
ResumeLens is an AI-powered resume analysis system designed to help candidates understand how well their resume aligns with a target role and what they should improve next. The platform accepts resume content as raw text or uploaded files, optionally accepts a job description as text or URL, and generates a structured candidate profile, gap analysis, rewritten resume bullets, ATS keyword recommendations, interview questions, and an action plan.
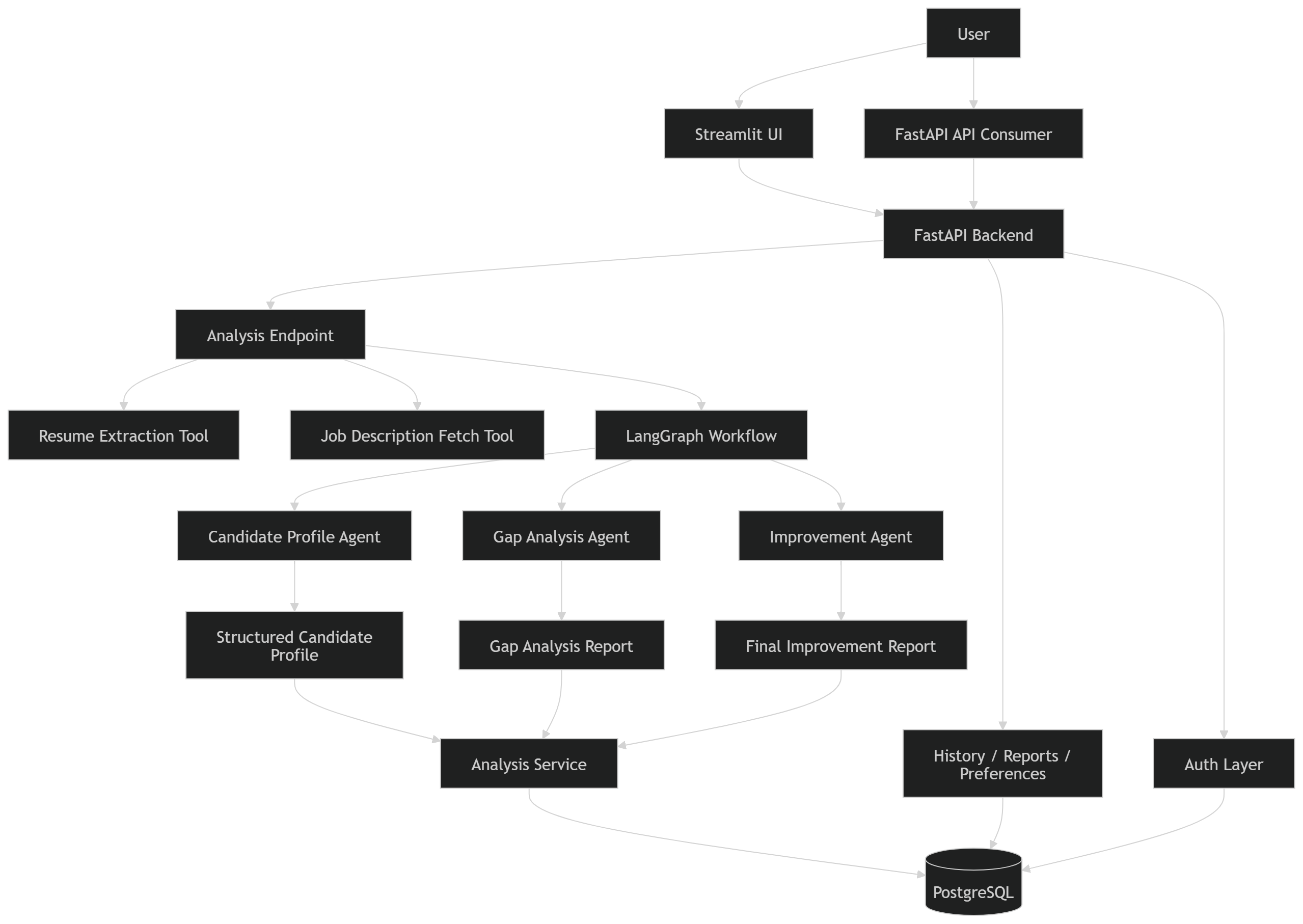
The system is built with a FastAPI backend, LangGraph-based multi-step orchestration, PostgreSQL persistence, and a Streamlit interface for interactive usage. Rather than behaving like a one-shot prompt wrapper, ResumeLens is designed as a practical AI application with authentication, report history, preference memory, structured outputs, and production-oriented backend patterns.
Its main value is not simply producing AI-generated text, but turning resume improvement into a repeatable, explainable workflow. ResumeLens gives users both diagnosis and action: what is strong, what is missing, what should be rewritten, and how to become a better fit for a given role.
ResumeLens is not trained on a custom large-scale labeled dataset in the traditional machine learning sense. Instead, it operates on user-provided runtime inputs plus structured intermediate artifacts generated during analysis.
.txt.pdf.docxFrom the input data, the system generates:
The data is semi-structured and user-specific. Typical resume content includes:
Typical job description content includes:
The quality of system output depends heavily on:
User resumes and reports can contain personal and sensitive career information. In production use, privacy, access control, retention policy, and deployment security should be treated as high-priority concerns.
Most resume feedback tools fail in one of two ways: they are either too generic to be useful, or they produce polished text without clearly explaining what is actually wrong with the original resume.
ResumeLens was created to solve a more practical problem:
How can we turn resume review into a structured, repeatable, AI-assisted workflow that gives both explanation and improvement?
The motivation behind ResumeLens includes:
ResumeLens exists because most job seekers do not only need better wording. They need:
https://github.com/SimbaMunatsi/resume-lens
ResumeLens uses a multi-stage AI workflow rather than a single prompt.
ResumeLens is designed as a layered AI application.
- Streamlit UI for user interaction
- FastAPI backend for validation, auth, orchestration, and API responses
- Tool layer for resume extraction, text cleaning, job fetching, and skill normalization
- Agent workflow for profile extraction, gap analysis, and improvement generation
- Service layer for assembling and persisting outputs
- PostgreSQL database for users, analyses, reports, and preferences
Convert raw resume text into a structured candidate profile.
Inputs
- raw resume text
Outputs
- candidate name
- email / links if present
- experience summary
- education
- skills
- projects
- certifications
- inferred seniority
- missing sections
- structured JSON profile
This agent creates the normalized state the rest of the workflow needs.
Compare the structured resume against the target job description.
Inputs
- candidate profile
- job description text
Outputs
- match score
- matched skills
- missing skills
- weak alignment areas
- high-priority gaps
- strengths relevant to the role
- ATS keyword gaps
This is the decision engine of the project.
Turn analysis into practical resume improvements.
Inputs
- candidate profile
- job match report
- user preferences from memory
Outputs
- rewritten bullets
- missing keyword suggestions
- section-level recommendations
- final action plan
- tailored interview questions
This makes the system actually useful, not just analytical.
Purpose: Extracts usable text from the resume input.
What it does:
The rest of the pipeline cannot work on raw files. This tool is what turns a resume document into analysis-ready text.
Purpose: Retrieves job description text from a public job URL.
What it does:
It allows the user to analyze their resume against a live job posting instead of manually copying the description.
Purpose: Cleans and normalizes raw text before analysis.
What it does:
Even good extraction can leave messy text behind. This tool improves consistency before the candidate profile and gap analysis stages.
Purpose: Standardizes skill names into a consistent format.
What it does:
Without normalization, the system may treat equivalent skills as different. This tool improves match accuracy during gap analysis and scoring.
Resume Input
-> Resume Extraction Tool
-> Text Cleaning
-> Candidate Profile Agent
-> Job Description Input / Job Fetch Tool
-> Gap Analysis Agent
-> Improvement Agent
-> Final Report Assembly
-> Save Analysis + Report + Preferences
Resume input
The user either: pastes resume text or uploads a TXT, PDF, or DOCX file
Resume extraction
The extraction layer converts uploaded documents into normalized text.
Text cleaning
The text cleaner removes noise and standardizes formatting.
Candidate profile extraction
The first agent converts the cleaned resume into a structured profile.
Job description acquisition
The system either: uses pasted job description text or fetches and parses a public job URL
Gap analysis
The second agent compares the candidate profile with job expectations, calculates match signals, and identifies missing or weak areas.
Improvement generation
The third agent produces resume rewrites, ATS keyword guidance, role-fit feedback, interview questions, and an action plan.
Report assembly and storage
The final response is returned to the user and persisted for history, review, and future comparison.
Below is a representative example of the analysis endpoint pattern used in ResumeLens. It shows validation, extraction, and structured response assembly:
@router.post("/run", response_model=ResumeExtractionResponse) async def run_analysis( current_user: User = Depends(get_current_user), resume_file: UploadFile | None = File(default=None), resume_text: str | None = Form(default=None), job_description_text: str | None = Form(default=None), job_url: str | None = Form(default=None), ) -> ResumeExtractionResponse: if resume_file is None and not resume_text: raise HTTPException(status_code=400, detail="Provide either resume_file or resume_text.") if resume_file is not None and resume_text: raise HTTPException(status_code=400, detail="Provide only one of resume_file or resume_text.") if job_description_text and job_url: raise HTTPException(status_code=400, detail="Provide only one of job_description_text or job_url.") # Resume extraction and cleaning happen here # Job description fetch/cleaning happens here # Candidate profile, gap analysis, and final report generation follow return ResumeExtractionResponse(...)
This code reflects important engineering decisions:
git clone https://github.com/SimbaMunatsi/resume-lens.git cd resume-lens
python -m venv venv venv\Scripts\activate
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
Create a .env file and populate the required values.
Example:
APP_NAME=resume-lens
APP_VERSION=0.1.0
API_V1_PREFIX=/api/v1
DEBUG=True
POSTGRES_USER=postgres
POSTGRES_PASSWORD=postgres
POSTGRES_SERVER=localhost
POSTGRES_PORT=5432
POSTGRES_DB=resume_lens
DATABASE_URL=postgresql://postgres:your_password@localhost:5432/resume_lens
LOG_LEVEL=INFO
SECRET_KEY=your secret key here
ALGORITHM=HS256
ACCESS_TOKEN_EXPIRE_MINUTES=60
MAX_UPLOAD_SIZE_BYTES=2097152
ALLOWED_RESUME_EXTENSIONS=.pdf,.docx,.txt
JOB_FETCH_TIMEOUT_SECONDS=10
MAX_JOB_DESCRIPTION_CHARS=12000
OPENAI_API_KEY=your key here
OPENAI_MODEL=gpt-4.1-mini
alembic upgrade head
uvicorn app.main:app --reload
streamlit run streamlit_app.py
Resume includes Python, FastAPI, PostgreSQL
Job requires Python, FastAPI, PostgreSQL, Docker
ResumeLens detects:
ResumeLens includes basic production-oriented observability patterns.
- structured candidate profile
- gap analysis score and findings
- rewritten resume bullets
- ATS keyword suggestions
- role-fit feedback
- interview questions
- action plan
- historical improvement comparison

ResumeLens produces outputs that are both diagnostic and actionable.

The strongest result is not just the match score. It is the combination of:
- score
- explanation
- weaknesses
- rewritten output
- next steps

This makes the system useful for iterative resume improvement instead of one-time analysis.

ResumeLens currently relies on a combination of:
- unit tests
- integration tests
- deterministic validation logic
- schema-constrained outputs
- manual qualitative inspection of generated reports
Because resume quality is partially subjective, evaluation must balance:
- structural correctness
- role alignment
- usefulness
- factuality
- actionability
Output quality depends on input quality
Weak or incomplete resumes will limit profile accuracy and downstream recommendations.
Public job URL parsing is imperfect
Some job sites have noisy HTML, dynamic rendering, or anti-scraping behavior.
Resume truthfulness is assumed
The system can improve how a candidate presents experience, but it cannot verify whether claims are true.
Match scoring is useful but not absolute
A resume score is a decision aid, not a hiring prediction model.
Industry/domain nuance is limited
Specialized sectors may require stronger domain-aware heuristics or role-specific prompts.
LLM output variability still exists
Even with structured schemas, some variation in phrasing and recommendation style is expected.
This is where ResumeLens is strongest.
ResumeLens is designed for interactive local usage, not batch-scale processing.
ResumeLens is currently designed for:
Creator: Victor Simbarashe Munatsi
Github
LinkedIn
vsmunatsi@gmail.com
ResumeLens is released under the MIT License.