful guidance, which were instrumental to this research at Teesside university. I am deeply thankful to my family, friends, colleagues and peers for their unwavering support, constructive feedback and encouragement throughout this project. I also appreciate the contributions of the open-source community particularly the developers of TensorFlow, PyTorch and Hugging Face and Kaggle for providing essential frameworks and datasets.