The aim of this project is to leverage the use of RAG for answering questions asked about research articles. It serves as your personal research assistant when you need to get needed information when trying to get quick information about research papers.
By used LangChain, Huggingface and Active Loop's Deeplake as by vector store. Users could ask questions and receive relevant answers based on the information already stored in the vector database store.
AIM
Develop a research assistant capable of answering researcher's questions given that the information is on the vector store
OBJECTIVES
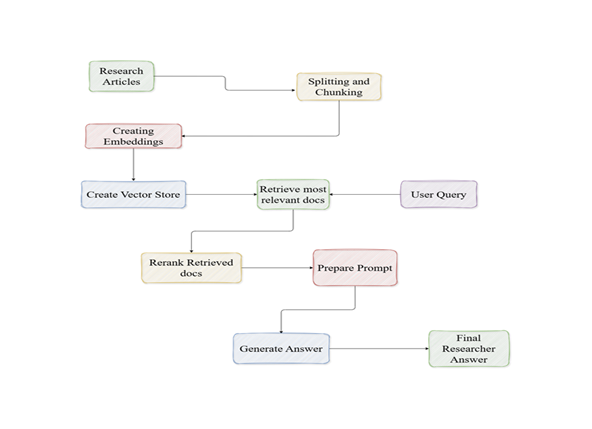
The following takes place in the vector_database_creation.py file;
Data Ingestion: PDF files are first ingested using LangChain's PyPDFLoader, which makes data ingestion of PDFs easier.
Text Splitting and Chunking: Using LangChain's RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=700), all documents were further broken down into more refined sizable chunks for relevant document searching and retrieval.
Creating Embeddings: The chunked documents were converted to numerical values; embeddings using Cohere Embeddings. The chosen embedding model used from Cohere was the embed-english-v3.0, which has a dimension size of 1024.
Creating Vector Store: Using Active Loop's deeplake vector store, the created embeddings from the documents were stored in cloud.
The following takes place in the rag_research_assistant_main.py file;
User Query and Retrieved Documents: The user query is taken in by the application and the retrieved documents collected from the vector store
Rerank Retrieved docs: The retrieved documents are reranked using cohere reranker via LangChain thereby making sure the most relevant document is taken into account before being fed into the prompt for further organisation of ideas and answer by the LLM.
Prepare Prompt, Generate Final Answer : The crafted prompt informs the model to take the retrieved documents to be well structed answer which makes sense and generates the final answers to the user's question.
Below is the deliverables of the project;
img: This contains the project flowchart process of the research assistant
notebook: This contains the example/jupyter notebook file which shows the experimentation of the research assistant.
README.md: This file, providing an overview and instructions for the project.
It also gives straight forward and easy to follow instructions on replicating the project.
environment.yml: This contains the needed requirements of the needed packages for the project to work and for reproducibility.
prompts.md: This contains some example prompts that could be asked to the research assistant
research_articles.zip: This contains the knowledge base (documents) for creating your vector store embeddings from.
NB: You can add your own documents too
vector_database_creation.py: This helps in the creation of your vector store
rag_research_assistant_main.py: The main driver of the application, takes user's questions and produces the final generated answers.
When vector_database_creation.py is ran, the following output is given when all criteria are met
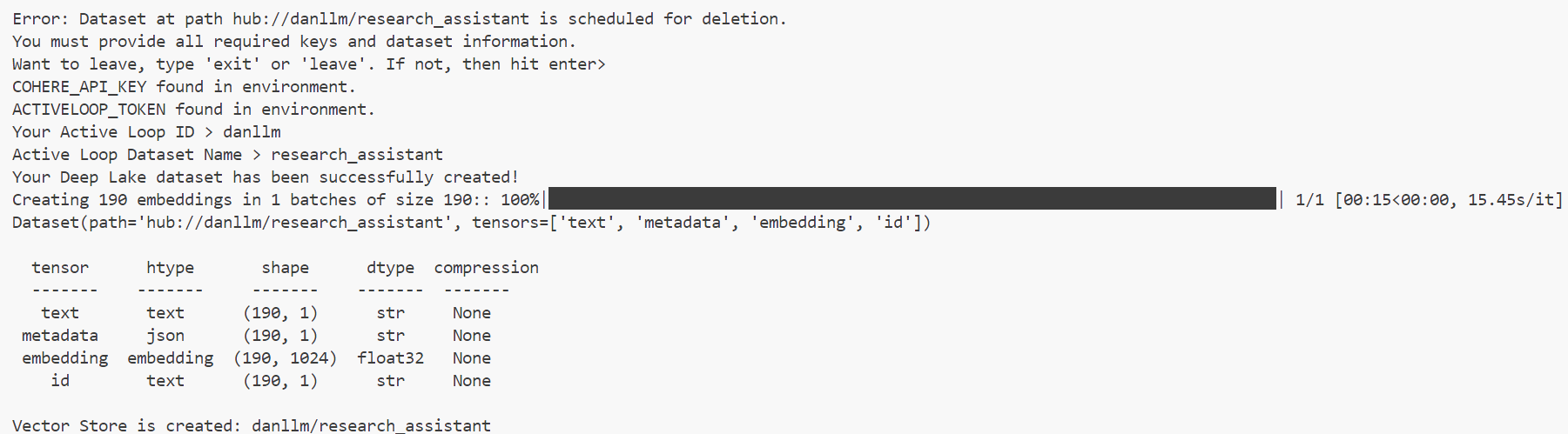
When `rag_research_assistant_main.py is ran, the following example output is given
Question
Why did Mehedi Tajrian analyse child development and what was the best classifier?
Answer
Mehedi Tajrian analyzed child development due to:
- The rapid spread of misinformation online complicating accurate decision-making, especially for parents.
- The lack of research into distinguishing myths and facts about child development using text mining and classification models.
- The potential risks of inaccurate information on child treatment and development.
- To provide valuable insights for making informed decisions, thus aiding parents in handling misinformation.
-To shed light on myths around child development and aid in making informed decisions. These include several stages, including data pre-processing through text mining techniques, and analysis with six traditional machine learning classifiers and one deep learning model using two feature extraction techniques.
-The best performing classifier is the Logistic Regression (LR) model with a 90% accuracy rate. The model also stands out for its speed and efficiency, with very low testing times per statement, and demonstrated robust performance on both k-fold and leave-one-out cross-validation.
Source(s):
- Title: Analysis of child development facts and myths using text mining techniques and classification models, Page: 1
- Title: Analysis of child development facts and myths using text mining techniques and classification models, Page: 15
- Title: Analysis of child development facts and myths using text mining techniques and classification models, Page: 2
This project is licensed under the MIT License. See the LICENSE file for more details.