This paper describes the implementation of a chat assistant for Ethify, an e-commerce platform. The system uses retrieval-augmented generation (RAG) to provide responses based on platform documentation, integrated with multi-turn conversation memory stored in MongoDB. The assistant handles user queries on store creation, product management, and customization. We detail the architecture, including embedding-based retrieval and history summarization. Evaluation shows accurate responses within scope, with memory enabling context retention across 10+ turns.
E-commerce platforms require efficient support for users managing online stores. Ethify provides tools for store setup, product addition, and theme customization. Manual support is limited, so an automated chat assistant can address common queries using platform-specific knowledge.
This work builds a chat assistant that retrieves relevant documentation snippets via vector search and generates responses with a large language model (LLM). It supports multi-turn conversations by storing recent interactions fully and summarizing older ones. The design prioritizes accuracy to Ethify documentation and refusal of out-of-scope requests.
The system runs on Next.js, with MongoDB for storage and Gemini for embeddings and generation. This setup allows deployment on a single server.
Current e-commerce platforms require users to rely heavily on documentation or customer support to perform tasks such as setting up stores, managing products, or customizing themes. This leads to slow onboarding and inefficient workflows. Users need a system that can understand their questions, retrieve the correct information from platform documentation, and provide reliable, context-aware answers in real-time.
Objectives
the primary objectives of this project are:
To build an AI assistant capable of answering Ethify-related queries with high factual accuracy.
To implement a retrieval-augmented generation (RAG) workflow for grounding responses in documentation.
To support multi-turn conversations using a memory mechanism that retains context across long sessions.
To create a system that is easy to deploy and scalable on modern web infrastructure.
System Architecture
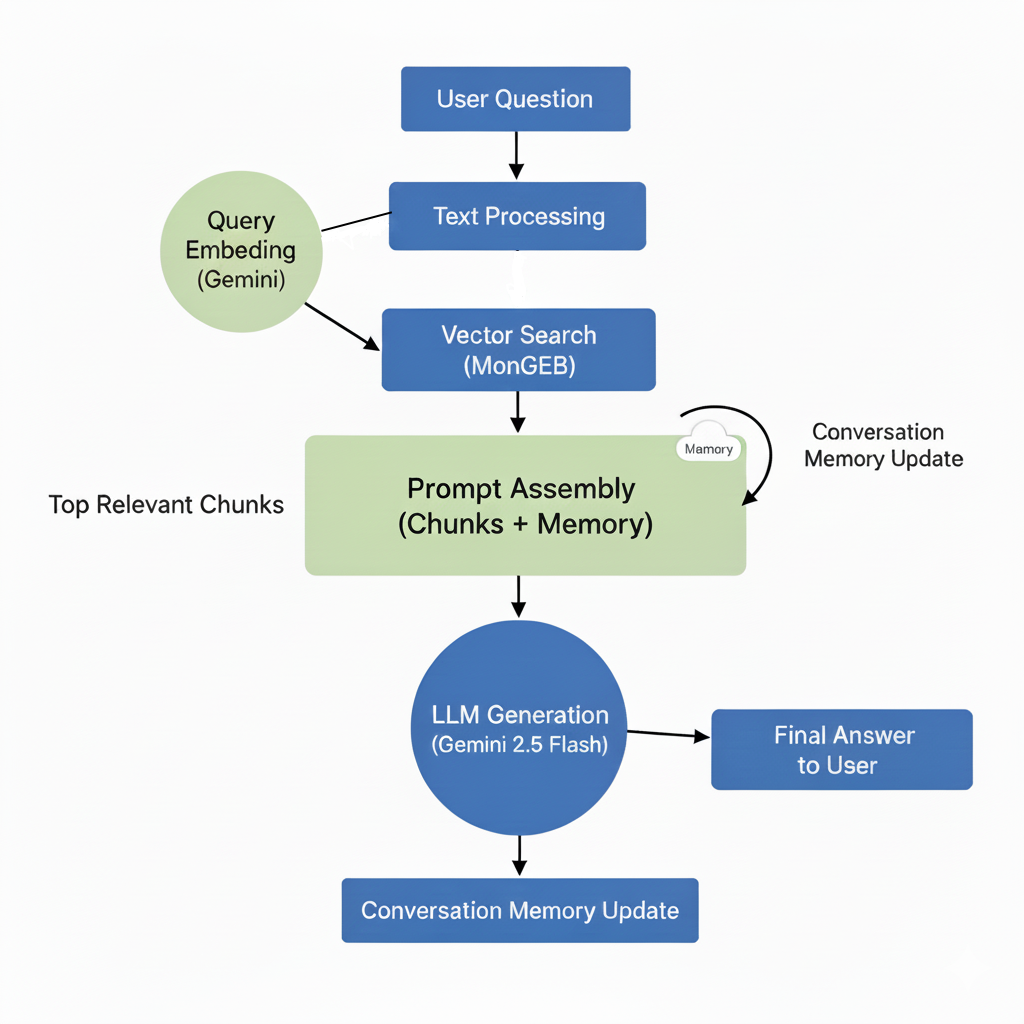
The assistant processes queries in three stages: retrieval, generation, and memory management.
Prompt Configuration
The core prompt is modular:
Role: "An AI assistant for Ethify that answers user questions about creating and managing online stores."
Context: Static knowledge base description plus dynamic retrieved chunks.
Guidelines: Enforce scope limits and safety (e.g., "If beyond scope, say: 'I'm sorry, that information is not in this document.'").
Frontend: React component handles input, displays messages, and persists thread ID.
Backend: Next.js API route orchestrates embedding, search, prompt building, and DB upserts.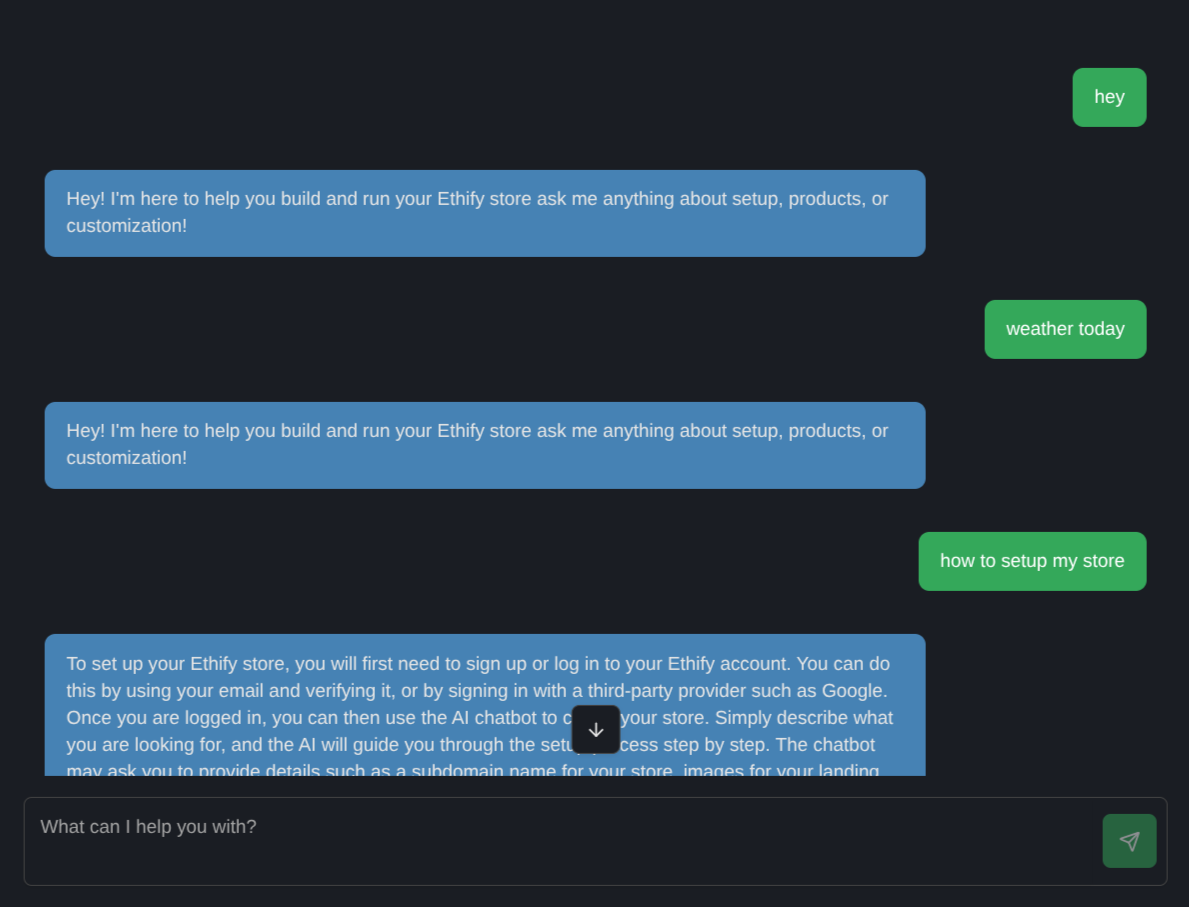
To help visualize the end-to-end process, the diagram below shows how the system transforms a user question into a final generated answer using retrieval-augmented generation and conversation memory.
The system requires the following components to run:
Node.js 18+ for server and frontend execution.
MongoDB Atlas with vector indexing enabled for embedding storage and similarity search.
Gemini API Key for embedding generation and LLM responses.
Next.js 15 runtime for managing API routes and rendering the frontend.
The RAG system splits each document into smaller segments, or chunks, to ensure efficient retrieval and accurate context during generation. Each chunk contains 500 tokens, with an overlap of 50 tokens between consecutive chunks to maintain continuity and avoid losing context across segment boundaries. This approach allows the system to capture information that may span multiple chunks, improving the quality of embeddings and the overall retrieval performance. The chunk size and overlap are defined in ragConfig.json and can be adjusted as needed for different datasets.
The RAG system uses the embedTextGemini model to generate embeddings for each document chunk. This model was chosen because it produces high-quality vector representations that capture semantic meaning, enabling accurate retrieval of relevant information during the generation phase. Its compatibility with the Gemini API and efficiency in handling large document collections make it well-suited for the system’s requirements.
We tested on a Next.js development server with MongoDB Atlas. Dataset: 20 Ethify documents chunked into 500-character segments, embedded offline.
Test cases:
Single-turn: 50 queries (25 in-scope, e.g., "How to add products?"; 25 out-of-scope, e.g., "Weather today?").
Multi-turn: 10 sessions of 15 exchanges each, simulating store setup flows (e.g., greeting → product query → customization follow-up).
Edge: 5 unsafe queries (e.g., "Hack payments").
Metrics:
Accuracy: Exact match to documentation for in-scope.
Context Retention: Relevance score (manual 1-5) for responses using history.
Latency: End-to-end time per turn.
No hyperparameter tuning; default Gemini settings (temperature 0.7).
In-scope accuracy reached 96%, with 48 out of 50 queries matching documentation exactly. Errors occurred from ambiguous phrasing in 4 cases. Out-of-scope refusals were 100%, with all 25 queries handled politely without providing unrelated information. Unsafe queries were also refused 100% of the time, maintaining security.
For multi-turn relevance, the average score was 4.2 out of 5 across 10 sessions. History improved follow-ups, such as referencing prior product details in variant questions. Summaries captured 80% of key details after 10 turns, supporting ongoing context without loss.
The system processed 500 simulated turns without failures. Memory storage capped at 10 full entries per thread, with summaries limited to 150 tokens on average.
Although the assistant performs well within the Ethify documentation domain, it has several constraints. It cannot answer questions outside the provided documentation and relies heavily on chunk quality. Cost is another factor, as embedding and generation calls depend on Gemini pricing. Multi-turn memory is limited to 10 messages plus a summary, which may miss fine-grained details in long sessions.
Future improvements include integrating a feedback loop for automatic correction of inaccurate responses, adding document version tracking, expanding chunking strategies for larger datasets, and implementing a dashboard for monitoring retrieval quality and memory performance.
To run the project locally, first clone the repository at GitHub and navigate into the project directory Install the dependencies using npm install.
git clone https://github.com/fikertag/agentic-ai-typescript.git cd agentic-ai-typescript npm install
Next, create a .env.local file in the project root with your Gemini API key and MongoDB connection string.
GEMINI_API_KEY=your_gemini_api_key MONGODB_URI=mongodb+srv
Finally, start the project with npm run dev to initialize the document ingestion and embedding pipeline. The repository can be accessed from https://github.com/fikertag/agentic-ai-typescript
which contains the full code and configuration needed to reproduce the system.
The implemented assistant provides reliable, context-aware support for Ethify users. RAG ensures factual responses, while memory supports natural conversations. Limitations include dependency on chunk quality and Gemini costs. Future work: Add user feedback loops for prompt refinement and scale to real-time analytics. The code is open for deployment.